User login
CCJM delivers practical clinical articles relevant to internists, cardiologists, endocrinologists, and other specialists, all written by known experts.
Copyright © 2019 Cleveland Clinic. All rights reserved. The information provided is for educational purposes only. Use of this website is subject to the disclaimer and privacy policy.
gambling
compulsive behaviors
ammunition
assault rifle
black jack
Boko Haram
bondage
child abuse
cocaine
Daech
drug paraphernalia
explosion
gun
human trafficking
ISIL
ISIS
Islamic caliphate
Islamic state
mixed martial arts
MMA
molestation
national rifle association
NRA
nsfw
pedophile
pedophilia
poker
porn
pornography
psychedelic drug
recreational drug
sex slave rings
slot machine
terrorism
terrorist
Texas hold 'em
UFC
substance abuse
abuseed
abuseer
abusees
abuseing
abusely
abuses
aeolus
aeolused
aeoluser
aeoluses
aeolusing
aeolusly
aeoluss
ahole
aholeed
aholeer
aholees
aholeing
aholely
aholes
alcohol
alcoholed
alcoholer
alcoholes
alcoholing
alcoholly
alcohols
allman
allmaned
allmaner
allmanes
allmaning
allmanly
allmans
alted
altes
alting
altly
alts
analed
analer
anales
analing
anally
analprobe
analprobeed
analprobeer
analprobees
analprobeing
analprobely
analprobes
anals
anilingus
anilingused
anilinguser
anilinguses
anilingusing
anilingusly
anilinguss
anus
anused
anuser
anuses
anusing
anusly
anuss
areola
areolaed
areolaer
areolaes
areolaing
areolaly
areolas
areole
areoleed
areoleer
areolees
areoleing
areolely
areoles
arian
arianed
arianer
arianes
arianing
arianly
arians
aryan
aryaned
aryaner
aryanes
aryaning
aryanly
aryans
asiaed
asiaer
asiaes
asiaing
asialy
asias
ass
ass hole
ass lick
ass licked
ass licker
ass lickes
ass licking
ass lickly
ass licks
assbang
assbanged
assbangeded
assbangeder
assbangedes
assbangeding
assbangedly
assbangeds
assbanger
assbanges
assbanging
assbangly
assbangs
assbangsed
assbangser
assbangses
assbangsing
assbangsly
assbangss
assed
asser
asses
assesed
asseser
asseses
assesing
assesly
assess
assfuck
assfucked
assfucker
assfuckered
assfuckerer
assfuckeres
assfuckering
assfuckerly
assfuckers
assfuckes
assfucking
assfuckly
assfucks
asshat
asshated
asshater
asshates
asshating
asshatly
asshats
assholeed
assholeer
assholees
assholeing
assholely
assholes
assholesed
assholeser
assholeses
assholesing
assholesly
assholess
assing
assly
assmaster
assmastered
assmasterer
assmasteres
assmastering
assmasterly
assmasters
assmunch
assmunched
assmuncher
assmunches
assmunching
assmunchly
assmunchs
asss
asswipe
asswipeed
asswipeer
asswipees
asswipeing
asswipely
asswipes
asswipesed
asswipeser
asswipeses
asswipesing
asswipesly
asswipess
azz
azzed
azzer
azzes
azzing
azzly
azzs
babeed
babeer
babees
babeing
babely
babes
babesed
babeser
babeses
babesing
babesly
babess
ballsac
ballsaced
ballsacer
ballsaces
ballsacing
ballsack
ballsacked
ballsacker
ballsackes
ballsacking
ballsackly
ballsacks
ballsacly
ballsacs
ballsed
ballser
ballses
ballsing
ballsly
ballss
barf
barfed
barfer
barfes
barfing
barfly
barfs
bastard
bastarded
bastarder
bastardes
bastarding
bastardly
bastards
bastardsed
bastardser
bastardses
bastardsing
bastardsly
bastardss
bawdy
bawdyed
bawdyer
bawdyes
bawdying
bawdyly
bawdys
beaner
beanered
beanerer
beaneres
beanering
beanerly
beaners
beardedclam
beardedclamed
beardedclamer
beardedclames
beardedclaming
beardedclamly
beardedclams
beastiality
beastialityed
beastialityer
beastialityes
beastialitying
beastialityly
beastialitys
beatch
beatched
beatcher
beatches
beatching
beatchly
beatchs
beater
beatered
beaterer
beateres
beatering
beaterly
beaters
beered
beerer
beeres
beering
beerly
beeyotch
beeyotched
beeyotcher
beeyotches
beeyotching
beeyotchly
beeyotchs
beotch
beotched
beotcher
beotches
beotching
beotchly
beotchs
biatch
biatched
biatcher
biatches
biatching
biatchly
biatchs
big tits
big titsed
big titser
big titses
big titsing
big titsly
big titss
bigtits
bigtitsed
bigtitser
bigtitses
bigtitsing
bigtitsly
bigtitss
bimbo
bimboed
bimboer
bimboes
bimboing
bimboly
bimbos
bisexualed
bisexualer
bisexuales
bisexualing
bisexually
bisexuals
bitch
bitched
bitcheded
bitcheder
bitchedes
bitcheding
bitchedly
bitcheds
bitcher
bitches
bitchesed
bitcheser
bitcheses
bitchesing
bitchesly
bitchess
bitching
bitchly
bitchs
bitchy
bitchyed
bitchyer
bitchyes
bitchying
bitchyly
bitchys
bleached
bleacher
bleaches
bleaching
bleachly
bleachs
blow job
blow jobed
blow jober
blow jobes
blow jobing
blow jobly
blow jobs
blowed
blower
blowes
blowing
blowjob
blowjobed
blowjober
blowjobes
blowjobing
blowjobly
blowjobs
blowjobsed
blowjobser
blowjobses
blowjobsing
blowjobsly
blowjobss
blowly
blows
boink
boinked
boinker
boinkes
boinking
boinkly
boinks
bollock
bollocked
bollocker
bollockes
bollocking
bollockly
bollocks
bollocksed
bollockser
bollockses
bollocksing
bollocksly
bollockss
bollok
bolloked
bolloker
bollokes
bolloking
bollokly
bolloks
boner
bonered
bonerer
boneres
bonering
bonerly
boners
bonersed
bonerser
bonerses
bonersing
bonersly
bonerss
bong
bonged
bonger
bonges
bonging
bongly
bongs
boob
boobed
boober
boobes
boobies
boobiesed
boobieser
boobieses
boobiesing
boobiesly
boobiess
boobing
boobly
boobs
boobsed
boobser
boobses
boobsing
boobsly
boobss
booby
boobyed
boobyer
boobyes
boobying
boobyly
boobys
booger
boogered
boogerer
boogeres
boogering
boogerly
boogers
bookie
bookieed
bookieer
bookiees
bookieing
bookiely
bookies
bootee
booteeed
booteeer
booteees
booteeing
booteely
bootees
bootie
bootieed
bootieer
bootiees
bootieing
bootiely
booties
booty
bootyed
bootyer
bootyes
bootying
bootyly
bootys
boozeed
boozeer
boozees
boozeing
boozely
boozer
boozered
boozerer
boozeres
boozering
boozerly
boozers
boozes
boozy
boozyed
boozyer
boozyes
boozying
boozyly
boozys
bosomed
bosomer
bosomes
bosoming
bosomly
bosoms
bosomy
bosomyed
bosomyer
bosomyes
bosomying
bosomyly
bosomys
bugger
buggered
buggerer
buggeres
buggering
buggerly
buggers
bukkake
bukkakeed
bukkakeer
bukkakees
bukkakeing
bukkakely
bukkakes
bull shit
bull shited
bull shiter
bull shites
bull shiting
bull shitly
bull shits
bullshit
bullshited
bullshiter
bullshites
bullshiting
bullshitly
bullshits
bullshitsed
bullshitser
bullshitses
bullshitsing
bullshitsly
bullshitss
bullshitted
bullshitteded
bullshitteder
bullshittedes
bullshitteding
bullshittedly
bullshitteds
bullturds
bullturdsed
bullturdser
bullturdses
bullturdsing
bullturdsly
bullturdss
bung
bunged
bunger
bunges
bunging
bungly
bungs
busty
bustyed
bustyer
bustyes
bustying
bustyly
bustys
butt
butt fuck
butt fucked
butt fucker
butt fuckes
butt fucking
butt fuckly
butt fucks
butted
buttes
buttfuck
buttfucked
buttfucker
buttfuckered
buttfuckerer
buttfuckeres
buttfuckering
buttfuckerly
buttfuckers
buttfuckes
buttfucking
buttfuckly
buttfucks
butting
buttly
buttplug
buttpluged
buttpluger
buttpluges
buttpluging
buttplugly
buttplugs
butts
caca
cacaed
cacaer
cacaes
cacaing
cacaly
cacas
cahone
cahoneed
cahoneer
cahonees
cahoneing
cahonely
cahones
cameltoe
cameltoeed
cameltoeer
cameltoees
cameltoeing
cameltoely
cameltoes
carpetmuncher
carpetmunchered
carpetmuncherer
carpetmuncheres
carpetmunchering
carpetmuncherly
carpetmunchers
cawk
cawked
cawker
cawkes
cawking
cawkly
cawks
chinc
chinced
chincer
chinces
chincing
chincly
chincs
chincsed
chincser
chincses
chincsing
chincsly
chincss
chink
chinked
chinker
chinkes
chinking
chinkly
chinks
chode
chodeed
chodeer
chodees
chodeing
chodely
chodes
chodesed
chodeser
chodeses
chodesing
chodesly
chodess
clit
clited
cliter
clites
cliting
clitly
clitoris
clitorised
clitoriser
clitorises
clitorising
clitorisly
clitoriss
clitorus
clitorused
clitoruser
clitoruses
clitorusing
clitorusly
clitoruss
clits
clitsed
clitser
clitses
clitsing
clitsly
clitss
clitty
clittyed
clittyer
clittyes
clittying
clittyly
clittys
cocain
cocaine
cocained
cocaineed
cocaineer
cocainees
cocaineing
cocainely
cocainer
cocaines
cocaining
cocainly
cocains
cock
cock sucker
cock suckered
cock suckerer
cock suckeres
cock suckering
cock suckerly
cock suckers
cockblock
cockblocked
cockblocker
cockblockes
cockblocking
cockblockly
cockblocks
cocked
cocker
cockes
cockholster
cockholstered
cockholsterer
cockholsteres
cockholstering
cockholsterly
cockholsters
cocking
cockknocker
cockknockered
cockknockerer
cockknockeres
cockknockering
cockknockerly
cockknockers
cockly
cocks
cocksed
cockser
cockses
cocksing
cocksly
cocksmoker
cocksmokered
cocksmokerer
cocksmokeres
cocksmokering
cocksmokerly
cocksmokers
cockss
cocksucker
cocksuckered
cocksuckerer
cocksuckeres
cocksuckering
cocksuckerly
cocksuckers
coital
coitaled
coitaler
coitales
coitaling
coitally
coitals
commie
commieed
commieer
commiees
commieing
commiely
commies
condomed
condomer
condomes
condoming
condomly
condoms
coon
cooned
cooner
coones
cooning
coonly
coons
coonsed
coonser
coonses
coonsing
coonsly
coonss
corksucker
corksuckered
corksuckerer
corksuckeres
corksuckering
corksuckerly
corksuckers
cracked
crackwhore
crackwhoreed
crackwhoreer
crackwhorees
crackwhoreing
crackwhorely
crackwhores
crap
craped
craper
crapes
craping
craply
crappy
crappyed
crappyer
crappyes
crappying
crappyly
crappys
cum
cumed
cumer
cumes
cuming
cumly
cummin
cummined
cumminer
cummines
cumming
cumminged
cumminger
cumminges
cumminging
cummingly
cummings
cummining
cumminly
cummins
cums
cumshot
cumshoted
cumshoter
cumshotes
cumshoting
cumshotly
cumshots
cumshotsed
cumshotser
cumshotses
cumshotsing
cumshotsly
cumshotss
cumslut
cumsluted
cumsluter
cumslutes
cumsluting
cumslutly
cumsluts
cumstain
cumstained
cumstainer
cumstaines
cumstaining
cumstainly
cumstains
cunilingus
cunilingused
cunilinguser
cunilinguses
cunilingusing
cunilingusly
cunilinguss
cunnilingus
cunnilingused
cunnilinguser
cunnilinguses
cunnilingusing
cunnilingusly
cunnilinguss
cunny
cunnyed
cunnyer
cunnyes
cunnying
cunnyly
cunnys
cunt
cunted
cunter
cuntes
cuntface
cuntfaceed
cuntfaceer
cuntfacees
cuntfaceing
cuntfacely
cuntfaces
cunthunter
cunthuntered
cunthunterer
cunthunteres
cunthuntering
cunthunterly
cunthunters
cunting
cuntlick
cuntlicked
cuntlicker
cuntlickered
cuntlickerer
cuntlickeres
cuntlickering
cuntlickerly
cuntlickers
cuntlickes
cuntlicking
cuntlickly
cuntlicks
cuntly
cunts
cuntsed
cuntser
cuntses
cuntsing
cuntsly
cuntss
dago
dagoed
dagoer
dagoes
dagoing
dagoly
dagos
dagosed
dagoser
dagoses
dagosing
dagosly
dagoss
dammit
dammited
dammiter
dammites
dammiting
dammitly
dammits
damn
damned
damneded
damneder
damnedes
damneding
damnedly
damneds
damner
damnes
damning
damnit
damnited
damniter
damnites
damniting
damnitly
damnits
damnly
damns
dick
dickbag
dickbaged
dickbager
dickbages
dickbaging
dickbagly
dickbags
dickdipper
dickdippered
dickdipperer
dickdipperes
dickdippering
dickdipperly
dickdippers
dicked
dicker
dickes
dickface
dickfaceed
dickfaceer
dickfacees
dickfaceing
dickfacely
dickfaces
dickflipper
dickflippered
dickflipperer
dickflipperes
dickflippering
dickflipperly
dickflippers
dickhead
dickheaded
dickheader
dickheades
dickheading
dickheadly
dickheads
dickheadsed
dickheadser
dickheadses
dickheadsing
dickheadsly
dickheadss
dicking
dickish
dickished
dickisher
dickishes
dickishing
dickishly
dickishs
dickly
dickripper
dickrippered
dickripperer
dickripperes
dickrippering
dickripperly
dickrippers
dicks
dicksipper
dicksippered
dicksipperer
dicksipperes
dicksippering
dicksipperly
dicksippers
dickweed
dickweeded
dickweeder
dickweedes
dickweeding
dickweedly
dickweeds
dickwhipper
dickwhippered
dickwhipperer
dickwhipperes
dickwhippering
dickwhipperly
dickwhippers
dickzipper
dickzippered
dickzipperer
dickzipperes
dickzippering
dickzipperly
dickzippers
diddle
diddleed
diddleer
diddlees
diddleing
diddlely
diddles
dike
dikeed
dikeer
dikees
dikeing
dikely
dikes
dildo
dildoed
dildoer
dildoes
dildoing
dildoly
dildos
dildosed
dildoser
dildoses
dildosing
dildosly
dildoss
diligaf
diligafed
diligafer
diligafes
diligafing
diligafly
diligafs
dillweed
dillweeded
dillweeder
dillweedes
dillweeding
dillweedly
dillweeds
dimwit
dimwited
dimwiter
dimwites
dimwiting
dimwitly
dimwits
dingle
dingleed
dingleer
dinglees
dingleing
dinglely
dingles
dipship
dipshiped
dipshiper
dipshipes
dipshiping
dipshiply
dipships
dizzyed
dizzyer
dizzyes
dizzying
dizzyly
dizzys
doggiestyleed
doggiestyleer
doggiestylees
doggiestyleing
doggiestylely
doggiestyles
doggystyleed
doggystyleer
doggystylees
doggystyleing
doggystylely
doggystyles
dong
donged
donger
donges
donging
dongly
dongs
doofus
doofused
doofuser
doofuses
doofusing
doofusly
doofuss
doosh
dooshed
doosher
dooshes
dooshing
dooshly
dooshs
dopeyed
dopeyer
dopeyes
dopeying
dopeyly
dopeys
douchebag
douchebaged
douchebager
douchebages
douchebaging
douchebagly
douchebags
douchebagsed
douchebagser
douchebagses
douchebagsing
douchebagsly
douchebagss
doucheed
doucheer
douchees
doucheing
douchely
douches
douchey
doucheyed
doucheyer
doucheyes
doucheying
doucheyly
doucheys
drunk
drunked
drunker
drunkes
drunking
drunkly
drunks
dumass
dumassed
dumasser
dumasses
dumassing
dumassly
dumasss
dumbass
dumbassed
dumbasser
dumbasses
dumbassesed
dumbasseser
dumbasseses
dumbassesing
dumbassesly
dumbassess
dumbassing
dumbassly
dumbasss
dummy
dummyed
dummyer
dummyes
dummying
dummyly
dummys
dyke
dykeed
dykeer
dykees
dykeing
dykely
dykes
dykesed
dykeser
dykeses
dykesing
dykesly
dykess
erotic
eroticed
eroticer
erotices
eroticing
eroticly
erotics
extacy
extacyed
extacyer
extacyes
extacying
extacyly
extacys
extasy
extasyed
extasyer
extasyes
extasying
extasyly
extasys
fack
facked
facker
fackes
facking
fackly
facks
fag
faged
fager
fages
fagg
fagged
faggeded
faggeder
faggedes
faggeding
faggedly
faggeds
fagger
fagges
fagging
faggit
faggited
faggiter
faggites
faggiting
faggitly
faggits
faggly
faggot
faggoted
faggoter
faggotes
faggoting
faggotly
faggots
faggs
faging
fagly
fagot
fagoted
fagoter
fagotes
fagoting
fagotly
fagots
fags
fagsed
fagser
fagses
fagsing
fagsly
fagss
faig
faiged
faiger
faiges
faiging
faigly
faigs
faigt
faigted
faigter
faigtes
faigting
faigtly
faigts
fannybandit
fannybandited
fannybanditer
fannybandites
fannybanditing
fannybanditly
fannybandits
farted
farter
fartes
farting
fartknocker
fartknockered
fartknockerer
fartknockeres
fartknockering
fartknockerly
fartknockers
fartly
farts
felch
felched
felcher
felchered
felcherer
felcheres
felchering
felcherly
felchers
felches
felching
felchinged
felchinger
felchinges
felchinging
felchingly
felchings
felchly
felchs
fellate
fellateed
fellateer
fellatees
fellateing
fellately
fellates
fellatio
fellatioed
fellatioer
fellatioes
fellatioing
fellatioly
fellatios
feltch
feltched
feltcher
feltchered
feltcherer
feltcheres
feltchering
feltcherly
feltchers
feltches
feltching
feltchly
feltchs
feom
feomed
feomer
feomes
feoming
feomly
feoms
fisted
fisteded
fisteder
fistedes
fisteding
fistedly
fisteds
fisting
fistinged
fistinger
fistinges
fistinging
fistingly
fistings
fisty
fistyed
fistyer
fistyes
fistying
fistyly
fistys
floozy
floozyed
floozyer
floozyes
floozying
floozyly
floozys
foad
foaded
foader
foades
foading
foadly
foads
fondleed
fondleer
fondlees
fondleing
fondlely
fondles
foobar
foobared
foobarer
foobares
foobaring
foobarly
foobars
freex
freexed
freexer
freexes
freexing
freexly
freexs
frigg
frigga
friggaed
friggaer
friggaes
friggaing
friggaly
friggas
frigged
frigger
frigges
frigging
friggly
friggs
fubar
fubared
fubarer
fubares
fubaring
fubarly
fubars
fuck
fuckass
fuckassed
fuckasser
fuckasses
fuckassing
fuckassly
fuckasss
fucked
fuckeded
fuckeder
fuckedes
fuckeding
fuckedly
fuckeds
fucker
fuckered
fuckerer
fuckeres
fuckering
fuckerly
fuckers
fuckes
fuckface
fuckfaceed
fuckfaceer
fuckfacees
fuckfaceing
fuckfacely
fuckfaces
fuckin
fuckined
fuckiner
fuckines
fucking
fuckinged
fuckinger
fuckinges
fuckinging
fuckingly
fuckings
fuckining
fuckinly
fuckins
fuckly
fucknugget
fucknuggeted
fucknuggeter
fucknuggetes
fucknuggeting
fucknuggetly
fucknuggets
fucknut
fucknuted
fucknuter
fucknutes
fucknuting
fucknutly
fucknuts
fuckoff
fuckoffed
fuckoffer
fuckoffes
fuckoffing
fuckoffly
fuckoffs
fucks
fucksed
fuckser
fuckses
fucksing
fucksly
fuckss
fucktard
fucktarded
fucktarder
fucktardes
fucktarding
fucktardly
fucktards
fuckup
fuckuped
fuckuper
fuckupes
fuckuping
fuckuply
fuckups
fuckwad
fuckwaded
fuckwader
fuckwades
fuckwading
fuckwadly
fuckwads
fuckwit
fuckwited
fuckwiter
fuckwites
fuckwiting
fuckwitly
fuckwits
fudgepacker
fudgepackered
fudgepackerer
fudgepackeres
fudgepackering
fudgepackerly
fudgepackers
fuk
fuked
fuker
fukes
fuking
fukly
fuks
fvck
fvcked
fvcker
fvckes
fvcking
fvckly
fvcks
fxck
fxcked
fxcker
fxckes
fxcking
fxckly
fxcks
gae
gaeed
gaeer
gaees
gaeing
gaely
gaes
gai
gaied
gaier
gaies
gaiing
gaily
gais
ganja
ganjaed
ganjaer
ganjaes
ganjaing
ganjaly
ganjas
gayed
gayer
gayes
gaying
gayly
gays
gaysed
gayser
gayses
gaysing
gaysly
gayss
gey
geyed
geyer
geyes
geying
geyly
geys
gfc
gfced
gfcer
gfces
gfcing
gfcly
gfcs
gfy
gfyed
gfyer
gfyes
gfying
gfyly
gfys
ghay
ghayed
ghayer
ghayes
ghaying
ghayly
ghays
ghey
gheyed
gheyer
gheyes
gheying
gheyly
gheys
gigolo
gigoloed
gigoloer
gigoloes
gigoloing
gigololy
gigolos
goatse
goatseed
goatseer
goatsees
goatseing
goatsely
goatses
godamn
godamned
godamner
godamnes
godamning
godamnit
godamnited
godamniter
godamnites
godamniting
godamnitly
godamnits
godamnly
godamns
goddam
goddamed
goddamer
goddames
goddaming
goddamly
goddammit
goddammited
goddammiter
goddammites
goddammiting
goddammitly
goddammits
goddamn
goddamned
goddamner
goddamnes
goddamning
goddamnly
goddamns
goddams
goldenshower
goldenshowered
goldenshowerer
goldenshoweres
goldenshowering
goldenshowerly
goldenshowers
gonad
gonaded
gonader
gonades
gonading
gonadly
gonads
gonadsed
gonadser
gonadses
gonadsing
gonadsly
gonadss
gook
gooked
gooker
gookes
gooking
gookly
gooks
gooksed
gookser
gookses
gooksing
gooksly
gookss
gringo
gringoed
gringoer
gringoes
gringoing
gringoly
gringos
gspot
gspoted
gspoter
gspotes
gspoting
gspotly
gspots
gtfo
gtfoed
gtfoer
gtfoes
gtfoing
gtfoly
gtfos
guido
guidoed
guidoer
guidoes
guidoing
guidoly
guidos
handjob
handjobed
handjober
handjobes
handjobing
handjobly
handjobs
hard on
hard oned
hard oner
hard ones
hard oning
hard only
hard ons
hardknight
hardknighted
hardknighter
hardknightes
hardknighting
hardknightly
hardknights
hebe
hebeed
hebeer
hebees
hebeing
hebely
hebes
heeb
heebed
heeber
heebes
heebing
heebly
heebs
hell
helled
heller
helles
helling
hellly
hells
hemp
hemped
hemper
hempes
hemping
hemply
hemps
heroined
heroiner
heroines
heroining
heroinly
heroins
herp
herped
herper
herpes
herpesed
herpeser
herpeses
herpesing
herpesly
herpess
herping
herply
herps
herpy
herpyed
herpyer
herpyes
herpying
herpyly
herpys
hitler
hitlered
hitlerer
hitleres
hitlering
hitlerly
hitlers
hived
hiver
hives
hiving
hivly
hivs
hobag
hobaged
hobager
hobages
hobaging
hobagly
hobags
homey
homeyed
homeyer
homeyes
homeying
homeyly
homeys
homo
homoed
homoer
homoes
homoey
homoeyed
homoeyer
homoeyes
homoeying
homoeyly
homoeys
homoing
homoly
homos
honky
honkyed
honkyer
honkyes
honkying
honkyly
honkys
hooch
hooched
hoocher
hooches
hooching
hoochly
hoochs
hookah
hookahed
hookaher
hookahes
hookahing
hookahly
hookahs
hooker
hookered
hookerer
hookeres
hookering
hookerly
hookers
hoor
hoored
hoorer
hoores
hooring
hoorly
hoors
hootch
hootched
hootcher
hootches
hootching
hootchly
hootchs
hooter
hootered
hooterer
hooteres
hootering
hooterly
hooters
hootersed
hooterser
hooterses
hootersing
hootersly
hooterss
horny
hornyed
hornyer
hornyes
hornying
hornyly
hornys
houstoned
houstoner
houstones
houstoning
houstonly
houstons
hump
humped
humpeded
humpeder
humpedes
humpeding
humpedly
humpeds
humper
humpes
humping
humpinged
humpinger
humpinges
humpinging
humpingly
humpings
humply
humps
husbanded
husbander
husbandes
husbanding
husbandly
husbands
hussy
hussyed
hussyer
hussyes
hussying
hussyly
hussys
hymened
hymener
hymenes
hymening
hymenly
hymens
inbred
inbreded
inbreder
inbredes
inbreding
inbredly
inbreds
incest
incested
incester
incestes
incesting
incestly
incests
injun
injuned
injuner
injunes
injuning
injunly
injuns
jackass
jackassed
jackasser
jackasses
jackassing
jackassly
jackasss
jackhole
jackholeed
jackholeer
jackholees
jackholeing
jackholely
jackholes
jackoff
jackoffed
jackoffer
jackoffes
jackoffing
jackoffly
jackoffs
jap
japed
japer
japes
japing
japly
japs
japsed
japser
japses
japsing
japsly
japss
jerkoff
jerkoffed
jerkoffer
jerkoffes
jerkoffing
jerkoffly
jerkoffs
jerks
jism
jismed
jismer
jismes
jisming
jismly
jisms
jiz
jized
jizer
jizes
jizing
jizly
jizm
jizmed
jizmer
jizmes
jizming
jizmly
jizms
jizs
jizz
jizzed
jizzeded
jizzeder
jizzedes
jizzeding
jizzedly
jizzeds
jizzer
jizzes
jizzing
jizzly
jizzs
junkie
junkieed
junkieer
junkiees
junkieing
junkiely
junkies
junky
junkyed
junkyer
junkyes
junkying
junkyly
junkys
kike
kikeed
kikeer
kikees
kikeing
kikely
kikes
kikesed
kikeser
kikeses
kikesing
kikesly
kikess
killed
killer
killes
killing
killly
kills
kinky
kinkyed
kinkyer
kinkyes
kinkying
kinkyly
kinkys
kkk
kkked
kkker
kkkes
kkking
kkkly
kkks
klan
klaned
klaner
klanes
klaning
klanly
klans
knobend
knobended
knobender
knobendes
knobending
knobendly
knobends
kooch
kooched
koocher
kooches
koochesed
koocheser
koocheses
koochesing
koochesly
koochess
kooching
koochly
koochs
kootch
kootched
kootcher
kootches
kootching
kootchly
kootchs
kraut
krauted
krauter
krautes
krauting
krautly
krauts
kyke
kykeed
kykeer
kykees
kykeing
kykely
kykes
lech
leched
lecher
leches
leching
lechly
lechs
leper
lepered
leperer
leperes
lepering
leperly
lepers
lesbiansed
lesbianser
lesbianses
lesbiansing
lesbiansly
lesbianss
lesbo
lesboed
lesboer
lesboes
lesboing
lesboly
lesbos
lesbosed
lesboser
lesboses
lesbosing
lesbosly
lesboss
lez
lezbianed
lezbianer
lezbianes
lezbianing
lezbianly
lezbians
lezbiansed
lezbianser
lezbianses
lezbiansing
lezbiansly
lezbianss
lezbo
lezboed
lezboer
lezboes
lezboing
lezboly
lezbos
lezbosed
lezboser
lezboses
lezbosing
lezbosly
lezboss
lezed
lezer
lezes
lezing
lezly
lezs
lezzie
lezzieed
lezzieer
lezziees
lezzieing
lezziely
lezzies
lezziesed
lezzieser
lezzieses
lezziesing
lezziesly
lezziess
lezzy
lezzyed
lezzyer
lezzyes
lezzying
lezzyly
lezzys
lmaoed
lmaoer
lmaoes
lmaoing
lmaoly
lmaos
lmfao
lmfaoed
lmfaoer
lmfaoes
lmfaoing
lmfaoly
lmfaos
loined
loiner
loines
loining
loinly
loins
loinsed
loinser
loinses
loinsing
loinsly
loinss
lubeed
lubeer
lubees
lubeing
lubely
lubes
lusty
lustyed
lustyer
lustyes
lustying
lustyly
lustys
massa
massaed
massaer
massaes
massaing
massaly
massas
masterbate
masterbateed
masterbateer
masterbatees
masterbateing
masterbately
masterbates
masterbating
masterbatinged
masterbatinger
masterbatinges
masterbatinging
masterbatingly
masterbatings
masterbation
masterbationed
masterbationer
masterbationes
masterbationing
masterbationly
masterbations
masturbate
masturbateed
masturbateer
masturbatees
masturbateing
masturbately
masturbates
masturbating
masturbatinged
masturbatinger
masturbatinges
masturbatinging
masturbatingly
masturbatings
masturbation
masturbationed
masturbationer
masturbationes
masturbationing
masturbationly
masturbations
methed
mether
methes
mething
methly
meths
militaryed
militaryer
militaryes
militarying
militaryly
militarys
mofo
mofoed
mofoer
mofoes
mofoing
mofoly
mofos
molest
molested
molester
molestes
molesting
molestly
molests
moolie
moolieed
moolieer
mooliees
moolieing
mooliely
moolies
moron
moroned
moroner
morones
moroning
moronly
morons
motherfucka
motherfuckaed
motherfuckaer
motherfuckaes
motherfuckaing
motherfuckaly
motherfuckas
motherfucker
motherfuckered
motherfuckerer
motherfuckeres
motherfuckering
motherfuckerly
motherfuckers
motherfucking
motherfuckinged
motherfuckinger
motherfuckinges
motherfuckinging
motherfuckingly
motherfuckings
mtherfucker
mtherfuckered
mtherfuckerer
mtherfuckeres
mtherfuckering
mtherfuckerly
mtherfuckers
mthrfucker
mthrfuckered
mthrfuckerer
mthrfuckeres
mthrfuckering
mthrfuckerly
mthrfuckers
mthrfucking
mthrfuckinged
mthrfuckinger
mthrfuckinges
mthrfuckinging
mthrfuckingly
mthrfuckings
muff
muffdiver
muffdivered
muffdiverer
muffdiveres
muffdivering
muffdiverly
muffdivers
muffed
muffer
muffes
muffing
muffly
muffs
murdered
murderer
murderes
murdering
murderly
murders
muthafuckaz
muthafuckazed
muthafuckazer
muthafuckazes
muthafuckazing
muthafuckazly
muthafuckazs
muthafucker
muthafuckered
muthafuckerer
muthafuckeres
muthafuckering
muthafuckerly
muthafuckers
mutherfucker
mutherfuckered
mutherfuckerer
mutherfuckeres
mutherfuckering
mutherfuckerly
mutherfuckers
mutherfucking
mutherfuckinged
mutherfuckinger
mutherfuckinges
mutherfuckinging
mutherfuckingly
mutherfuckings
muthrfucking
muthrfuckinged
muthrfuckinger
muthrfuckinges
muthrfuckinging
muthrfuckingly
muthrfuckings
nad
naded
nader
nades
nading
nadly
nads
nadsed
nadser
nadses
nadsing
nadsly
nadss
nakeded
nakeder
nakedes
nakeding
nakedly
nakeds
napalm
napalmed
napalmer
napalmes
napalming
napalmly
napalms
nappy
nappyed
nappyer
nappyes
nappying
nappyly
nappys
nazi
nazied
nazier
nazies
naziing
nazily
nazis
nazism
nazismed
nazismer
nazismes
nazisming
nazismly
nazisms
negro
negroed
negroer
negroes
negroing
negroly
negros
nigga
niggaed
niggaer
niggaes
niggah
niggahed
niggaher
niggahes
niggahing
niggahly
niggahs
niggaing
niggaly
niggas
niggased
niggaser
niggases
niggasing
niggasly
niggass
niggaz
niggazed
niggazer
niggazes
niggazing
niggazly
niggazs
nigger
niggered
niggerer
niggeres
niggering
niggerly
niggers
niggersed
niggerser
niggerses
niggersing
niggersly
niggerss
niggle
niggleed
niggleer
nigglees
niggleing
nigglely
niggles
niglet
nigleted
nigleter
nigletes
nigleting
nigletly
niglets
nimrod
nimroded
nimroder
nimrodes
nimroding
nimrodly
nimrods
ninny
ninnyed
ninnyer
ninnyes
ninnying
ninnyly
ninnys
nooky
nookyed
nookyer
nookyes
nookying
nookyly
nookys
nuccitelli
nuccitellied
nuccitellier
nuccitellies
nuccitelliing
nuccitellily
nuccitellis
nympho
nymphoed
nymphoer
nymphoes
nymphoing
nympholy
nymphos
opium
opiumed
opiumer
opiumes
opiuming
opiumly
opiums
orgies
orgiesed
orgieser
orgieses
orgiesing
orgiesly
orgiess
orgy
orgyed
orgyer
orgyes
orgying
orgyly
orgys
paddy
paddyed
paddyer
paddyes
paddying
paddyly
paddys
paki
pakied
pakier
pakies
pakiing
pakily
pakis
pantie
pantieed
pantieer
pantiees
pantieing
pantiely
panties
pantiesed
pantieser
pantieses
pantiesing
pantiesly
pantiess
panty
pantyed
pantyer
pantyes
pantying
pantyly
pantys
pastie
pastieed
pastieer
pastiees
pastieing
pastiely
pasties
pasty
pastyed
pastyer
pastyes
pastying
pastyly
pastys
pecker
peckered
peckerer
peckeres
peckering
peckerly
peckers
pedo
pedoed
pedoer
pedoes
pedoing
pedoly
pedophile
pedophileed
pedophileer
pedophilees
pedophileing
pedophilely
pedophiles
pedophilia
pedophiliac
pedophiliaced
pedophiliacer
pedophiliaces
pedophiliacing
pedophiliacly
pedophiliacs
pedophiliaed
pedophiliaer
pedophiliaes
pedophiliaing
pedophilialy
pedophilias
pedos
penial
penialed
penialer
peniales
penialing
penially
penials
penile
penileed
penileer
penilees
penileing
penilely
peniles
penis
penised
peniser
penises
penising
penisly
peniss
perversion
perversioned
perversioner
perversiones
perversioning
perversionly
perversions
peyote
peyoteed
peyoteer
peyotees
peyoteing
peyotely
peyotes
phuck
phucked
phucker
phuckes
phucking
phuckly
phucks
pillowbiter
pillowbitered
pillowbiterer
pillowbiteres
pillowbitering
pillowbiterly
pillowbiters
pimp
pimped
pimper
pimpes
pimping
pimply
pimps
pinko
pinkoed
pinkoer
pinkoes
pinkoing
pinkoly
pinkos
pissed
pisseded
pisseder
pissedes
pisseding
pissedly
pisseds
pisser
pisses
pissing
pissly
pissoff
pissoffed
pissoffer
pissoffes
pissoffing
pissoffly
pissoffs
pisss
polack
polacked
polacker
polackes
polacking
polackly
polacks
pollock
pollocked
pollocker
pollockes
pollocking
pollockly
pollocks
poon
pooned
pooner
poones
pooning
poonly
poons
poontang
poontanged
poontanger
poontanges
poontanging
poontangly
poontangs
porn
porned
porner
pornes
porning
pornly
porno
pornoed
pornoer
pornoes
pornography
pornographyed
pornographyer
pornographyes
pornographying
pornographyly
pornographys
pornoing
pornoly
pornos
porns
prick
pricked
pricker
prickes
pricking
prickly
pricks
prig
priged
priger
priges
priging
prigly
prigs
prostitute
prostituteed
prostituteer
prostitutees
prostituteing
prostitutely
prostitutes
prude
prudeed
prudeer
prudees
prudeing
prudely
prudes
punkass
punkassed
punkasser
punkasses
punkassing
punkassly
punkasss
punky
punkyed
punkyer
punkyes
punkying
punkyly
punkys
puss
pussed
pusser
pusses
pussies
pussiesed
pussieser
pussieses
pussiesing
pussiesly
pussiess
pussing
pussly
pusss
pussy
pussyed
pussyer
pussyes
pussying
pussyly
pussypounder
pussypoundered
pussypounderer
pussypounderes
pussypoundering
pussypounderly
pussypounders
pussys
puto
putoed
putoer
putoes
putoing
putoly
putos
queaf
queafed
queafer
queafes
queafing
queafly
queafs
queef
queefed
queefer
queefes
queefing
queefly
queefs
queer
queered
queerer
queeres
queering
queerly
queero
queeroed
queeroer
queeroes
queeroing
queeroly
queeros
queers
queersed
queerser
queerses
queersing
queersly
queerss
quicky
quickyed
quickyer
quickyes
quickying
quickyly
quickys
quim
quimed
quimer
quimes
quiming
quimly
quims
racy
racyed
racyer
racyes
racying
racyly
racys
rape
raped
rapeded
rapeder
rapedes
rapeding
rapedly
rapeds
rapeed
rapeer
rapees
rapeing
rapely
raper
rapered
raperer
raperes
rapering
raperly
rapers
rapes
rapist
rapisted
rapister
rapistes
rapisting
rapistly
rapists
raunch
raunched
rauncher
raunches
raunching
raunchly
raunchs
rectus
rectused
rectuser
rectuses
rectusing
rectusly
rectuss
reefer
reefered
reeferer
reeferes
reefering
reeferly
reefers
reetard
reetarded
reetarder
reetardes
reetarding
reetardly
reetards
reich
reiched
reicher
reiches
reiching
reichly
reichs
retard
retarded
retardeded
retardeder
retardedes
retardeding
retardedly
retardeds
retarder
retardes
retarding
retardly
retards
rimjob
rimjobed
rimjober
rimjobes
rimjobing
rimjobly
rimjobs
ritard
ritarded
ritarder
ritardes
ritarding
ritardly
ritards
rtard
rtarded
rtarder
rtardes
rtarding
rtardly
rtards
rum
rumed
rumer
rumes
ruming
rumly
rump
rumped
rumper
rumpes
rumping
rumply
rumprammer
rumprammered
rumprammerer
rumprammeres
rumprammering
rumprammerly
rumprammers
rumps
rums
ruski
ruskied
ruskier
ruskies
ruskiing
ruskily
ruskis
sadism
sadismed
sadismer
sadismes
sadisming
sadismly
sadisms
sadist
sadisted
sadister
sadistes
sadisting
sadistly
sadists
scag
scaged
scager
scages
scaging
scagly
scags
scantily
scantilyed
scantilyer
scantilyes
scantilying
scantilyly
scantilys
schlong
schlonged
schlonger
schlonges
schlonging
schlongly
schlongs
scrog
scroged
scroger
scroges
scroging
scrogly
scrogs
scrot
scrote
scroted
scroteed
scroteer
scrotees
scroteing
scrotely
scroter
scrotes
scroting
scrotly
scrots
scrotum
scrotumed
scrotumer
scrotumes
scrotuming
scrotumly
scrotums
scrud
scruded
scruder
scrudes
scruding
scrudly
scruds
scum
scumed
scumer
scumes
scuming
scumly
scums
seaman
seamaned
seamaner
seamanes
seamaning
seamanly
seamans
seamen
seamened
seamener
seamenes
seamening
seamenly
seamens
seduceed
seduceer
seducees
seduceing
seducely
seduces
semen
semened
semener
semenes
semening
semenly
semens
shamedame
shamedameed
shamedameer
shamedamees
shamedameing
shamedamely
shamedames
shit
shite
shiteater
shiteatered
shiteaterer
shiteateres
shiteatering
shiteaterly
shiteaters
shited
shiteed
shiteer
shitees
shiteing
shitely
shiter
shites
shitface
shitfaceed
shitfaceer
shitfacees
shitfaceing
shitfacely
shitfaces
shithead
shitheaded
shitheader
shitheades
shitheading
shitheadly
shitheads
shithole
shitholeed
shitholeer
shitholees
shitholeing
shitholely
shitholes
shithouse
shithouseed
shithouseer
shithousees
shithouseing
shithousely
shithouses
shiting
shitly
shits
shitsed
shitser
shitses
shitsing
shitsly
shitss
shitt
shitted
shitteded
shitteder
shittedes
shitteding
shittedly
shitteds
shitter
shittered
shitterer
shitteres
shittering
shitterly
shitters
shittes
shitting
shittly
shitts
shitty
shittyed
shittyer
shittyes
shittying
shittyly
shittys
shiz
shized
shizer
shizes
shizing
shizly
shizs
shooted
shooter
shootes
shooting
shootly
shoots
sissy
sissyed
sissyer
sissyes
sissying
sissyly
sissys
skag
skaged
skager
skages
skaging
skagly
skags
skank
skanked
skanker
skankes
skanking
skankly
skanks
slave
slaveed
slaveer
slavees
slaveing
slavely
slaves
sleaze
sleazeed
sleazeer
sleazees
sleazeing
sleazely
sleazes
sleazy
sleazyed
sleazyer
sleazyes
sleazying
sleazyly
sleazys
slut
slutdumper
slutdumpered
slutdumperer
slutdumperes
slutdumpering
slutdumperly
slutdumpers
sluted
sluter
slutes
sluting
slutkiss
slutkissed
slutkisser
slutkisses
slutkissing
slutkissly
slutkisss
slutly
sluts
slutsed
slutser
slutses
slutsing
slutsly
slutss
smegma
smegmaed
smegmaer
smegmaes
smegmaing
smegmaly
smegmas
smut
smuted
smuter
smutes
smuting
smutly
smuts
smutty
smuttyed
smuttyer
smuttyes
smuttying
smuttyly
smuttys
snatch
snatched
snatcher
snatches
snatching
snatchly
snatchs
sniper
snipered
sniperer
sniperes
snipering
sniperly
snipers
snort
snorted
snorter
snortes
snorting
snortly
snorts
snuff
snuffed
snuffer
snuffes
snuffing
snuffly
snuffs
sodom
sodomed
sodomer
sodomes
sodoming
sodomly
sodoms
spic
spiced
spicer
spices
spicing
spick
spicked
spicker
spickes
spicking
spickly
spicks
spicly
spics
spik
spoof
spoofed
spoofer
spoofes
spoofing
spoofly
spoofs
spooge
spoogeed
spoogeer
spoogees
spoogeing
spoogely
spooges
spunk
spunked
spunker
spunkes
spunking
spunkly
spunks
steamyed
steamyer
steamyes
steamying
steamyly
steamys
stfu
stfued
stfuer
stfues
stfuing
stfuly
stfus
stiffy
stiffyed
stiffyer
stiffyes
stiffying
stiffyly
stiffys
stoneded
stoneder
stonedes
stoneding
stonedly
stoneds
stupided
stupider
stupides
stupiding
stupidly
stupids
suckeded
suckeder
suckedes
suckeding
suckedly
suckeds
sucker
suckes
sucking
suckinged
suckinger
suckinges
suckinging
suckingly
suckings
suckly
sucks
sumofabiatch
sumofabiatched
sumofabiatcher
sumofabiatches
sumofabiatching
sumofabiatchly
sumofabiatchs
tard
tarded
tarder
tardes
tarding
tardly
tards
tawdry
tawdryed
tawdryer
tawdryes
tawdrying
tawdryly
tawdrys
teabagging
teabagginged
teabagginger
teabagginges
teabagginging
teabaggingly
teabaggings
terd
terded
terder
terdes
terding
terdly
terds
teste
testee
testeed
testeeed
testeeer
testeees
testeeing
testeely
testeer
testees
testeing
testely
testes
testesed
testeser
testeses
testesing
testesly
testess
testicle
testicleed
testicleer
testiclees
testicleing
testiclely
testicles
testis
testised
testiser
testises
testising
testisly
testiss
thrusted
thruster
thrustes
thrusting
thrustly
thrusts
thug
thuged
thuger
thuges
thuging
thugly
thugs
tinkle
tinkleed
tinkleer
tinklees
tinkleing
tinklely
tinkles
tit
tited
titer
tites
titfuck
titfucked
titfucker
titfuckes
titfucking
titfuckly
titfucks
titi
titied
titier
tities
titiing
titily
titing
titis
titly
tits
titsed
titser
titses
titsing
titsly
titss
tittiefucker
tittiefuckered
tittiefuckerer
tittiefuckeres
tittiefuckering
tittiefuckerly
tittiefuckers
titties
tittiesed
tittieser
tittieses
tittiesing
tittiesly
tittiess
titty
tittyed
tittyer
tittyes
tittyfuck
tittyfucked
tittyfucker
tittyfuckered
tittyfuckerer
tittyfuckeres
tittyfuckering
tittyfuckerly
tittyfuckers
tittyfuckes
tittyfucking
tittyfuckly
tittyfucks
tittying
tittyly
tittys
toke
tokeed
tokeer
tokees
tokeing
tokely
tokes
toots
tootsed
tootser
tootses
tootsing
tootsly
tootss
tramp
tramped
tramper
trampes
tramping
tramply
tramps
transsexualed
transsexualer
transsexuales
transsexualing
transsexually
transsexuals
trashy
trashyed
trashyer
trashyes
trashying
trashyly
trashys
tubgirl
tubgirled
tubgirler
tubgirles
tubgirling
tubgirlly
tubgirls
turd
turded
turder
turdes
turding
turdly
turds
tush
tushed
tusher
tushes
tushing
tushly
tushs
twat
twated
twater
twates
twating
twatly
twats
twatsed
twatser
twatses
twatsing
twatsly
twatss
undies
undiesed
undieser
undieses
undiesing
undiesly
undiess
unweded
unweder
unwedes
unweding
unwedly
unweds
uzi
uzied
uzier
uzies
uziing
uzily
uzis
vag
vaged
vager
vages
vaging
vagly
vags
valium
valiumed
valiumer
valiumes
valiuming
valiumly
valiums
venous
virgined
virginer
virgines
virgining
virginly
virgins
vixen
vixened
vixener
vixenes
vixening
vixenly
vixens
vodkaed
vodkaer
vodkaes
vodkaing
vodkaly
vodkas
voyeur
voyeured
voyeurer
voyeures
voyeuring
voyeurly
voyeurs
vulgar
vulgared
vulgarer
vulgares
vulgaring
vulgarly
vulgars
wang
wanged
wanger
wanges
wanging
wangly
wangs
wank
wanked
wanker
wankered
wankerer
wankeres
wankering
wankerly
wankers
wankes
wanking
wankly
wanks
wazoo
wazooed
wazooer
wazooes
wazooing
wazooly
wazoos
wedgie
wedgieed
wedgieer
wedgiees
wedgieing
wedgiely
wedgies
weeded
weeder
weedes
weeding
weedly
weeds
weenie
weenieed
weenieer
weeniees
weenieing
weeniely
weenies
weewee
weeweeed
weeweeer
weeweees
weeweeing
weeweely
weewees
weiner
weinered
weinerer
weineres
weinering
weinerly
weiners
weirdo
weirdoed
weirdoer
weirdoes
weirdoing
weirdoly
weirdos
wench
wenched
wencher
wenches
wenching
wenchly
wenchs
wetback
wetbacked
wetbacker
wetbackes
wetbacking
wetbackly
wetbacks
whitey
whiteyed
whiteyer
whiteyes
whiteying
whiteyly
whiteys
whiz
whized
whizer
whizes
whizing
whizly
whizs
whoralicious
whoralicioused
whoraliciouser
whoraliciouses
whoraliciousing
whoraliciously
whoraliciouss
whore
whorealicious
whorealicioused
whorealiciouser
whorealiciouses
whorealiciousing
whorealiciously
whorealiciouss
whored
whoreded
whoreder
whoredes
whoreding
whoredly
whoreds
whoreed
whoreer
whorees
whoreface
whorefaceed
whorefaceer
whorefacees
whorefaceing
whorefacely
whorefaces
whorehopper
whorehoppered
whorehopperer
whorehopperes
whorehoppering
whorehopperly
whorehoppers
whorehouse
whorehouseed
whorehouseer
whorehousees
whorehouseing
whorehousely
whorehouses
whoreing
whorely
whores
whoresed
whoreser
whoreses
whoresing
whoresly
whoress
whoring
whoringed
whoringer
whoringes
whoringing
whoringly
whorings
wigger
wiggered
wiggerer
wiggeres
wiggering
wiggerly
wiggers
woody
woodyed
woodyer
woodyes
woodying
woodyly
woodys
wop
woped
woper
wopes
woping
woply
wops
wtf
wtfed
wtfer
wtfes
wtfing
wtfly
wtfs
xxx
xxxed
xxxer
xxxes
xxxing
xxxly
xxxs
yeasty
yeastyed
yeastyer
yeastyes
yeastying
yeastyly
yeastys
yobbo
yobboed
yobboer
yobboes
yobboing
yobboly
yobbos
zoophile
zoophileed
zoophileer
zoophilees
zoophileing
zoophilely
zoophiles
anal
ass
ass lick
balls
ballsac
bisexual
bleach
causas
cheap
cost of miracles
cunt
display network stats
fart
fda and death
fda AND warn
fda AND warning
fda AND warns
feom
fuck
gfc
humira AND expensive
illegal
madvocate
masturbation
nuccitelli
overdose
porn
shit
snort
texarkana
direct\-acting antivirals
assistance
ombitasvir
support path
harvoni
abbvie
direct-acting antivirals
paritaprevir
advocacy
ledipasvir
vpak
ritonavir with dasabuvir
program
gilead
greedy
financial
needy
fake-ovir
viekira pak
v pak
sofosbuvir
support
oasis
discount
dasabuvir
protest
ritonavir
section[contains(@class, 'nav-hidden')]
footer[@id='footer']
div[contains(@class, 'pane-pub-article-cleveland-clinic')]
div[contains(@class, 'pane-pub-home-cleveland-clinic')]
div[contains(@class, 'pane-pub-topic-cleveland-clinic')]
div[contains(@class, 'panel-panel-inner')]
div[contains(@class, 'pane-node-field-article-topics')]
section[contains(@class, 'footer-nav-section-wrapper')]
Metastatic pulmonary calcification and end-stage renal disease
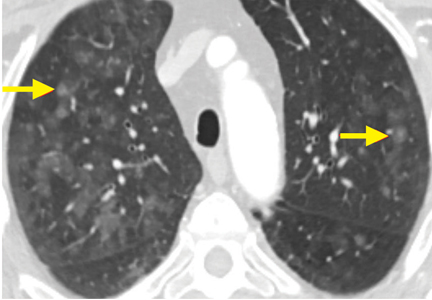
A 64-year-old man with end-stage renal disease was evaluated in the pulmonary clinic for persistent abnormalities on axial computed tomography (CT) of the chest. He was a lifelong nonsmoker and had no history of exposure to occupational dust or fumes. His oxygen saturation was 100% on room air, and he denied any respiratory symptoms.

, as did plain radiography of the elbow.")
WHEN TO CONSIDER METASTATIC PULMONARY CALCIFICATION
The differential diagnosis for chronic upper-lobe-predominant ground-glass nodules is broad and includes atypical infections, recurrent alveolar hemorrhage, hypersensitivity pneumonitis, vasculitis, sarcoidosis, chronic eosinophilic pneumonia, occupational lung disease, and pulmonary alveolar microlithiasis. However, several aspects of our patient’s case suggested an often overlooked diagnosis, metastatic pulmonary calcification.
Metastatic pulmonary calcification is caused by deposition of calcium salts in lung tissue and is most commonly seen in patients on dialysis,1,2 and our patient had been dependent on dialysis for many years. The chronically elevated calcium-phosphorus product and secondary hyperparathyroidism often seen with end-stage renal disease may explain this association.
Our patient’s lack of symptoms is also an important diagnostic clue. Unlike many other causes of chronic upper-lobe-predominant ground-glass nodules, metastatic pulmonary calcification does not usually cause symptoms and is often identified only at autopsy.3 Results of pulmonary function testing are often normal.4
Metastatic pulmonary calcification can appear as diffusely calcified nodules or high-attenuation areas of consolidation on CT. However, as in our patient’s case, CT may demonstrate fluffy, centrilobular ground-glass nodules due to the microscopic size of the deposited calcium crystals.1 Identifying calcified vessels on imaging supports the diagnosis.4
Treatment of metastatic pulmonary calcification in a patient with end-stage renal disease is focused on correcting underlying metabolic abnormalities with phosphate binders, vitamin D supplementation, and dialysis.
- Chan ED, Morales DV, Welsh CH, McDermott MT, Schwarz MI. Calcium deposition with or without bone formation in the lung. Am J Respir Crit Care Med 2002; 165:1654–1669.
- Beyzaei A, Francis J, Knight H, Simon DB, Finkelstein FO. Metabolic lung disease: diffuse metastatic pulmonary calcifications with progression to calciphylaxis in end-stage renal disease. Adv Perit Dial 2007; 23:112–117.
- Conger JD, Hammond WS, Alfrey AC, Contiguglia SR, Stanford RE, Huffer WE. Pulmonary calcification in chronic dialysis patients. Clinical and pathologic studies. Ann Intern Med 1975; 83:330–336.
- Belem LC, Zanetti G, Souza AS Jr, et al. Metastatic pulmonary calcification: state-of-the-art review focused on imaging findings. Respir Med 2014; 108:668–676.
A 64-year-old man with end-stage renal disease was evaluated in the pulmonary clinic for persistent abnormalities on axial computed tomography (CT) of the chest. He was a lifelong nonsmoker and had no history of exposure to occupational dust or fumes. His oxygen saturation was 100% on room air, and he denied any respiratory symptoms.
WHEN TO CONSIDER METASTATIC PULMONARY CALCIFICATION
The differential diagnosis for chronic upper-lobe-predominant ground-glass nodules is broad and includes atypical infections, recurrent alveolar hemorrhage, hypersensitivity pneumonitis, vasculitis, sarcoidosis, chronic eosinophilic pneumonia, occupational lung disease, and pulmonary alveolar microlithiasis. However, several aspects of our patient’s case suggested an often overlooked diagnosis, metastatic pulmonary calcification.
Metastatic pulmonary calcification is caused by deposition of calcium salts in lung tissue and is most commonly seen in patients on dialysis,1,2 and our patient had been dependent on dialysis for many years. The chronically elevated calcium-phosphorus product and secondary hyperparathyroidism often seen with end-stage renal disease may explain this association.
Our patient’s lack of symptoms is also an important diagnostic clue. Unlike many other causes of chronic upper-lobe-predominant ground-glass nodules, metastatic pulmonary calcification does not usually cause symptoms and is often identified only at autopsy.3 Results of pulmonary function testing are often normal.4
Metastatic pulmonary calcification can appear as diffusely calcified nodules or high-attenuation areas of consolidation on CT. However, as in our patient’s case, CT may demonstrate fluffy, centrilobular ground-glass nodules due to the microscopic size of the deposited calcium crystals.1 Identifying calcified vessels on imaging supports the diagnosis.4
Treatment of metastatic pulmonary calcification in a patient with end-stage renal disease is focused on correcting underlying metabolic abnormalities with phosphate binders, vitamin D supplementation, and dialysis.
A 64-year-old man with end-stage renal disease was evaluated in the pulmonary clinic for persistent abnormalities on axial computed tomography (CT) of the chest. He was a lifelong nonsmoker and had no history of exposure to occupational dust or fumes. His oxygen saturation was 100% on room air, and he denied any respiratory symptoms.
WHEN TO CONSIDER METASTATIC PULMONARY CALCIFICATION
The differential diagnosis for chronic upper-lobe-predominant ground-glass nodules is broad and includes atypical infections, recurrent alveolar hemorrhage, hypersensitivity pneumonitis, vasculitis, sarcoidosis, chronic eosinophilic pneumonia, occupational lung disease, and pulmonary alveolar microlithiasis. However, several aspects of our patient’s case suggested an often overlooked diagnosis, metastatic pulmonary calcification.
Metastatic pulmonary calcification is caused by deposition of calcium salts in lung tissue and is most commonly seen in patients on dialysis,1,2 and our patient had been dependent on dialysis for many years. The chronically elevated calcium-phosphorus product and secondary hyperparathyroidism often seen with end-stage renal disease may explain this association.
Our patient’s lack of symptoms is also an important diagnostic clue. Unlike many other causes of chronic upper-lobe-predominant ground-glass nodules, metastatic pulmonary calcification does not usually cause symptoms and is often identified only at autopsy.3 Results of pulmonary function testing are often normal.4
Metastatic pulmonary calcification can appear as diffusely calcified nodules or high-attenuation areas of consolidation on CT. However, as in our patient’s case, CT may demonstrate fluffy, centrilobular ground-glass nodules due to the microscopic size of the deposited calcium crystals.1 Identifying calcified vessels on imaging supports the diagnosis.4
Treatment of metastatic pulmonary calcification in a patient with end-stage renal disease is focused on correcting underlying metabolic abnormalities with phosphate binders, vitamin D supplementation, and dialysis.
- Chan ED, Morales DV, Welsh CH, McDermott MT, Schwarz MI. Calcium deposition with or without bone formation in the lung. Am J Respir Crit Care Med 2002; 165:1654–1669.
- Beyzaei A, Francis J, Knight H, Simon DB, Finkelstein FO. Metabolic lung disease: diffuse metastatic pulmonary calcifications with progression to calciphylaxis in end-stage renal disease. Adv Perit Dial 2007; 23:112–117.
- Conger JD, Hammond WS, Alfrey AC, Contiguglia SR, Stanford RE, Huffer WE. Pulmonary calcification in chronic dialysis patients. Clinical and pathologic studies. Ann Intern Med 1975; 83:330–336.
- Belem LC, Zanetti G, Souza AS Jr, et al. Metastatic pulmonary calcification: state-of-the-art review focused on imaging findings. Respir Med 2014; 108:668–676.
- Chan ED, Morales DV, Welsh CH, McDermott MT, Schwarz MI. Calcium deposition with or without bone formation in the lung. Am J Respir Crit Care Med 2002; 165:1654–1669.
- Beyzaei A, Francis J, Knight H, Simon DB, Finkelstein FO. Metabolic lung disease: diffuse metastatic pulmonary calcifications with progression to calciphylaxis in end-stage renal disease. Adv Perit Dial 2007; 23:112–117.
- Conger JD, Hammond WS, Alfrey AC, Contiguglia SR, Stanford RE, Huffer WE. Pulmonary calcification in chronic dialysis patients. Clinical and pathologic studies. Ann Intern Med 1975; 83:330–336.
- Belem LC, Zanetti G, Souza AS Jr, et al. Metastatic pulmonary calcification: state-of-the-art review focused on imaging findings. Respir Med 2014; 108:668–676.
Cardiac mass: Tumor or thrombus?
To the Editor: We read with great interest the article by Patnaik et al1 about a patient who had a cardiac metastasis of ovarian cancer, and we would like to raise a few points.
It is important to clarify that metastatic cardiac tumors are not necessary malignant. Intravenous leiomyomatosis is a benign small-muscle tumor that can spread to the heart, causing various cardiac symptoms.2 Even with extensive disease, patients with intravenous leiomyomatosis may remain asymptomatic until cardiac involvement occurs. The most common cardiac symptoms are dyspnea, syncope, and lower-extremity edema.
Cardiac involvement in intravenous leiomyomatosis may occur via direct invasion or hematogenous or lymphatic spread of the tumor. In leiomyoma and leiomyosarcoma, cardiac invasion usually occurs via direct spread through the inferior vena cava into the right atrium and ventricle. Thus, cardiac involvement with these tumors (except for nephroma) was reported to exclusively involve the right side of the heart.
In 2014, we reported a unique case of intravenous leiomyomatosis that extended from the right side into the left side of the heart and the aorta via an atrial septal defect.2 Intracardiac extension of intravenous leiomyomatosis may result in pulmonary embolism, systemic embolization if involving the left side, and, rarely, sudden death.2
In patients with malignancy, differentiating between thrombosis and tumor is critical. These patients have a hypercoagulable state and a fourfold increase in thrombosis risk, and chemotherapy increases this risk even more.3 Although tissue pathology examination is important for differentiating thrombosis from tumor, visualization of the direct extension of the mass from the primary source into the heart through the inferior vena cava by ultrasonography, computed tomography, or magnetic resonance imaging may help in making this distinction.2
- Patnaik S, Shah M, Sharma S, Ram P, Rammohan HS, Rubin A. A large mass in the right ventricle: tumor or thrombus? Cleve Clin J Med 2017; 84:517–519.
- Abdelghany M, Sodagam A, Patel P, Goldblatt C, Patel R. Intracardiac atypical leiomyoma involving all four cardiac chambers and the aorta. Rev Cardiovasc Med 2014; 15:271–275.
- Khorana AA, Kuderer NM, Culakova E, Lyman GH, Francis CW. Development and validation of a predictive model for chemotherapy-associated thrombosis. Blood 2008; 111:4902–4907.
To the Editor: We read with great interest the article by Patnaik et al1 about a patient who had a cardiac metastasis of ovarian cancer, and we would like to raise a few points.
It is important to clarify that metastatic cardiac tumors are not necessary malignant. Intravenous leiomyomatosis is a benign small-muscle tumor that can spread to the heart, causing various cardiac symptoms.2 Even with extensive disease, patients with intravenous leiomyomatosis may remain asymptomatic until cardiac involvement occurs. The most common cardiac symptoms are dyspnea, syncope, and lower-extremity edema.
Cardiac involvement in intravenous leiomyomatosis may occur via direct invasion or hematogenous or lymphatic spread of the tumor. In leiomyoma and leiomyosarcoma, cardiac invasion usually occurs via direct spread through the inferior vena cava into the right atrium and ventricle. Thus, cardiac involvement with these tumors (except for nephroma) was reported to exclusively involve the right side of the heart.
In 2014, we reported a unique case of intravenous leiomyomatosis that extended from the right side into the left side of the heart and the aorta via an atrial septal defect.2 Intracardiac extension of intravenous leiomyomatosis may result in pulmonary embolism, systemic embolization if involving the left side, and, rarely, sudden death.2
In patients with malignancy, differentiating between thrombosis and tumor is critical. These patients have a hypercoagulable state and a fourfold increase in thrombosis risk, and chemotherapy increases this risk even more.3 Although tissue pathology examination is important for differentiating thrombosis from tumor, visualization of the direct extension of the mass from the primary source into the heart through the inferior vena cava by ultrasonography, computed tomography, or magnetic resonance imaging may help in making this distinction.2
To the Editor: We read with great interest the article by Patnaik et al1 about a patient who had a cardiac metastasis of ovarian cancer, and we would like to raise a few points.
It is important to clarify that metastatic cardiac tumors are not necessary malignant. Intravenous leiomyomatosis is a benign small-muscle tumor that can spread to the heart, causing various cardiac symptoms.2 Even with extensive disease, patients with intravenous leiomyomatosis may remain asymptomatic until cardiac involvement occurs. The most common cardiac symptoms are dyspnea, syncope, and lower-extremity edema.
Cardiac involvement in intravenous leiomyomatosis may occur via direct invasion or hematogenous or lymphatic spread of the tumor. In leiomyoma and leiomyosarcoma, cardiac invasion usually occurs via direct spread through the inferior vena cava into the right atrium and ventricle. Thus, cardiac involvement with these tumors (except for nephroma) was reported to exclusively involve the right side of the heart.
In 2014, we reported a unique case of intravenous leiomyomatosis that extended from the right side into the left side of the heart and the aorta via an atrial septal defect.2 Intracardiac extension of intravenous leiomyomatosis may result in pulmonary embolism, systemic embolization if involving the left side, and, rarely, sudden death.2
In patients with malignancy, differentiating between thrombosis and tumor is critical. These patients have a hypercoagulable state and a fourfold increase in thrombosis risk, and chemotherapy increases this risk even more.3 Although tissue pathology examination is important for differentiating thrombosis from tumor, visualization of the direct extension of the mass from the primary source into the heart through the inferior vena cava by ultrasonography, computed tomography, or magnetic resonance imaging may help in making this distinction.2
- Patnaik S, Shah M, Sharma S, Ram P, Rammohan HS, Rubin A. A large mass in the right ventricle: tumor or thrombus? Cleve Clin J Med 2017; 84:517–519.
- Abdelghany M, Sodagam A, Patel P, Goldblatt C, Patel R. Intracardiac atypical leiomyoma involving all four cardiac chambers and the aorta. Rev Cardiovasc Med 2014; 15:271–275.
- Khorana AA, Kuderer NM, Culakova E, Lyman GH, Francis CW. Development and validation of a predictive model for chemotherapy-associated thrombosis. Blood 2008; 111:4902–4907.
- Patnaik S, Shah M, Sharma S, Ram P, Rammohan HS, Rubin A. A large mass in the right ventricle: tumor or thrombus? Cleve Clin J Med 2017; 84:517–519.
- Abdelghany M, Sodagam A, Patel P, Goldblatt C, Patel R. Intracardiac atypical leiomyoma involving all four cardiac chambers and the aorta. Rev Cardiovasc Med 2014; 15:271–275.
- Khorana AA, Kuderer NM, Culakova E, Lyman GH, Francis CW. Development and validation of a predictive model for chemotherapy-associated thrombosis. Blood 2008; 111:4902–4907.
Anticoagulation for atrial fibrillation
To the Editor: As a geriatric medicine fellow, I eagerly read Hagerty and Rich’s review “Fall risk and anticoagulation for atrial fibrillation in the elderly: A delicate balance”1 and Suh’s editorial, “Whether to anticoagulate: Toward a more reasoned approach”2 in the January 2017 issue. Both pieces were helpful and informative.
I appreciate that Dr. Suh encourages shared decision-making between physicians and patients that balances patient preferences and risk stratification to inform whether to anticoagulate. He states, “Unfortunately, there is no similar screening tool to predict bleeding risk from anticoagulation with greater precision in the middle to lower part of the risk spectrum...The patient’s life expectancy and personal preferences are important independent factors that affect the decision of whether to anticoagulate or not.”
Dr. Mark Eckman’s Atrial Fibrillation Decision Support Tool (AFDST) incorporates patients’ CHA2DS2-VASc and HAS-BLED scores to determine their quality-adjusted life expectancy on or off anticoagulation. The tool helps guide physicians and patients to make shared decisions about anticoagulation.3–5 The AFDST informs clinicians if a patient is undertreated or being treated unnecessarily. Eckman and his colleagues have demonstrated the AFDST’s effective application in clinical practice, including for older adults. I invite readers to learn more about Eckman’s work!
- Hagerty T, Rich MW. Fall risk and anticoagulation for atrial fibrillation in the elderly: a delicate balance. Cleve Clin J Med 2017; 84:35–40.
- Suh TT. Whether to anticoagulate: toward a more reasoned approach. Cleve Clin J Med 2017; 84:41–42.
- Eckman MH, Lip GYH, Wise RE, et al. Impact of an atrial fibrillation decision support tool on thromboprophylaxis for atrial fibrillation. Am Heart J 2016; 176:17–27.
- Eckman MH, Wise RE, Speer B, et al. Integrating real-time clinical information to provide estimates of net clinical benefit antithrombotic therapy for patients with atrial fibrillation. Circ Cardiovasc Qual Outcomes 2014; 7:680–686.
- Eckman MH, Lip TYH, Wise RE, et al. Using an atrial fibrillation decision support tool for thromboprophylaxis in atrial fibrillation: effect of sex and age. J Am Geriatr Soc 2016; 64:1054–1060.
To the Editor: As a geriatric medicine fellow, I eagerly read Hagerty and Rich’s review “Fall risk and anticoagulation for atrial fibrillation in the elderly: A delicate balance”1 and Suh’s editorial, “Whether to anticoagulate: Toward a more reasoned approach”2 in the January 2017 issue. Both pieces were helpful and informative.
I appreciate that Dr. Suh encourages shared decision-making between physicians and patients that balances patient preferences and risk stratification to inform whether to anticoagulate. He states, “Unfortunately, there is no similar screening tool to predict bleeding risk from anticoagulation with greater precision in the middle to lower part of the risk spectrum...The patient’s life expectancy and personal preferences are important independent factors that affect the decision of whether to anticoagulate or not.”
Dr. Mark Eckman’s Atrial Fibrillation Decision Support Tool (AFDST) incorporates patients’ CHA2DS2-VASc and HAS-BLED scores to determine their quality-adjusted life expectancy on or off anticoagulation. The tool helps guide physicians and patients to make shared decisions about anticoagulation.3–5 The AFDST informs clinicians if a patient is undertreated or being treated unnecessarily. Eckman and his colleagues have demonstrated the AFDST’s effective application in clinical practice, including for older adults. I invite readers to learn more about Eckman’s work!
To the Editor: As a geriatric medicine fellow, I eagerly read Hagerty and Rich’s review “Fall risk and anticoagulation for atrial fibrillation in the elderly: A delicate balance”1 and Suh’s editorial, “Whether to anticoagulate: Toward a more reasoned approach”2 in the January 2017 issue. Both pieces were helpful and informative.
I appreciate that Dr. Suh encourages shared decision-making between physicians and patients that balances patient preferences and risk stratification to inform whether to anticoagulate. He states, “Unfortunately, there is no similar screening tool to predict bleeding risk from anticoagulation with greater precision in the middle to lower part of the risk spectrum...The patient’s life expectancy and personal preferences are important independent factors that affect the decision of whether to anticoagulate or not.”
Dr. Mark Eckman’s Atrial Fibrillation Decision Support Tool (AFDST) incorporates patients’ CHA2DS2-VASc and HAS-BLED scores to determine their quality-adjusted life expectancy on or off anticoagulation. The tool helps guide physicians and patients to make shared decisions about anticoagulation.3–5 The AFDST informs clinicians if a patient is undertreated or being treated unnecessarily. Eckman and his colleagues have demonstrated the AFDST’s effective application in clinical practice, including for older adults. I invite readers to learn more about Eckman’s work!
- Hagerty T, Rich MW. Fall risk and anticoagulation for atrial fibrillation in the elderly: a delicate balance. Cleve Clin J Med 2017; 84:35–40.
- Suh TT. Whether to anticoagulate: toward a more reasoned approach. Cleve Clin J Med 2017; 84:41–42.
- Eckman MH, Lip GYH, Wise RE, et al. Impact of an atrial fibrillation decision support tool on thromboprophylaxis for atrial fibrillation. Am Heart J 2016; 176:17–27.
- Eckman MH, Wise RE, Speer B, et al. Integrating real-time clinical information to provide estimates of net clinical benefit antithrombotic therapy for patients with atrial fibrillation. Circ Cardiovasc Qual Outcomes 2014; 7:680–686.
- Eckman MH, Lip TYH, Wise RE, et al. Using an atrial fibrillation decision support tool for thromboprophylaxis in atrial fibrillation: effect of sex and age. J Am Geriatr Soc 2016; 64:1054–1060.
- Hagerty T, Rich MW. Fall risk and anticoagulation for atrial fibrillation in the elderly: a delicate balance. Cleve Clin J Med 2017; 84:35–40.
- Suh TT. Whether to anticoagulate: toward a more reasoned approach. Cleve Clin J Med 2017; 84:41–42.
- Eckman MH, Lip GYH, Wise RE, et al. Impact of an atrial fibrillation decision support tool on thromboprophylaxis for atrial fibrillation. Am Heart J 2016; 176:17–27.
- Eckman MH, Wise RE, Speer B, et al. Integrating real-time clinical information to provide estimates of net clinical benefit antithrombotic therapy for patients with atrial fibrillation. Circ Cardiovasc Qual Outcomes 2014; 7:680–686.
- Eckman MH, Lip TYH, Wise RE, et al. Using an atrial fibrillation decision support tool for thromboprophylaxis in atrial fibrillation: effect of sex and age. J Am Geriatr Soc 2016; 64:1054–1060.
In reply: Anticoagulation for atrial fibrillation
In Reply: I appreciate Dr. Henning’s letter in response to my editorial.1 Indeed, Dr. Eckman’s Atrial Fibrillation Decision Support Tool (AFDST) is useful for determining quality-adjusted life expectancy on or off anticoagulation, and could possibly help with shared decision-making in regard to anticoagulation.2–4
However, the AFDST does not incorporate personal preferences regarding anticoagulant or medication use in general. Many older adults are on too many medications (ie, polypharmacy) and wish to reduce their overall pill count.
A number of potential barriers to shared decision-making regarding medication use have been identified, including poor physician communication skills, the growing number of available medications, multiple prescribers for the same patient, lack of trust in the prescribing physician, and patients feeling that their preferences are not valued or important.5 Until communication and acceptance between prescribers and patients regarding possible medication choices improves, shared decision-making for medication use in general and anticoagulant use in particular will be an unfulfilled ideal.
- Suh TT. Whether to anticoagulate: toward a more reasoned approach. Cleve Clin J Med 2017; 84:41–42.
- Eckman MH, Lip GYH, Wise RE, et al. Impact of an atrial fibrillation decision support tool on thromboprophylaxis for atrial fibrillation. Am Heart J 2016; 176:17–27.
- Eckman MH, Wise RE, Speer B, et al. Integrating real-time clinical information to provide estimates of net clinical benefit antithrombotic therapy for patients with atrial fibrillation. Circ Cardiovasc Qual Outcomes 2014; 7:680–686.
- Eckman MH, Lip TYH, Wise RE, et al. Using an atrial fibrillation decision support tool for thromboprophylaxis in atrial fibrillation: effect of sex and age. J Am Geriatr Soc 2016; 64:1054–1060.
- Belcher VN, Fried TR, Agostini JV, Tinetti ME. Views of older adults on patient participation in medication-related decision making. J Gen Intern Med 2006; 21:298–303.
In Reply: I appreciate Dr. Henning’s letter in response to my editorial.1 Indeed, Dr. Eckman’s Atrial Fibrillation Decision Support Tool (AFDST) is useful for determining quality-adjusted life expectancy on or off anticoagulation, and could possibly help with shared decision-making in regard to anticoagulation.2–4
However, the AFDST does not incorporate personal preferences regarding anticoagulant or medication use in general. Many older adults are on too many medications (ie, polypharmacy) and wish to reduce their overall pill count.
A number of potential barriers to shared decision-making regarding medication use have been identified, including poor physician communication skills, the growing number of available medications, multiple prescribers for the same patient, lack of trust in the prescribing physician, and patients feeling that their preferences are not valued or important.5 Until communication and acceptance between prescribers and patients regarding possible medication choices improves, shared decision-making for medication use in general and anticoagulant use in particular will be an unfulfilled ideal.
In Reply: I appreciate Dr. Henning’s letter in response to my editorial.1 Indeed, Dr. Eckman’s Atrial Fibrillation Decision Support Tool (AFDST) is useful for determining quality-adjusted life expectancy on or off anticoagulation, and could possibly help with shared decision-making in regard to anticoagulation.2–4
However, the AFDST does not incorporate personal preferences regarding anticoagulant or medication use in general. Many older adults are on too many medications (ie, polypharmacy) and wish to reduce their overall pill count.
A number of potential barriers to shared decision-making regarding medication use have been identified, including poor physician communication skills, the growing number of available medications, multiple prescribers for the same patient, lack of trust in the prescribing physician, and patients feeling that their preferences are not valued or important.5 Until communication and acceptance between prescribers and patients regarding possible medication choices improves, shared decision-making for medication use in general and anticoagulant use in particular will be an unfulfilled ideal.
- Suh TT. Whether to anticoagulate: toward a more reasoned approach. Cleve Clin J Med 2017; 84:41–42.
- Eckman MH, Lip GYH, Wise RE, et al. Impact of an atrial fibrillation decision support tool on thromboprophylaxis for atrial fibrillation. Am Heart J 2016; 176:17–27.
- Eckman MH, Wise RE, Speer B, et al. Integrating real-time clinical information to provide estimates of net clinical benefit antithrombotic therapy for patients with atrial fibrillation. Circ Cardiovasc Qual Outcomes 2014; 7:680–686.
- Eckman MH, Lip TYH, Wise RE, et al. Using an atrial fibrillation decision support tool for thromboprophylaxis in atrial fibrillation: effect of sex and age. J Am Geriatr Soc 2016; 64:1054–1060.
- Belcher VN, Fried TR, Agostini JV, Tinetti ME. Views of older adults on patient participation in medication-related decision making. J Gen Intern Med 2006; 21:298–303.
- Suh TT. Whether to anticoagulate: toward a more reasoned approach. Cleve Clin J Med 2017; 84:41–42.
- Eckman MH, Lip GYH, Wise RE, et al. Impact of an atrial fibrillation decision support tool on thromboprophylaxis for atrial fibrillation. Am Heart J 2016; 176:17–27.
- Eckman MH, Wise RE, Speer B, et al. Integrating real-time clinical information to provide estimates of net clinical benefit antithrombotic therapy for patients with atrial fibrillation. Circ Cardiovasc Qual Outcomes 2014; 7:680–686.
- Eckman MH, Lip TYH, Wise RE, et al. Using an atrial fibrillation decision support tool for thromboprophylaxis in atrial fibrillation: effect of sex and age. J Am Geriatr Soc 2016; 64:1054–1060.
- Belcher VN, Fried TR, Agostini JV, Tinetti ME. Views of older adults on patient participation in medication-related decision making. J Gen Intern Med 2006; 21:298–303.
Renal denervation: What happened, and why?
Many patients, clinicians, and researchers had hoped that renal denervation would help control resistant hypertension. However, in the SYMPLICITY HTN-3 trial,1 named for the catheter-based system used in the study (Symplicity RDN, Medtronic, Dublin, Ireland), this endovascular procedure failed to meet its primary and secondary efficacy end points, although it was found to be safe. These results were surprising, especially given the results of an earlier randomized trial (SYMPLICITY HTN-2),2 which showed larger reductions in blood pressures 6 months after denervation than in the current trial.
Here, we discuss the results of the SYMPLICITY HTN-3 trial and offer possible explanations for its negative outcomes.
LEAD-UP TO SYMPLICITY HTN-3
Renal denervation consists of passing a catheter through the femoral artery into the renal arteries and ablating their sympathetic nerves using radiofrequency energy. In theory, this should interrupt efferent sympathetic communication between the brain and renal arteries, reducing muscular contraction of these arteries, increasing renal blood flow, reducing activation of the renin-angiotensin-adosterone system, thus reducing sodium retention, reducing afferent sympathetic communication between the kidneys and brain, and in turn reducing further sympathetic activity elsewhere in the body, such as in the heart. Blood pressure should fall.3
The results of the SYMPLICITY HTN-1 and 2 trials were discussed in an earlier article in this Journal,3 and the Medtronic-Ardian renal denervation system has been available in Europe and Australia for clinical use for over 2 years.4 Indeed, after the SYMPLICITY HTN-2 results were published in 2010, Boston Scientific’s Vessix, St. Jude Medical’s EnligHTN, and Covidien’s OneShot radiofrequency renal denervation devices—albeit each with some modifications—received a Conformité Européene (CE) mark and became available in Europe and Australia for clinical use. These devices are not available for clinical use or research in the United States.3,5
Therefore, SYMPLICITY HTN-3, sponsored by Medtronic, was designed to obtain US Food and Drug Administration approval in the United States.6
SYMPLICITY HTN-3 DESIGN
Inclusion criteria were similar to those in the earlier SYMPLICITY trials. Patients had to have resistant hypertension, defined as a systolic blood pressure ≥ 160 mm Hg despite taking at least 3 blood pressure medications at maximum tolerated doses. Patients were excluded if they had a glomerular filtration rate of less than 45 mL/min/1.73 m2, renal artery stenosis, or known secondary hypertension.
A total of 1,441 patients were enrolled, of whom 364 were eventually randomized to undergo renal denervation, and 171 were randomized to undergo a sham procedure. The mean systolic blood pressure at baseline was 188 mm Hg in each group. Most patients were taking maximum doses of blood pressure medications, and almost one-fourth were taking an aldosterone antagonist. Patients in both groups were taking an average of 5 medications.
The 2 groups were well matched for important covariates, including obstructive sleep apnea, diabetes mellitus, and renal insufficiency. Most of the patients were white; 25% of the renal denervation group and 29% of the sham procedure group were black.
The physicians conducting the follow-up appointments did not know which procedure the patients underwent, and neither did the patients. Medications were closely monitored, and patients had close follow-up. The catheter (Symplicity RDS, Medtronic) was of the same design that was used in the earlier SYMPLICITY trials and in clinical practice in countries where renal denervation was available.
Researchers expected that the systolic blood pressure, as measured in the office, would fall in both groups, but they hoped it would fall farther in the denervation group—at least 5 mm Hg farther, the primary end point of the trial. The secondary effectiveness end point was a 2-mm Hg greater reduction in 24-hour ambulatory systolic blood pressure.
SYMPLICITY HTN-3 RESULTS
No statistically significant difference in safety was observed between the denervation and control groups. However, the procedure was associated with 1 embolic event and 1 case of renal artery stenosis.
Blood pressure fell in both groups. However, at 6 months, office systolic pressure had fallen by a mean of 14.13 mm Hg in the denervation group and 11.74 mm Hg in the sham procedure group, a difference of only 2.39 mm Hg. The mean ambulatory systolic blood pressure had fallen by 6.75 vs 4.79 mm Hg, a difference of only 1.96 mm Hg. Neither difference was statistically significant.
A number of prespecified subgroup analyses were conducted, but the benefit of the procedure was statistically significant in only 3 subgroups: patients who were not black (P = .01), patients who were less than 65 years old (P = .04), and patients who had an estimated glomerular filtration rate of 60 mL/min/1.73 m2 or higher (P = .05).
WHAT WENT WRONG?
The results of SYMPLICITY HTN-3 were disappointing and led companies that were developing renal denervation devices to discontinue or reevaluate their programs.
Although the results were surprising, many observers (including our group) raised concerns about the initial enthusiasm surrounding renal denervation.3–7 Indeed, in 2010, we had concerns about the discrepancy between office-based blood pressure measurements (the primary end point of all renal denervation trials) and ambulatory blood pressure measurements in SYMPLICITY HTN-2.7
The enthusiasm surrounding this procedure led to the publication of 2 consensus documents on this novel therapy based on only 1 small randomized controlled study (SYMPLICITY HTN-2).8,9 Renal denervation was even reported to be useful in other conditions involving the sympathorenal axis, including diabetes mellitus, metabolic syndrome, and obstructive sleep apnea, and also as a potential treatment adjunct in atrial fibrillation and other arrhythmias.5
What went wrong?
Shortcomings in trial design?
The trial was well designed. Both patients and operators were blinded to the procedure, and 24-hour ambulatory blood pressure monitoring was used. We presume that appropriate patients with resistant hypertension were enrolled—the mean baseline systolic blood pressure was 188 mm Hg, and patients in each group were taking an average of 5 medications.
On the other hand, true medication adherence is difficult to ascertain. Further, the term maximal “tolerated” doses of medications is vague, and we cannot rule out the possibility that some patients were enrolled who did not truly have resistant hypertension—they simply did not want to take medications.
Patients were required to be on a stable medication regimen before enrollment and, ideally, to not have any medication changes during the course of the study, but at least 40% of patients did require medication changes during the study. Additionally, it is unclear whether all patients underwent specific testing to rule out secondary hypertension, as this was done at the discretion of the treating physician.
First-generation catheters?
The same type of catheter was used as in the earlier SYMPLICITY trials, and it had been used in many patients in clinical practice in countries where the catheter is routinely available. It is unknown, however, whether newer multisite denervation devices would yield better results than the first-generation devices used in SYMPLICITY HTN-3. But even this would not explain the discrepancies in data between earlier trials and this trial.
Operator inexperience?
It has been suggested that operator inexperience may have played a role, but an analysis of operator volume did not find any association between this variable and the outcomes. Each procedure was supervised by at least 1 and in most cases 2 certified Medtronic representatives, who made certain that meticulous attention was paid to procedure details and that no shortcuts were taken during the procedure.
Inadequate ablation?
While we can assume that the correct technique was followed in most cases, renal denervation is still a “blind” procedure, and there is no nerve mapping to ascertain the degree of ablation achieved. Notably, patients who had the most ablations reportedly had a greater average drop in systolic ambulatory blood pressure than those who received fewer ablations. Sympathetic nervous system activity is a potential marker of adequacy of ablation, but it was not routinely assessed in the SYMPLICITY HTN-3 trial. Techniques to assess sympathetic nerve activity such as norepinephrine spillover and muscle sympathetic nerve activity are highly specialized and available only at a few research centers, and are not available for routine clinical use.
While these points may explain the negative findings of this trial, they fail to account for the discrepant results between this study and previous trials that used exactly the same definitions and techniques.
Patient demographics?
Is it possible that renal denervation has a differential effect according to race? All previous renal denervation studies were conducted in Europe or Australia; therefore, few data are available on the efficacy of the procedure in other racial groups, such as black Americans. Most of the patients in this trial were white, but approximately 25% were black—a good representation. There was a statistically significant benefit favoring renal denervation in nonblack (mostly white) patients, but not in black patients. This may be related to racial differences in the pathophysiology of hypertension or possibly due to chance alone.
A Hawthorne effect?
A Hawthorne effect (patients being more compliant because physicians are paying more attention to them) is unlikely, since the renal denervation arm did not have any reduction in blood pressure medications. At 6 months, both the sham group and the procedure group were still on an average of 5 medications.
Additionally, while the blood pressure reduction in both treatment groups was significant, the systolic blood pressure at 6 months was still 166 mm Hg in the denervation group and 168 mm Hg in the sham group. If denervation was effective, one would have expected a greater reduction in blood pressure or at least a decrease in the number of medications needed, eg, 1 to 2 fewer medications in the denervation group compared with the sham procedure group.
Regression to the mean?
It is unknown whether the results represent a statistical error such as regression to the mean. But given the run-in period and the confirmatory data from 24-hour ambulatory blood pressure, this would be unlikely.
WHAT NOW?
Is renal denervation dead? SYMPLICITY HTN-3 is only a single trial with multiple shortcomings and lessons to learn from. Since its publication, there have been updates from 2 prospective, randomized, open-label trials concerning the efficacy of catheter-based renal denervation in lowering blood pressure.10,11
DENERHTN (Renal Denervation for Hypertension)10 studied patients with ambulatory systolic blood pressure higher than 135 mm Hg, diastolic blood pressure higher than 80 mm Hg, or both (after excluding secondary etiologies), despite 4 weeks of standardized triple-drug treatment including a diuretic. Patients were randomized to standardized stepped-care antihypertensive treatment alone (control group) or standard care plus renal denervation. The latter resulted in a significant further reduction in ambulatory blood pressure at 6 months.
The Prague-15 trial11 studied patients with resistant hypertension. Secondary etiologies were excluded and adherence to therapy was confirmed by measuring plasma medication levels. It showed that renal denervation along with optimal antihypertensive medical therapy (unchanged after randomization) resulted in a significant reduction in ambulatory blood pressure that was comparable to the effect of intensified antihypertensive medical therapy including spironolactone. (Studies have shown that spironolactone is effective when added on as a fourth-line medication in resistant hypertension.12) At 6 months, patients in the intensive medical therapy group were using an average of 0.3 more antihypertensive medications than those in the procedure group.
These two trials addressed some of the drawbacks of the SYMPLICITY HTN-3 trial. However, both have many limitations including and not limited to being open-label and nonblinded, lacking a sham procedure, using a lower blood pressure threshold than SYMPLICITY HTN-3 did to define resistant hypertension, and using the same catheter as in the SYMPLICITY trials.
Better technology is coming

Advanced renal denervation catheters are needed that are multielectrode, smaller, easier to manipulate, and capable of providing simultaneous, circumferential, more-intense, and deeper ablations. The ongoing Investigator-Steered Project on Intravascular Renal Denervation for Management of Drug-Resistant Hypertension (INSPIRED)16 and Renal Denervation Using the Vessix Renal Denervation System for the Treatment of Hypertension (REDUCE-HTN: REINFORCE)17 trials are using contemporary innovative ablation catheters to address the limitations of the first-generation Symplicity catheter.
Further, Fischell et al18 reported encouraging results of renal denervation performed by injecting ethanol into the adventitial space of the renal arteries. This is still an invasive procedure; however, ethanol can spread out in all directions and reach all targeted nerves, potentially resulting in a more complete renal artery sympathetic ablation.
As technology advances, the WAVE IV trial19 is examining renal denervation performed from the outside through the skin using high-intensity focused ultrasound, which eliminates the need for femoral arterial catheterization, a promising noninvasive approach.
Proposals for future trials
The European Clinical Consensus Conference for Renal Denervation20 proposed that future trials of renal denervation include patients with moderate rather than resistant hypertension, reflecting the pathogenic importance of sympathetic activity in earlier stages of hypertension. The conference also proposed excluding patients with stiff large arteries, a cause of isolated systolic hypertension. Other proposals included standardizing concomitant antihypertensive therapy, preferably treating all patients with the combination of a renin-angiotensin system blocker, calcium channel blocker, and diuretic in the run-in period; monitoring drug adherence through the use of pill counts, electronic pill dispensers, and drug blood tests; and using change in ambulatory blood pressure as the primary efficacy end point and change in office blood pressure as a secondary end point.
Trials ongoing
To possibly address the limitations posed by the SYMPLICITY HTN-3 trial and to answer other important questions, several sham-controlled clinical trials of renal denervation are currently being conducted:
- INSPiRED16
- REDUCE-HTN: REINFORCE17
- Spyral HTN-Off Med21
- Spyral HTN-On Med21
- Study of the ReCor Medical Paradise System in Clinical Hypertension (RADIANCE-HTN).22
We hope these new studies can more clearly identify subsets of patients who would benefit from this technology, determine predictors of blood pressure reduction in such patients, and lead to newer devices that may provide more complete ablation.
Obviously, we also need better ways to identify the exact location of these sympathetic nerves within the renal artery and have a clearer sense of procedural success.
Until then, our colleagues in Europe and Australia continue to treat patients with this technology as we appropriately and patiently wait for level 1 clinical evidence of its efficacy.
Acknowledgments: We thank Kathryn Brock, BA, Editorial Services Manager, Heart and Vascular Institute, Cleveland Clinic, for her assistance in the preparation of this paper.
- Bhatt DL, Kandzari DE, O’Neill WW, et al, for the SYMPLICITY HTN-3 Investigators. A controlled trial of renal denervation for resistant hypertension. N Engl J Med 2014; 370:1393–1401.
- Symplicity HTN-2 Investigators, Esler MD, Krum H, Sobotka PA, Schlaich MP, Schmieder RE, Bohm M. Renal sympathetic denervation in patients with treatment-resistant hypertension (the Symplicity HTN-2 trial): a randomised controlled trial. Lancet 2010; 376:1903–1909.
- Bunte MC, Infante de Oliveira E, Shishehbor MH. Endovascular treatment of resistant and uncontrolled hypertension: therapies on the horizon. JACC Cardiovasc Interv 2013; 6:1–9.
- Thomas G, Shishehbor MH, Bravo EL, Nally JV. Renal denervation to treat resistant hypertension: guarded optimism. Cleve Clin J Med 2012; 79:501–510.
- Shishehbor MH, Bunte MC. Anatomical exclusion for renal denervation: are we putting the cart before the horse? JACC Cardiovasc Interv 2014; 7:193–194.
- Bhatt DL, Bakris GL. The promise of renal denervation. Cleve Clin J Med 2012; 79:498–500.
- Bunte MC. Renal sympathetic denervation for refractory hypertension. Lancet 2011; 377:1074; author reply 1075.
- Mahfoud F, Luscher TF, Andersson B, et al; European Society of Cardiology. Expert consensus document from the European Society of Cardiology on catheter-based renal denervation. Eur Heart J 2013; 34:2149–2157.
- Schlaich MP, Schmieder RE, Bakris G, et al. International expert consensus statement: percutaneous transluminal renal denervation for the treatment of resistant hypertension. J Am Coll Cardiol 2013; 62:2031–2045.
- Azizi M, Sapoval M, Gosse P, et al; Renal Denervation for Hypertension (DENERHTN) investigators. Optimum and stepped care standardised antihypertensive treatment with or without renal denervation for resistant hypertension (DENERHTN): a multicentre, open-label, randomised controlled trial. Lancet 2015; 385:1957–1965.
- Rosa J, Widimsky P, Tousek P, et al. Randomized comparison of renal denervation versus intensified pharmacotherapy including spironolactone in true-resistant hypertension: six-month results from the Prague-15 study. Hypertension 2015; 65:407–413.
- Williams B, MacDonald TM, Morant S, et al; British Hypertension Society’s PATHWAY Studies Group. Spironolactone versus placebo, bisoprolol, and doxazosin to determine the optimal treatment for drug-resistant hypertension (PATHWAY-2): a randomised, double-blind, crossover trial. Lancet 2015; 386:2059–2068.
- Sakakura K, Ladich E, Cheng Q, et al. Anatomic assessment of sympathetic peri-arterial renal nerves in man. J Am Coll Cardiol 2014; 64:635–643.
- Mahfoud F, Edelman ER, Bohm M. Catheter-based renal denervation is no simple matter: lessons to be learned from our anatomy? J Am Coll Cardiol 2014; 64:644–646.
- Id D, Kaltenbach B, Bertog SC, et al. Does the presence of accessory renal arteries affect the efficacy of renal denervation? JACC Cardiovasc Interv 2013; 6:1085–1091.
- Jin Y, Jacobs L, Baelen M, et al; Investigator-Steered Project on Intravascular Renal Denervation for Management of Drug-Resistant Hypertension (Inspired) Investigators. Rationale and design of the Investigator-Steered Project on Intravascular Renal Denervation for Management of Drug-Resistant Hypertension (INSPiRED) trial. Blood Press 2014; 23:138–146.
- ClinicalTrialsgov. Renal Denervation Using the Vessix Renal Denervation System for the Treatment of Hypertension (REDUCE HTN: REINFORCE). https://clinicaltrials.gov/ct2/show/NCT02392351?term=REDUCE-HTN%3A+REINFORCE&rank=1. Accessed August 3, 2017.
- Fischell TA, Ebner A, Gallo S, et al. Transcatheter alcohol-mediated perivascular renal denervation with the peregrine system: first-in-human experience. JACC Cardiovasc Interv 2016; 9:589–598.
- ClinicalTrialsgov. Sham controlled study of renal denervation for subjects with uncontrolled hypertension (WAVE_IV) (NCT02029885). https://clinicaltrials.gov/ct2/show/results/NCT02029885. Accessed August 3, 2017.
- Mahfoud F, Bohm M, Azizi M, et al. Proceedings from the European clinical consensus conference for renal denervation: considerations on future clinical trial design. Eur Heart J 2015; 36:2219–2227.
- Kandzari DE, Kario K, Mahfoud F, et al. The SPYRAL HTN Global Clinical Trial Program: rationale and design for studies of renal denervation in the absence (SPYRAL HTN OFF-MED) and presence (SPYRAL HTN ON-MED) of antihypertensive medications. Am Heart J 2016; 171:82–91.
- ClinicalTrialsgov. A Study of the ReCor Medical Paradise System in Clinical Hypertension (RADIANCE-HTN). https://clinicaltrials.gov/ct2/show/NCT02649426?term=RADIANCE&rank=3. Accessed August 3, 2017.
Many patients, clinicians, and researchers had hoped that renal denervation would help control resistant hypertension. However, in the SYMPLICITY HTN-3 trial,1 named for the catheter-based system used in the study (Symplicity RDN, Medtronic, Dublin, Ireland), this endovascular procedure failed to meet its primary and secondary efficacy end points, although it was found to be safe. These results were surprising, especially given the results of an earlier randomized trial (SYMPLICITY HTN-2),2 which showed larger reductions in blood pressures 6 months after denervation than in the current trial.
Here, we discuss the results of the SYMPLICITY HTN-3 trial and offer possible explanations for its negative outcomes.
LEAD-UP TO SYMPLICITY HTN-3
Renal denervation consists of passing a catheter through the femoral artery into the renal arteries and ablating their sympathetic nerves using radiofrequency energy. In theory, this should interrupt efferent sympathetic communication between the brain and renal arteries, reducing muscular contraction of these arteries, increasing renal blood flow, reducing activation of the renin-angiotensin-adosterone system, thus reducing sodium retention, reducing afferent sympathetic communication between the kidneys and brain, and in turn reducing further sympathetic activity elsewhere in the body, such as in the heart. Blood pressure should fall.3
The results of the SYMPLICITY HTN-1 and 2 trials were discussed in an earlier article in this Journal,3 and the Medtronic-Ardian renal denervation system has been available in Europe and Australia for clinical use for over 2 years.4 Indeed, after the SYMPLICITY HTN-2 results were published in 2010, Boston Scientific’s Vessix, St. Jude Medical’s EnligHTN, and Covidien’s OneShot radiofrequency renal denervation devices—albeit each with some modifications—received a Conformité Européene (CE) mark and became available in Europe and Australia for clinical use. These devices are not available for clinical use or research in the United States.3,5
Therefore, SYMPLICITY HTN-3, sponsored by Medtronic, was designed to obtain US Food and Drug Administration approval in the United States.6
SYMPLICITY HTN-3 DESIGN
Inclusion criteria were similar to those in the earlier SYMPLICITY trials. Patients had to have resistant hypertension, defined as a systolic blood pressure ≥ 160 mm Hg despite taking at least 3 blood pressure medications at maximum tolerated doses. Patients were excluded if they had a glomerular filtration rate of less than 45 mL/min/1.73 m2, renal artery stenosis, or known secondary hypertension.
A total of 1,441 patients were enrolled, of whom 364 were eventually randomized to undergo renal denervation, and 171 were randomized to undergo a sham procedure. The mean systolic blood pressure at baseline was 188 mm Hg in each group. Most patients were taking maximum doses of blood pressure medications, and almost one-fourth were taking an aldosterone antagonist. Patients in both groups were taking an average of 5 medications.
The 2 groups were well matched for important covariates, including obstructive sleep apnea, diabetes mellitus, and renal insufficiency. Most of the patients were white; 25% of the renal denervation group and 29% of the sham procedure group were black.
The physicians conducting the follow-up appointments did not know which procedure the patients underwent, and neither did the patients. Medications were closely monitored, and patients had close follow-up. The catheter (Symplicity RDS, Medtronic) was of the same design that was used in the earlier SYMPLICITY trials and in clinical practice in countries where renal denervation was available.
Researchers expected that the systolic blood pressure, as measured in the office, would fall in both groups, but they hoped it would fall farther in the denervation group—at least 5 mm Hg farther, the primary end point of the trial. The secondary effectiveness end point was a 2-mm Hg greater reduction in 24-hour ambulatory systolic blood pressure.
SYMPLICITY HTN-3 RESULTS
No statistically significant difference in safety was observed between the denervation and control groups. However, the procedure was associated with 1 embolic event and 1 case of renal artery stenosis.
Blood pressure fell in both groups. However, at 6 months, office systolic pressure had fallen by a mean of 14.13 mm Hg in the denervation group and 11.74 mm Hg in the sham procedure group, a difference of only 2.39 mm Hg. The mean ambulatory systolic blood pressure had fallen by 6.75 vs 4.79 mm Hg, a difference of only 1.96 mm Hg. Neither difference was statistically significant.
A number of prespecified subgroup analyses were conducted, but the benefit of the procedure was statistically significant in only 3 subgroups: patients who were not black (P = .01), patients who were less than 65 years old (P = .04), and patients who had an estimated glomerular filtration rate of 60 mL/min/1.73 m2 or higher (P = .05).
WHAT WENT WRONG?
The results of SYMPLICITY HTN-3 were disappointing and led companies that were developing renal denervation devices to discontinue or reevaluate their programs.
Although the results were surprising, many observers (including our group) raised concerns about the initial enthusiasm surrounding renal denervation.3–7 Indeed, in 2010, we had concerns about the discrepancy between office-based blood pressure measurements (the primary end point of all renal denervation trials) and ambulatory blood pressure measurements in SYMPLICITY HTN-2.7
The enthusiasm surrounding this procedure led to the publication of 2 consensus documents on this novel therapy based on only 1 small randomized controlled study (SYMPLICITY HTN-2).8,9 Renal denervation was even reported to be useful in other conditions involving the sympathorenal axis, including diabetes mellitus, metabolic syndrome, and obstructive sleep apnea, and also as a potential treatment adjunct in atrial fibrillation and other arrhythmias.5
What went wrong?
Shortcomings in trial design?
The trial was well designed. Both patients and operators were blinded to the procedure, and 24-hour ambulatory blood pressure monitoring was used. We presume that appropriate patients with resistant hypertension were enrolled—the mean baseline systolic blood pressure was 188 mm Hg, and patients in each group were taking an average of 5 medications.
On the other hand, true medication adherence is difficult to ascertain. Further, the term maximal “tolerated” doses of medications is vague, and we cannot rule out the possibility that some patients were enrolled who did not truly have resistant hypertension—they simply did not want to take medications.
Patients were required to be on a stable medication regimen before enrollment and, ideally, to not have any medication changes during the course of the study, but at least 40% of patients did require medication changes during the study. Additionally, it is unclear whether all patients underwent specific testing to rule out secondary hypertension, as this was done at the discretion of the treating physician.
First-generation catheters?
The same type of catheter was used as in the earlier SYMPLICITY trials, and it had been used in many patients in clinical practice in countries where the catheter is routinely available. It is unknown, however, whether newer multisite denervation devices would yield better results than the first-generation devices used in SYMPLICITY HTN-3. But even this would not explain the discrepancies in data between earlier trials and this trial.
Operator inexperience?
It has been suggested that operator inexperience may have played a role, but an analysis of operator volume did not find any association between this variable and the outcomes. Each procedure was supervised by at least 1 and in most cases 2 certified Medtronic representatives, who made certain that meticulous attention was paid to procedure details and that no shortcuts were taken during the procedure.
Inadequate ablation?
While we can assume that the correct technique was followed in most cases, renal denervation is still a “blind” procedure, and there is no nerve mapping to ascertain the degree of ablation achieved. Notably, patients who had the most ablations reportedly had a greater average drop in systolic ambulatory blood pressure than those who received fewer ablations. Sympathetic nervous system activity is a potential marker of adequacy of ablation, but it was not routinely assessed in the SYMPLICITY HTN-3 trial. Techniques to assess sympathetic nerve activity such as norepinephrine spillover and muscle sympathetic nerve activity are highly specialized and available only at a few research centers, and are not available for routine clinical use.
While these points may explain the negative findings of this trial, they fail to account for the discrepant results between this study and previous trials that used exactly the same definitions and techniques.
Patient demographics?
Is it possible that renal denervation has a differential effect according to race? All previous renal denervation studies were conducted in Europe or Australia; therefore, few data are available on the efficacy of the procedure in other racial groups, such as black Americans. Most of the patients in this trial were white, but approximately 25% were black—a good representation. There was a statistically significant benefit favoring renal denervation in nonblack (mostly white) patients, but not in black patients. This may be related to racial differences in the pathophysiology of hypertension or possibly due to chance alone.
A Hawthorne effect?
A Hawthorne effect (patients being more compliant because physicians are paying more attention to them) is unlikely, since the renal denervation arm did not have any reduction in blood pressure medications. At 6 months, both the sham group and the procedure group were still on an average of 5 medications.
Additionally, while the blood pressure reduction in both treatment groups was significant, the systolic blood pressure at 6 months was still 166 mm Hg in the denervation group and 168 mm Hg in the sham group. If denervation was effective, one would have expected a greater reduction in blood pressure or at least a decrease in the number of medications needed, eg, 1 to 2 fewer medications in the denervation group compared with the sham procedure group.
Regression to the mean?
It is unknown whether the results represent a statistical error such as regression to the mean. But given the run-in period and the confirmatory data from 24-hour ambulatory blood pressure, this would be unlikely.
WHAT NOW?
Is renal denervation dead? SYMPLICITY HTN-3 is only a single trial with multiple shortcomings and lessons to learn from. Since its publication, there have been updates from 2 prospective, randomized, open-label trials concerning the efficacy of catheter-based renal denervation in lowering blood pressure.10,11
DENERHTN (Renal Denervation for Hypertension)10 studied patients with ambulatory systolic blood pressure higher than 135 mm Hg, diastolic blood pressure higher than 80 mm Hg, or both (after excluding secondary etiologies), despite 4 weeks of standardized triple-drug treatment including a diuretic. Patients were randomized to standardized stepped-care antihypertensive treatment alone (control group) or standard care plus renal denervation. The latter resulted in a significant further reduction in ambulatory blood pressure at 6 months.
The Prague-15 trial11 studied patients with resistant hypertension. Secondary etiologies were excluded and adherence to therapy was confirmed by measuring plasma medication levels. It showed that renal denervation along with optimal antihypertensive medical therapy (unchanged after randomization) resulted in a significant reduction in ambulatory blood pressure that was comparable to the effect of intensified antihypertensive medical therapy including spironolactone. (Studies have shown that spironolactone is effective when added on as a fourth-line medication in resistant hypertension.12) At 6 months, patients in the intensive medical therapy group were using an average of 0.3 more antihypertensive medications than those in the procedure group.
These two trials addressed some of the drawbacks of the SYMPLICITY HTN-3 trial. However, both have many limitations including and not limited to being open-label and nonblinded, lacking a sham procedure, using a lower blood pressure threshold than SYMPLICITY HTN-3 did to define resistant hypertension, and using the same catheter as in the SYMPLICITY trials.
Better technology is coming
Advanced renal denervation catheters are needed that are multielectrode, smaller, easier to manipulate, and capable of providing simultaneous, circumferential, more-intense, and deeper ablations. The ongoing Investigator-Steered Project on Intravascular Renal Denervation for Management of Drug-Resistant Hypertension (INSPIRED)16 and Renal Denervation Using the Vessix Renal Denervation System for the Treatment of Hypertension (REDUCE-HTN: REINFORCE)17 trials are using contemporary innovative ablation catheters to address the limitations of the first-generation Symplicity catheter.
Further, Fischell et al18 reported encouraging results of renal denervation performed by injecting ethanol into the adventitial space of the renal arteries. This is still an invasive procedure; however, ethanol can spread out in all directions and reach all targeted nerves, potentially resulting in a more complete renal artery sympathetic ablation.
As technology advances, the WAVE IV trial19 is examining renal denervation performed from the outside through the skin using high-intensity focused ultrasound, which eliminates the need for femoral arterial catheterization, a promising noninvasive approach.
Proposals for future trials
The European Clinical Consensus Conference for Renal Denervation20 proposed that future trials of renal denervation include patients with moderate rather than resistant hypertension, reflecting the pathogenic importance of sympathetic activity in earlier stages of hypertension. The conference also proposed excluding patients with stiff large arteries, a cause of isolated systolic hypertension. Other proposals included standardizing concomitant antihypertensive therapy, preferably treating all patients with the combination of a renin-angiotensin system blocker, calcium channel blocker, and diuretic in the run-in period; monitoring drug adherence through the use of pill counts, electronic pill dispensers, and drug blood tests; and using change in ambulatory blood pressure as the primary efficacy end point and change in office blood pressure as a secondary end point.
Trials ongoing
To possibly address the limitations posed by the SYMPLICITY HTN-3 trial and to answer other important questions, several sham-controlled clinical trials of renal denervation are currently being conducted:
- INSPiRED16
- REDUCE-HTN: REINFORCE17
- Spyral HTN-Off Med21
- Spyral HTN-On Med21
- Study of the ReCor Medical Paradise System in Clinical Hypertension (RADIANCE-HTN).22
We hope these new studies can more clearly identify subsets of patients who would benefit from this technology, determine predictors of blood pressure reduction in such patients, and lead to newer devices that may provide more complete ablation.
Obviously, we also need better ways to identify the exact location of these sympathetic nerves within the renal artery and have a clearer sense of procedural success.
Until then, our colleagues in Europe and Australia continue to treat patients with this technology as we appropriately and patiently wait for level 1 clinical evidence of its efficacy.
Acknowledgments: We thank Kathryn Brock, BA, Editorial Services Manager, Heart and Vascular Institute, Cleveland Clinic, for her assistance in the preparation of this paper.
Many patients, clinicians, and researchers had hoped that renal denervation would help control resistant hypertension. However, in the SYMPLICITY HTN-3 trial,1 named for the catheter-based system used in the study (Symplicity RDN, Medtronic, Dublin, Ireland), this endovascular procedure failed to meet its primary and secondary efficacy end points, although it was found to be safe. These results were surprising, especially given the results of an earlier randomized trial (SYMPLICITY HTN-2),2 which showed larger reductions in blood pressures 6 months after denervation than in the current trial.
Here, we discuss the results of the SYMPLICITY HTN-3 trial and offer possible explanations for its negative outcomes.
LEAD-UP TO SYMPLICITY HTN-3
Renal denervation consists of passing a catheter through the femoral artery into the renal arteries and ablating their sympathetic nerves using radiofrequency energy. In theory, this should interrupt efferent sympathetic communication between the brain and renal arteries, reducing muscular contraction of these arteries, increasing renal blood flow, reducing activation of the renin-angiotensin-adosterone system, thus reducing sodium retention, reducing afferent sympathetic communication between the kidneys and brain, and in turn reducing further sympathetic activity elsewhere in the body, such as in the heart. Blood pressure should fall.3
The results of the SYMPLICITY HTN-1 and 2 trials were discussed in an earlier article in this Journal,3 and the Medtronic-Ardian renal denervation system has been available in Europe and Australia for clinical use for over 2 years.4 Indeed, after the SYMPLICITY HTN-2 results were published in 2010, Boston Scientific’s Vessix, St. Jude Medical’s EnligHTN, and Covidien’s OneShot radiofrequency renal denervation devices—albeit each with some modifications—received a Conformité Européene (CE) mark and became available in Europe and Australia for clinical use. These devices are not available for clinical use or research in the United States.3,5
Therefore, SYMPLICITY HTN-3, sponsored by Medtronic, was designed to obtain US Food and Drug Administration approval in the United States.6
SYMPLICITY HTN-3 DESIGN
Inclusion criteria were similar to those in the earlier SYMPLICITY trials. Patients had to have resistant hypertension, defined as a systolic blood pressure ≥ 160 mm Hg despite taking at least 3 blood pressure medications at maximum tolerated doses. Patients were excluded if they had a glomerular filtration rate of less than 45 mL/min/1.73 m2, renal artery stenosis, or known secondary hypertension.
A total of 1,441 patients were enrolled, of whom 364 were eventually randomized to undergo renal denervation, and 171 were randomized to undergo a sham procedure. The mean systolic blood pressure at baseline was 188 mm Hg in each group. Most patients were taking maximum doses of blood pressure medications, and almost one-fourth were taking an aldosterone antagonist. Patients in both groups were taking an average of 5 medications.
The 2 groups were well matched for important covariates, including obstructive sleep apnea, diabetes mellitus, and renal insufficiency. Most of the patients were white; 25% of the renal denervation group and 29% of the sham procedure group were black.
The physicians conducting the follow-up appointments did not know which procedure the patients underwent, and neither did the patients. Medications were closely monitored, and patients had close follow-up. The catheter (Symplicity RDS, Medtronic) was of the same design that was used in the earlier SYMPLICITY trials and in clinical practice in countries where renal denervation was available.
Researchers expected that the systolic blood pressure, as measured in the office, would fall in both groups, but they hoped it would fall farther in the denervation group—at least 5 mm Hg farther, the primary end point of the trial. The secondary effectiveness end point was a 2-mm Hg greater reduction in 24-hour ambulatory systolic blood pressure.
SYMPLICITY HTN-3 RESULTS
No statistically significant difference in safety was observed between the denervation and control groups. However, the procedure was associated with 1 embolic event and 1 case of renal artery stenosis.
Blood pressure fell in both groups. However, at 6 months, office systolic pressure had fallen by a mean of 14.13 mm Hg in the denervation group and 11.74 mm Hg in the sham procedure group, a difference of only 2.39 mm Hg. The mean ambulatory systolic blood pressure had fallen by 6.75 vs 4.79 mm Hg, a difference of only 1.96 mm Hg. Neither difference was statistically significant.
A number of prespecified subgroup analyses were conducted, but the benefit of the procedure was statistically significant in only 3 subgroups: patients who were not black (P = .01), patients who were less than 65 years old (P = .04), and patients who had an estimated glomerular filtration rate of 60 mL/min/1.73 m2 or higher (P = .05).
WHAT WENT WRONG?
The results of SYMPLICITY HTN-3 were disappointing and led companies that were developing renal denervation devices to discontinue or reevaluate their programs.
Although the results were surprising, many observers (including our group) raised concerns about the initial enthusiasm surrounding renal denervation.3–7 Indeed, in 2010, we had concerns about the discrepancy between office-based blood pressure measurements (the primary end point of all renal denervation trials) and ambulatory blood pressure measurements in SYMPLICITY HTN-2.7
The enthusiasm surrounding this procedure led to the publication of 2 consensus documents on this novel therapy based on only 1 small randomized controlled study (SYMPLICITY HTN-2).8,9 Renal denervation was even reported to be useful in other conditions involving the sympathorenal axis, including diabetes mellitus, metabolic syndrome, and obstructive sleep apnea, and also as a potential treatment adjunct in atrial fibrillation and other arrhythmias.5
What went wrong?
Shortcomings in trial design?
The trial was well designed. Both patients and operators were blinded to the procedure, and 24-hour ambulatory blood pressure monitoring was used. We presume that appropriate patients with resistant hypertension were enrolled—the mean baseline systolic blood pressure was 188 mm Hg, and patients in each group were taking an average of 5 medications.
On the other hand, true medication adherence is difficult to ascertain. Further, the term maximal “tolerated” doses of medications is vague, and we cannot rule out the possibility that some patients were enrolled who did not truly have resistant hypertension—they simply did not want to take medications.
Patients were required to be on a stable medication regimen before enrollment and, ideally, to not have any medication changes during the course of the study, but at least 40% of patients did require medication changes during the study. Additionally, it is unclear whether all patients underwent specific testing to rule out secondary hypertension, as this was done at the discretion of the treating physician.
First-generation catheters?
The same type of catheter was used as in the earlier SYMPLICITY trials, and it had been used in many patients in clinical practice in countries where the catheter is routinely available. It is unknown, however, whether newer multisite denervation devices would yield better results than the first-generation devices used in SYMPLICITY HTN-3. But even this would not explain the discrepancies in data between earlier trials and this trial.
Operator inexperience?
It has been suggested that operator inexperience may have played a role, but an analysis of operator volume did not find any association between this variable and the outcomes. Each procedure was supervised by at least 1 and in most cases 2 certified Medtronic representatives, who made certain that meticulous attention was paid to procedure details and that no shortcuts were taken during the procedure.
Inadequate ablation?
While we can assume that the correct technique was followed in most cases, renal denervation is still a “blind” procedure, and there is no nerve mapping to ascertain the degree of ablation achieved. Notably, patients who had the most ablations reportedly had a greater average drop in systolic ambulatory blood pressure than those who received fewer ablations. Sympathetic nervous system activity is a potential marker of adequacy of ablation, but it was not routinely assessed in the SYMPLICITY HTN-3 trial. Techniques to assess sympathetic nerve activity such as norepinephrine spillover and muscle sympathetic nerve activity are highly specialized and available only at a few research centers, and are not available for routine clinical use.
While these points may explain the negative findings of this trial, they fail to account for the discrepant results between this study and previous trials that used exactly the same definitions and techniques.
Patient demographics?
Is it possible that renal denervation has a differential effect according to race? All previous renal denervation studies were conducted in Europe or Australia; therefore, few data are available on the efficacy of the procedure in other racial groups, such as black Americans. Most of the patients in this trial were white, but approximately 25% were black—a good representation. There was a statistically significant benefit favoring renal denervation in nonblack (mostly white) patients, but not in black patients. This may be related to racial differences in the pathophysiology of hypertension or possibly due to chance alone.
A Hawthorne effect?
A Hawthorne effect (patients being more compliant because physicians are paying more attention to them) is unlikely, since the renal denervation arm did not have any reduction in blood pressure medications. At 6 months, both the sham group and the procedure group were still on an average of 5 medications.
Additionally, while the blood pressure reduction in both treatment groups was significant, the systolic blood pressure at 6 months was still 166 mm Hg in the denervation group and 168 mm Hg in the sham group. If denervation was effective, one would have expected a greater reduction in blood pressure or at least a decrease in the number of medications needed, eg, 1 to 2 fewer medications in the denervation group compared with the sham procedure group.
Regression to the mean?
It is unknown whether the results represent a statistical error such as regression to the mean. But given the run-in period and the confirmatory data from 24-hour ambulatory blood pressure, this would be unlikely.
WHAT NOW?
Is renal denervation dead? SYMPLICITY HTN-3 is only a single trial with multiple shortcomings and lessons to learn from. Since its publication, there have been updates from 2 prospective, randomized, open-label trials concerning the efficacy of catheter-based renal denervation in lowering blood pressure.10,11
DENERHTN (Renal Denervation for Hypertension)10 studied patients with ambulatory systolic blood pressure higher than 135 mm Hg, diastolic blood pressure higher than 80 mm Hg, or both (after excluding secondary etiologies), despite 4 weeks of standardized triple-drug treatment including a diuretic. Patients were randomized to standardized stepped-care antihypertensive treatment alone (control group) or standard care plus renal denervation. The latter resulted in a significant further reduction in ambulatory blood pressure at 6 months.
The Prague-15 trial11 studied patients with resistant hypertension. Secondary etiologies were excluded and adherence to therapy was confirmed by measuring plasma medication levels. It showed that renal denervation along with optimal antihypertensive medical therapy (unchanged after randomization) resulted in a significant reduction in ambulatory blood pressure that was comparable to the effect of intensified antihypertensive medical therapy including spironolactone. (Studies have shown that spironolactone is effective when added on as a fourth-line medication in resistant hypertension.12) At 6 months, patients in the intensive medical therapy group were using an average of 0.3 more antihypertensive medications than those in the procedure group.
These two trials addressed some of the drawbacks of the SYMPLICITY HTN-3 trial. However, both have many limitations including and not limited to being open-label and nonblinded, lacking a sham procedure, using a lower blood pressure threshold than SYMPLICITY HTN-3 did to define resistant hypertension, and using the same catheter as in the SYMPLICITY trials.
Better technology is coming
Advanced renal denervation catheters are needed that are multielectrode, smaller, easier to manipulate, and capable of providing simultaneous, circumferential, more-intense, and deeper ablations. The ongoing Investigator-Steered Project on Intravascular Renal Denervation for Management of Drug-Resistant Hypertension (INSPIRED)16 and Renal Denervation Using the Vessix Renal Denervation System for the Treatment of Hypertension (REDUCE-HTN: REINFORCE)17 trials are using contemporary innovative ablation catheters to address the limitations of the first-generation Symplicity catheter.
Further, Fischell et al18 reported encouraging results of renal denervation performed by injecting ethanol into the adventitial space of the renal arteries. This is still an invasive procedure; however, ethanol can spread out in all directions and reach all targeted nerves, potentially resulting in a more complete renal artery sympathetic ablation.
As technology advances, the WAVE IV trial19 is examining renal denervation performed from the outside through the skin using high-intensity focused ultrasound, which eliminates the need for femoral arterial catheterization, a promising noninvasive approach.
Proposals for future trials
The European Clinical Consensus Conference for Renal Denervation20 proposed that future trials of renal denervation include patients with moderate rather than resistant hypertension, reflecting the pathogenic importance of sympathetic activity in earlier stages of hypertension. The conference also proposed excluding patients with stiff large arteries, a cause of isolated systolic hypertension. Other proposals included standardizing concomitant antihypertensive therapy, preferably treating all patients with the combination of a renin-angiotensin system blocker, calcium channel blocker, and diuretic in the run-in period; monitoring drug adherence through the use of pill counts, electronic pill dispensers, and drug blood tests; and using change in ambulatory blood pressure as the primary efficacy end point and change in office blood pressure as a secondary end point.
Trials ongoing
To possibly address the limitations posed by the SYMPLICITY HTN-3 trial and to answer other important questions, several sham-controlled clinical trials of renal denervation are currently being conducted:
- INSPiRED16
- REDUCE-HTN: REINFORCE17
- Spyral HTN-Off Med21
- Spyral HTN-On Med21
- Study of the ReCor Medical Paradise System in Clinical Hypertension (RADIANCE-HTN).22
We hope these new studies can more clearly identify subsets of patients who would benefit from this technology, determine predictors of blood pressure reduction in such patients, and lead to newer devices that may provide more complete ablation.
Obviously, we also need better ways to identify the exact location of these sympathetic nerves within the renal artery and have a clearer sense of procedural success.
Until then, our colleagues in Europe and Australia continue to treat patients with this technology as we appropriately and patiently wait for level 1 clinical evidence of its efficacy.
Acknowledgments: We thank Kathryn Brock, BA, Editorial Services Manager, Heart and Vascular Institute, Cleveland Clinic, for her assistance in the preparation of this paper.
- Bhatt DL, Kandzari DE, O’Neill WW, et al, for the SYMPLICITY HTN-3 Investigators. A controlled trial of renal denervation for resistant hypertension. N Engl J Med 2014; 370:1393–1401.
- Symplicity HTN-2 Investigators, Esler MD, Krum H, Sobotka PA, Schlaich MP, Schmieder RE, Bohm M. Renal sympathetic denervation in patients with treatment-resistant hypertension (the Symplicity HTN-2 trial): a randomised controlled trial. Lancet 2010; 376:1903–1909.
- Bunte MC, Infante de Oliveira E, Shishehbor MH. Endovascular treatment of resistant and uncontrolled hypertension: therapies on the horizon. JACC Cardiovasc Interv 2013; 6:1–9.
- Thomas G, Shishehbor MH, Bravo EL, Nally JV. Renal denervation to treat resistant hypertension: guarded optimism. Cleve Clin J Med 2012; 79:501–510.
- Shishehbor MH, Bunte MC. Anatomical exclusion for renal denervation: are we putting the cart before the horse? JACC Cardiovasc Interv 2014; 7:193–194.
- Bhatt DL, Bakris GL. The promise of renal denervation. Cleve Clin J Med 2012; 79:498–500.
- Bunte MC. Renal sympathetic denervation for refractory hypertension. Lancet 2011; 377:1074; author reply 1075.
- Mahfoud F, Luscher TF, Andersson B, et al; European Society of Cardiology. Expert consensus document from the European Society of Cardiology on catheter-based renal denervation. Eur Heart J 2013; 34:2149–2157.
- Schlaich MP, Schmieder RE, Bakris G, et al. International expert consensus statement: percutaneous transluminal renal denervation for the treatment of resistant hypertension. J Am Coll Cardiol 2013; 62:2031–2045.
- Azizi M, Sapoval M, Gosse P, et al; Renal Denervation for Hypertension (DENERHTN) investigators. Optimum and stepped care standardised antihypertensive treatment with or without renal denervation for resistant hypertension (DENERHTN): a multicentre, open-label, randomised controlled trial. Lancet 2015; 385:1957–1965.
- Rosa J, Widimsky P, Tousek P, et al. Randomized comparison of renal denervation versus intensified pharmacotherapy including spironolactone in true-resistant hypertension: six-month results from the Prague-15 study. Hypertension 2015; 65:407–413.
- Williams B, MacDonald TM, Morant S, et al; British Hypertension Society’s PATHWAY Studies Group. Spironolactone versus placebo, bisoprolol, and doxazosin to determine the optimal treatment for drug-resistant hypertension (PATHWAY-2): a randomised, double-blind, crossover trial. Lancet 2015; 386:2059–2068.
- Sakakura K, Ladich E, Cheng Q, et al. Anatomic assessment of sympathetic peri-arterial renal nerves in man. J Am Coll Cardiol 2014; 64:635–643.
- Mahfoud F, Edelman ER, Bohm M. Catheter-based renal denervation is no simple matter: lessons to be learned from our anatomy? J Am Coll Cardiol 2014; 64:644–646.
- Id D, Kaltenbach B, Bertog SC, et al. Does the presence of accessory renal arteries affect the efficacy of renal denervation? JACC Cardiovasc Interv 2013; 6:1085–1091.
- Jin Y, Jacobs L, Baelen M, et al; Investigator-Steered Project on Intravascular Renal Denervation for Management of Drug-Resistant Hypertension (Inspired) Investigators. Rationale and design of the Investigator-Steered Project on Intravascular Renal Denervation for Management of Drug-Resistant Hypertension (INSPiRED) trial. Blood Press 2014; 23:138–146.
- ClinicalTrialsgov. Renal Denervation Using the Vessix Renal Denervation System for the Treatment of Hypertension (REDUCE HTN: REINFORCE). https://clinicaltrials.gov/ct2/show/NCT02392351?term=REDUCE-HTN%3A+REINFORCE&rank=1. Accessed August 3, 2017.
- Fischell TA, Ebner A, Gallo S, et al. Transcatheter alcohol-mediated perivascular renal denervation with the peregrine system: first-in-human experience. JACC Cardiovasc Interv 2016; 9:589–598.
- ClinicalTrialsgov. Sham controlled study of renal denervation for subjects with uncontrolled hypertension (WAVE_IV) (NCT02029885). https://clinicaltrials.gov/ct2/show/results/NCT02029885. Accessed August 3, 2017.
- Mahfoud F, Bohm M, Azizi M, et al. Proceedings from the European clinical consensus conference for renal denervation: considerations on future clinical trial design. Eur Heart J 2015; 36:2219–2227.
- Kandzari DE, Kario K, Mahfoud F, et al. The SPYRAL HTN Global Clinical Trial Program: rationale and design for studies of renal denervation in the absence (SPYRAL HTN OFF-MED) and presence (SPYRAL HTN ON-MED) of antihypertensive medications. Am Heart J 2016; 171:82–91.
- ClinicalTrialsgov. A Study of the ReCor Medical Paradise System in Clinical Hypertension (RADIANCE-HTN). https://clinicaltrials.gov/ct2/show/NCT02649426?term=RADIANCE&rank=3. Accessed August 3, 2017.
- Bhatt DL, Kandzari DE, O’Neill WW, et al, for the SYMPLICITY HTN-3 Investigators. A controlled trial of renal denervation for resistant hypertension. N Engl J Med 2014; 370:1393–1401.
- Symplicity HTN-2 Investigators, Esler MD, Krum H, Sobotka PA, Schlaich MP, Schmieder RE, Bohm M. Renal sympathetic denervation in patients with treatment-resistant hypertension (the Symplicity HTN-2 trial): a randomised controlled trial. Lancet 2010; 376:1903–1909.
- Bunte MC, Infante de Oliveira E, Shishehbor MH. Endovascular treatment of resistant and uncontrolled hypertension: therapies on the horizon. JACC Cardiovasc Interv 2013; 6:1–9.
- Thomas G, Shishehbor MH, Bravo EL, Nally JV. Renal denervation to treat resistant hypertension: guarded optimism. Cleve Clin J Med 2012; 79:501–510.
- Shishehbor MH, Bunte MC. Anatomical exclusion for renal denervation: are we putting the cart before the horse? JACC Cardiovasc Interv 2014; 7:193–194.
- Bhatt DL, Bakris GL. The promise of renal denervation. Cleve Clin J Med 2012; 79:498–500.
- Bunte MC. Renal sympathetic denervation for refractory hypertension. Lancet 2011; 377:1074; author reply 1075.
- Mahfoud F, Luscher TF, Andersson B, et al; European Society of Cardiology. Expert consensus document from the European Society of Cardiology on catheter-based renal denervation. Eur Heart J 2013; 34:2149–2157.
- Schlaich MP, Schmieder RE, Bakris G, et al. International expert consensus statement: percutaneous transluminal renal denervation for the treatment of resistant hypertension. J Am Coll Cardiol 2013; 62:2031–2045.
- Azizi M, Sapoval M, Gosse P, et al; Renal Denervation for Hypertension (DENERHTN) investigators. Optimum and stepped care standardised antihypertensive treatment with or without renal denervation for resistant hypertension (DENERHTN): a multicentre, open-label, randomised controlled trial. Lancet 2015; 385:1957–1965.
- Rosa J, Widimsky P, Tousek P, et al. Randomized comparison of renal denervation versus intensified pharmacotherapy including spironolactone in true-resistant hypertension: six-month results from the Prague-15 study. Hypertension 2015; 65:407–413.
- Williams B, MacDonald TM, Morant S, et al; British Hypertension Society’s PATHWAY Studies Group. Spironolactone versus placebo, bisoprolol, and doxazosin to determine the optimal treatment for drug-resistant hypertension (PATHWAY-2): a randomised, double-blind, crossover trial. Lancet 2015; 386:2059–2068.
- Sakakura K, Ladich E, Cheng Q, et al. Anatomic assessment of sympathetic peri-arterial renal nerves in man. J Am Coll Cardiol 2014; 64:635–643.
- Mahfoud F, Edelman ER, Bohm M. Catheter-based renal denervation is no simple matter: lessons to be learned from our anatomy? J Am Coll Cardiol 2014; 64:644–646.
- Id D, Kaltenbach B, Bertog SC, et al. Does the presence of accessory renal arteries affect the efficacy of renal denervation? JACC Cardiovasc Interv 2013; 6:1085–1091.
- Jin Y, Jacobs L, Baelen M, et al; Investigator-Steered Project on Intravascular Renal Denervation for Management of Drug-Resistant Hypertension (Inspired) Investigators. Rationale and design of the Investigator-Steered Project on Intravascular Renal Denervation for Management of Drug-Resistant Hypertension (INSPiRED) trial. Blood Press 2014; 23:138–146.
- ClinicalTrialsgov. Renal Denervation Using the Vessix Renal Denervation System for the Treatment of Hypertension (REDUCE HTN: REINFORCE). https://clinicaltrials.gov/ct2/show/NCT02392351?term=REDUCE-HTN%3A+REINFORCE&rank=1. Accessed August 3, 2017.
- Fischell TA, Ebner A, Gallo S, et al. Transcatheter alcohol-mediated perivascular renal denervation with the peregrine system: first-in-human experience. JACC Cardiovasc Interv 2016; 9:589–598.
- ClinicalTrialsgov. Sham controlled study of renal denervation for subjects with uncontrolled hypertension (WAVE_IV) (NCT02029885). https://clinicaltrials.gov/ct2/show/results/NCT02029885. Accessed August 3, 2017.
- Mahfoud F, Bohm M, Azizi M, et al. Proceedings from the European clinical consensus conference for renal denervation: considerations on future clinical trial design. Eur Heart J 2015; 36:2219–2227.
- Kandzari DE, Kario K, Mahfoud F, et al. The SPYRAL HTN Global Clinical Trial Program: rationale and design for studies of renal denervation in the absence (SPYRAL HTN OFF-MED) and presence (SPYRAL HTN ON-MED) of antihypertensive medications. Am Heart J 2016; 171:82–91.
- ClinicalTrialsgov. A Study of the ReCor Medical Paradise System in Clinical Hypertension (RADIANCE-HTN). https://clinicaltrials.gov/ct2/show/NCT02649426?term=RADIANCE&rank=3. Accessed August 3, 2017.
KEY POINTS
- Renal denervation consists of passing a catheter into the renal arteries and ablating their sympathetic nerves using radiofrequency energy. In theory, it should lower blood pressure and be an attractive option for treating resistant hypertension.
- SYMPLICITY HTN-3 was a blinded trial in which patients with resistant hypertension were randomized to undergo real or sham renal denervation.
- At 6 months, office systolic blood pressure had failed to fall more in the renal denervation group than in the sham denervation group by a margin of at least 5 mm Hg, the primary efficacy end point of the trial.
- Methodologic and technical shortcomings may explain the negative results of the SYMPLICITY HTN-3 trial, but most device manufacturers have put the brakes on future research into this novel therapy.
- Today, renal denervation is not available in the United States but is available for routine care in Europe and Australia.
Renal denervation: Are we on the right path?
When renal sympathetic denervation, an endovascular procedure designed to treat resistant hypertension, failed to meet its efficacy goal in the SYMPLICITY HTN-3 trial,1 the news was disappointing.
In this issue of the Cleveland Clinic Journal of Medicine, Shishehbor et al2 provide a critical review of the findings of that trial and summarize its intricacies, as well as the results of other important trials of renal denervation therapy for hypertension. To their excellent observations, we would like to add some of our own.
HYPERTENSION: COMMON, OFTEN RESISTANT
The worldwide prevalence of hypertension is increasing. In the year 2000, about 26% of the adult world population had hypertension; by the year 2025, the number is projected to rise to 29%—1.56 billion people.3
Only about 50% of patients with hypertension are treated for it and, of those, about half have it adequately controlled. In one report, about 30% of US patients with hypertension had adequate blood pressure control.4
Patients who have uncontrolled hypertension are usually older and more obese, have higher baseline blood pressure and excessive salt intake, and are more likely to have chronic kidney disease, diabetes, obstructive sleep apnea, and aldosterone excess.5 Many of these conditions are also associated with increased sympathetic nervous system activity.6
Resistance and pseudoresistance
But lack of control of blood pressure is not the same as resistant hypertension. It is important to differentiate resistant hypertension from pseudoresistant hypertension, ie, hypertension that only seems to be resistant.7 Resistant hypertension affects 12.8% of all drug-treated hypertensive patients in the United States, according to data from the National Health and Nutrition Examination Survey.8
Factors that can cause pseudoresistant hypertension include:
Suboptimal antihypertensive regimens (truly resistant hypertension means blood pressure that remains high despite concurrent treatment with 3 antihypertensive drugs of different classes, 1 of which is a diuretic, in maximal doses)
The white coat effect (higher blood pressure in the office than at home, presumably due to the stress of an office visit)
- Suboptimal blood pressure measurement techniques (eg, use of a cuff that is too small, causing falsely high readings)
- Physician inertia (eg, failure to change a regimen that is not working)
- Lifestyle factors (eg, excessive sodium intake)
- Medications that interfere with blood pressure control (eg, nonsteroidal anti-inflammatory drugs)
- Poor adherence to prescribed medications.
Causes of secondary hypertension such as obstructive sleep apnea, primary aldosteronism, and renal artery stenosis should also be ruled out before concluding that a patient has resistant hypertension.
Treatment prevents complications
Hypertension causes a myriad of medical diseases, including accelerated atherosclerosis, myocardial ischemia and infarction, both systolic and diastolic heart failure, rhythm problems (eg, atrial fibrillation), and stroke.
Most patients with resistant hypertension have no identifiable reversible causes of it, exhibit increased sympathetic nervous system activity, and have increased risk of cardiovascular events. The risk can be reduced by treatment.9,10
Adequate and sustained treatment of hypertension prevents and mitigates its complications. The classic Veterans Administration Cooperative Study in the 1960s demonstrated a 96% reduction in cardiovascular events over 18 months with the use of 3 antihypertensive medications in patients with severe hypertension.11 A reduction of as little as 2 mm Hg in the mean blood pressure has been associated with a 10% reduction in the risk of stroke mortality and a 7% decrease in ischemic heart disease mortality.12 This is an important consideration when evaluating the clinical end points of hypertension trials.
SYMPLICITY HTN-3 TRIAL: WHAT DID WE LEARN?
As controlling blood pressure is paramount in reducing cardiovascular complications, it is only natural to look for innovative strategies to supplement the medical treatments of hypertension.
The multicenter SYMPLICITY HTN-3 trial1 was undertaken to establish the efficacy of renal-artery denervation using radiofrequency energy delivered by a catheter-based system (Symplicity RDN, Medtronic, Dublin, Ireland). This randomized, sham-controlled, blinded study did not show a benefit from this procedure with respect to either of its efficacy end points—at 6 months, a reduction in office systolic blood pressure of at least 5 mm Hg more than with medical therapy alone, or a reduction in mean ambulatory systolic pressure of at least 2 mm Hg more than with medical therapy alone.
Despite the negative results, this medium-size (N = 535) randomized clinical trial still represents the highest-level evidence in the field, and we ought to learn something from it.
Limitations of SYMPLICITY HTN-3
Several factors may have contributed to the negative results of the trial.
Patient selection. For the most part, patients enrolled in renal denervation trials, including SYMPLICITY HTN-3, were not selected on the basis of heightened sympathetic nervous system activity. Assessment of sympathetic nervous system activity may identify the population most likely to achieve an adequate response.
Of note, the baseline blood pressure readings of patients in this trial were higher in the office than on ambulatory monitoring. Patients with white coat hypertension have increased sympathetic nervous system activity and thus might actually be good candidates for renal denervation therapy.
Adequacy of ablation was not measured. Many argue that an objective measure of the adequacy of the denervation procedure (qualitative or quantitative) should have been implemented and, if it had been, the results might have been different. For example, when ablation is performed in the main renal artery as well as the branches, the efficacy in reducing levels of norepinephrine is improved.13
Blood pressure fell in both groups. In SYMPLICITY HTN-3 and many other renal denervation trials, patients were assessed using both office and ambulatory blood pressure measurements. The primary end point was the office blood pressure measurement, with a 5-mm Hg difference in reduction chosen to define the superiority margin. This margin was chosen because even small reductions in blood pressure are known to decrease adverse events caused by hypertension. Notably, blood pressure fell significantly in both the control and intervention groups, with an intergroup difference of 2.39 mm Hg (not statistically significant) in favor of denervation.
Medication questions. The SYMPLICITY HTN-3 patients were supposed to be on stable medical regimens with maximal tolerated doses before the procedure. However, it was difficult to assess patients’ adherence to and tolerance of medical therapies. Many (about 40%) of the patients had their medications changed during the study.1
Therefore, a critical look at the study enrollment criteria may shed more light on the reasons for the negative findings. Did these patients truly have resistant hypertension? Before they underwent the treatment, was their prestudy pharmacologic regimen adequately intensified?
ONGOING STUDIES
After the findings of the SYMPLICITY HTN-3 study were released, several other trials—such as the Renal Denervation for Hypertension (DENERHTN)14 and Prague-15 trials15—reported conflicting results. Notably, these were not sham-controlled trials.
Newer studies with robust trial designs are ongoing. A quick search of www.clinicaltrials.gov reveals that at least 89 active clinical trials of renal denervation are registered as of the date of this writing. Excluding those with unknown status, there are 63 trials open or ongoing.
Clinical trials are also ongoing to determine the effects of renal denervation in patients with heart failure, atrial fibrillation, sleep apnea, and chronic kidney disease, all of which are known to involve heightened sympathetic nervous system activity.
NOT READY FOR CLINICAL USE
Although nonpharmacologic treatments of hypertension continue to be studied and are supported by an avalanche of trials in animals and small, mostly nonrandomized trials in humans, one should not forget that the SYMPLICITY HTN-3 trial simply did not meet its primary efficacy end points. We need definitive clinical evidence showing that renal denervation reduces either blood pressure or clinical events before it becomes a mainstream therapy in humans.
Additional trials are being conducted that were designed in accordance with the recommendations of the European Clinical Consensus Conference for Renal Denervation16 in terms of study population, design, and end points. Well-designed studies that conform to those recommendations are critical.
Finally, although our enthusiasm for renal denervation as a treatment of hypertension is tempered, there have been no noteworthy safety concerns related to the procedure, which certainly helps maintain the research momentum in this field.
- Bhatt DL, Kandzari DE, O’Neill WW, et al; SYMPLICITY HTN-3 Investigators. A controlled trial of renal denervation for resistant hypertension. N Engl J Med 2014; 370:1393–1401.
- Shishehbor MH, Hammad TA, Thomas G. Renal denervation: what happened, and why? Cleve Clin J Med 2017; 84:681–686.
- Kearney PM, Whelton M, Reynolds K, Whelton PK, He J. Global burden of hypertension: analysis of worldwide data. Lancet 2005; 365:217–223.
- Kearney PM, Whelton M, Reynolds K, Whelton PK, He J. Worldwide prevalence of hypertension: a systematic review. J Hypertens 2004; 22:11–19.
- Calhoun DA, Jones D, Textor S, et al; American Heart Association Professional Education Committee. Resistant hypertension: diagnosis, evaluation, and treatment: a scientific statement from the American Heart Association Professional Education Committee of the Council for High Blood Pressure Research. Circulation 2008; 117:e510–e526.
- Tsioufis C, Papademetriou V, Thomopoulos C, Stefanadis C. Renal denervation for sleep apnea and resistant hypertension: alternative or complementary to effective continuous positive airway pressure treatment? Hypertension 2011; 58:e191–e192.
- Calhoun DA, Jones D, Textor S, et al. Resistant hypertension: diagnosis, evaluation, and treatment. A scientific statement from the American Heart Association Professional Education Committee of the Council for High Blood Pressure Research.Hypertension 2008; 51:1403–1419.
- Persell SD. Prevalence of resistant hypertension in the United States, 2003–2008. Hypertension 2011; 57:1076–1080.
- Papademetriou V, Doumas M, Tsioufis K. Renal sympathetic denervation for the treatment of difficult-to-control or resistant hypertension. Int J Hypertens 2011; 2011:196518.
- Doumas M, Faselis C, Papademetriou V. Renal sympathetic denervation in hypertension. Curr Opin Nephrol Hypertens 2011; 20:647–653.
- Veterans Administration Cooperative Study Group on Antihypertensive Agents. Effect of treatment on morbidity in hypertension: results in patients with diastolic blood pressures averaging 115 through 129 mm Hg. JAMA 1967; 202:1028–1034.
- Lewington S, Clarke R, Qizilbash N, Peto R, Collins R; Prospective Studies Collaboration. Age-specific relevance of usual blood pressure to vascular mortality: a meta-analysis of individual data for one million adults in 61 prospective studies. Lancet 2002; 360:1903–1913.
- Henegar JR, Zhang Y, Hata C, Narciso I, Hall ME, Hall JE. Catheter-based radiofrequency renal denervation: location effects on renal norepinephrine. Am J Hypertens 2015; 28:909–914.
- Azizi M, Sapoval M, Gosse P, et al; Renal Denervation for Hypertension (DENERHTN) investigators. Optimum and stepped care standardised antihypertensive treatment with or without renal denervation for resistant hypertension (DENERHTN): a multicentre, open-label, randomised controlled trial. Lancet 2015; 385:1957–1965.
- Rosa J, Widimsky P, Waldauf P, et al. Role of adding spironolactone and renal denervation in true resistant hypertension: one-year outcomes of randomized PRAGUE-15 study. Hypertension 2016; 67:397–403.
- Mahfoud F, Bohm M, Azizi M, et al. Proceedings from the European Clinical Consensus Conference for Renal Denervation: Considerations on Future Clinical Trial Design. Eur Heart J 2015; 6:2219–2227.
When renal sympathetic denervation, an endovascular procedure designed to treat resistant hypertension, failed to meet its efficacy goal in the SYMPLICITY HTN-3 trial,1 the news was disappointing.
In this issue of the Cleveland Clinic Journal of Medicine, Shishehbor et al2 provide a critical review of the findings of that trial and summarize its intricacies, as well as the results of other important trials of renal denervation therapy for hypertension. To their excellent observations, we would like to add some of our own.
HYPERTENSION: COMMON, OFTEN RESISTANT
The worldwide prevalence of hypertension is increasing. In the year 2000, about 26% of the adult world population had hypertension; by the year 2025, the number is projected to rise to 29%—1.56 billion people.3
Only about 50% of patients with hypertension are treated for it and, of those, about half have it adequately controlled. In one report, about 30% of US patients with hypertension had adequate blood pressure control.4
Patients who have uncontrolled hypertension are usually older and more obese, have higher baseline blood pressure and excessive salt intake, and are more likely to have chronic kidney disease, diabetes, obstructive sleep apnea, and aldosterone excess.5 Many of these conditions are also associated with increased sympathetic nervous system activity.6
Resistance and pseudoresistance
But lack of control of blood pressure is not the same as resistant hypertension. It is important to differentiate resistant hypertension from pseudoresistant hypertension, ie, hypertension that only seems to be resistant.7 Resistant hypertension affects 12.8% of all drug-treated hypertensive patients in the United States, according to data from the National Health and Nutrition Examination Survey.8
Factors that can cause pseudoresistant hypertension include:
Suboptimal antihypertensive regimens (truly resistant hypertension means blood pressure that remains high despite concurrent treatment with 3 antihypertensive drugs of different classes, 1 of which is a diuretic, in maximal doses)
The white coat effect (higher blood pressure in the office than at home, presumably due to the stress of an office visit)
- Suboptimal blood pressure measurement techniques (eg, use of a cuff that is too small, causing falsely high readings)
- Physician inertia (eg, failure to change a regimen that is not working)
- Lifestyle factors (eg, excessive sodium intake)
- Medications that interfere with blood pressure control (eg, nonsteroidal anti-inflammatory drugs)
- Poor adherence to prescribed medications.
Causes of secondary hypertension such as obstructive sleep apnea, primary aldosteronism, and renal artery stenosis should also be ruled out before concluding that a patient has resistant hypertension.
Treatment prevents complications
Hypertension causes a myriad of medical diseases, including accelerated atherosclerosis, myocardial ischemia and infarction, both systolic and diastolic heart failure, rhythm problems (eg, atrial fibrillation), and stroke.
Most patients with resistant hypertension have no identifiable reversible causes of it, exhibit increased sympathetic nervous system activity, and have increased risk of cardiovascular events. The risk can be reduced by treatment.9,10
Adequate and sustained treatment of hypertension prevents and mitigates its complications. The classic Veterans Administration Cooperative Study in the 1960s demonstrated a 96% reduction in cardiovascular events over 18 months with the use of 3 antihypertensive medications in patients with severe hypertension.11 A reduction of as little as 2 mm Hg in the mean blood pressure has been associated with a 10% reduction in the risk of stroke mortality and a 7% decrease in ischemic heart disease mortality.12 This is an important consideration when evaluating the clinical end points of hypertension trials.
SYMPLICITY HTN-3 TRIAL: WHAT DID WE LEARN?
As controlling blood pressure is paramount in reducing cardiovascular complications, it is only natural to look for innovative strategies to supplement the medical treatments of hypertension.
The multicenter SYMPLICITY HTN-3 trial1 was undertaken to establish the efficacy of renal-artery denervation using radiofrequency energy delivered by a catheter-based system (Symplicity RDN, Medtronic, Dublin, Ireland). This randomized, sham-controlled, blinded study did not show a benefit from this procedure with respect to either of its efficacy end points—at 6 months, a reduction in office systolic blood pressure of at least 5 mm Hg more than with medical therapy alone, or a reduction in mean ambulatory systolic pressure of at least 2 mm Hg more than with medical therapy alone.
Despite the negative results, this medium-size (N = 535) randomized clinical trial still represents the highest-level evidence in the field, and we ought to learn something from it.
Limitations of SYMPLICITY HTN-3
Several factors may have contributed to the negative results of the trial.
Patient selection. For the most part, patients enrolled in renal denervation trials, including SYMPLICITY HTN-3, were not selected on the basis of heightened sympathetic nervous system activity. Assessment of sympathetic nervous system activity may identify the population most likely to achieve an adequate response.
Of note, the baseline blood pressure readings of patients in this trial were higher in the office than on ambulatory monitoring. Patients with white coat hypertension have increased sympathetic nervous system activity and thus might actually be good candidates for renal denervation therapy.
Adequacy of ablation was not measured. Many argue that an objective measure of the adequacy of the denervation procedure (qualitative or quantitative) should have been implemented and, if it had been, the results might have been different. For example, when ablation is performed in the main renal artery as well as the branches, the efficacy in reducing levels of norepinephrine is improved.13
Blood pressure fell in both groups. In SYMPLICITY HTN-3 and many other renal denervation trials, patients were assessed using both office and ambulatory blood pressure measurements. The primary end point was the office blood pressure measurement, with a 5-mm Hg difference in reduction chosen to define the superiority margin. This margin was chosen because even small reductions in blood pressure are known to decrease adverse events caused by hypertension. Notably, blood pressure fell significantly in both the control and intervention groups, with an intergroup difference of 2.39 mm Hg (not statistically significant) in favor of denervation.
Medication questions. The SYMPLICITY HTN-3 patients were supposed to be on stable medical regimens with maximal tolerated doses before the procedure. However, it was difficult to assess patients’ adherence to and tolerance of medical therapies. Many (about 40%) of the patients had their medications changed during the study.1
Therefore, a critical look at the study enrollment criteria may shed more light on the reasons for the negative findings. Did these patients truly have resistant hypertension? Before they underwent the treatment, was their prestudy pharmacologic regimen adequately intensified?
ONGOING STUDIES
After the findings of the SYMPLICITY HTN-3 study were released, several other trials—such as the Renal Denervation for Hypertension (DENERHTN)14 and Prague-15 trials15—reported conflicting results. Notably, these were not sham-controlled trials.
Newer studies with robust trial designs are ongoing. A quick search of www.clinicaltrials.gov reveals that at least 89 active clinical trials of renal denervation are registered as of the date of this writing. Excluding those with unknown status, there are 63 trials open or ongoing.
Clinical trials are also ongoing to determine the effects of renal denervation in patients with heart failure, atrial fibrillation, sleep apnea, and chronic kidney disease, all of which are known to involve heightened sympathetic nervous system activity.
NOT READY FOR CLINICAL USE
Although nonpharmacologic treatments of hypertension continue to be studied and are supported by an avalanche of trials in animals and small, mostly nonrandomized trials in humans, one should not forget that the SYMPLICITY HTN-3 trial simply did not meet its primary efficacy end points. We need definitive clinical evidence showing that renal denervation reduces either blood pressure or clinical events before it becomes a mainstream therapy in humans.
Additional trials are being conducted that were designed in accordance with the recommendations of the European Clinical Consensus Conference for Renal Denervation16 in terms of study population, design, and end points. Well-designed studies that conform to those recommendations are critical.
Finally, although our enthusiasm for renal denervation as a treatment of hypertension is tempered, there have been no noteworthy safety concerns related to the procedure, which certainly helps maintain the research momentum in this field.
When renal sympathetic denervation, an endovascular procedure designed to treat resistant hypertension, failed to meet its efficacy goal in the SYMPLICITY HTN-3 trial,1 the news was disappointing.
In this issue of the Cleveland Clinic Journal of Medicine, Shishehbor et al2 provide a critical review of the findings of that trial and summarize its intricacies, as well as the results of other important trials of renal denervation therapy for hypertension. To their excellent observations, we would like to add some of our own.
HYPERTENSION: COMMON, OFTEN RESISTANT
The worldwide prevalence of hypertension is increasing. In the year 2000, about 26% of the adult world population had hypertension; by the year 2025, the number is projected to rise to 29%—1.56 billion people.3
Only about 50% of patients with hypertension are treated for it and, of those, about half have it adequately controlled. In one report, about 30% of US patients with hypertension had adequate blood pressure control.4
Patients who have uncontrolled hypertension are usually older and more obese, have higher baseline blood pressure and excessive salt intake, and are more likely to have chronic kidney disease, diabetes, obstructive sleep apnea, and aldosterone excess.5 Many of these conditions are also associated with increased sympathetic nervous system activity.6
Resistance and pseudoresistance
But lack of control of blood pressure is not the same as resistant hypertension. It is important to differentiate resistant hypertension from pseudoresistant hypertension, ie, hypertension that only seems to be resistant.7 Resistant hypertension affects 12.8% of all drug-treated hypertensive patients in the United States, according to data from the National Health and Nutrition Examination Survey.8
Factors that can cause pseudoresistant hypertension include:
Suboptimal antihypertensive regimens (truly resistant hypertension means blood pressure that remains high despite concurrent treatment with 3 antihypertensive drugs of different classes, 1 of which is a diuretic, in maximal doses)
The white coat effect (higher blood pressure in the office than at home, presumably due to the stress of an office visit)
- Suboptimal blood pressure measurement techniques (eg, use of a cuff that is too small, causing falsely high readings)
- Physician inertia (eg, failure to change a regimen that is not working)
- Lifestyle factors (eg, excessive sodium intake)
- Medications that interfere with blood pressure control (eg, nonsteroidal anti-inflammatory drugs)
- Poor adherence to prescribed medications.
Causes of secondary hypertension such as obstructive sleep apnea, primary aldosteronism, and renal artery stenosis should also be ruled out before concluding that a patient has resistant hypertension.
Treatment prevents complications
Hypertension causes a myriad of medical diseases, including accelerated atherosclerosis, myocardial ischemia and infarction, both systolic and diastolic heart failure, rhythm problems (eg, atrial fibrillation), and stroke.
Most patients with resistant hypertension have no identifiable reversible causes of it, exhibit increased sympathetic nervous system activity, and have increased risk of cardiovascular events. The risk can be reduced by treatment.9,10
Adequate and sustained treatment of hypertension prevents and mitigates its complications. The classic Veterans Administration Cooperative Study in the 1960s demonstrated a 96% reduction in cardiovascular events over 18 months with the use of 3 antihypertensive medications in patients with severe hypertension.11 A reduction of as little as 2 mm Hg in the mean blood pressure has been associated with a 10% reduction in the risk of stroke mortality and a 7% decrease in ischemic heart disease mortality.12 This is an important consideration when evaluating the clinical end points of hypertension trials.
SYMPLICITY HTN-3 TRIAL: WHAT DID WE LEARN?
As controlling blood pressure is paramount in reducing cardiovascular complications, it is only natural to look for innovative strategies to supplement the medical treatments of hypertension.
The multicenter SYMPLICITY HTN-3 trial1 was undertaken to establish the efficacy of renal-artery denervation using radiofrequency energy delivered by a catheter-based system (Symplicity RDN, Medtronic, Dublin, Ireland). This randomized, sham-controlled, blinded study did not show a benefit from this procedure with respect to either of its efficacy end points—at 6 months, a reduction in office systolic blood pressure of at least 5 mm Hg more than with medical therapy alone, or a reduction in mean ambulatory systolic pressure of at least 2 mm Hg more than with medical therapy alone.
Despite the negative results, this medium-size (N = 535) randomized clinical trial still represents the highest-level evidence in the field, and we ought to learn something from it.
Limitations of SYMPLICITY HTN-3
Several factors may have contributed to the negative results of the trial.
Patient selection. For the most part, patients enrolled in renal denervation trials, including SYMPLICITY HTN-3, were not selected on the basis of heightened sympathetic nervous system activity. Assessment of sympathetic nervous system activity may identify the population most likely to achieve an adequate response.
Of note, the baseline blood pressure readings of patients in this trial were higher in the office than on ambulatory monitoring. Patients with white coat hypertension have increased sympathetic nervous system activity and thus might actually be good candidates for renal denervation therapy.
Adequacy of ablation was not measured. Many argue that an objective measure of the adequacy of the denervation procedure (qualitative or quantitative) should have been implemented and, if it had been, the results might have been different. For example, when ablation is performed in the main renal artery as well as the branches, the efficacy in reducing levels of norepinephrine is improved.13
Blood pressure fell in both groups. In SYMPLICITY HTN-3 and many other renal denervation trials, patients were assessed using both office and ambulatory blood pressure measurements. The primary end point was the office blood pressure measurement, with a 5-mm Hg difference in reduction chosen to define the superiority margin. This margin was chosen because even small reductions in blood pressure are known to decrease adverse events caused by hypertension. Notably, blood pressure fell significantly in both the control and intervention groups, with an intergroup difference of 2.39 mm Hg (not statistically significant) in favor of denervation.
Medication questions. The SYMPLICITY HTN-3 patients were supposed to be on stable medical regimens with maximal tolerated doses before the procedure. However, it was difficult to assess patients’ adherence to and tolerance of medical therapies. Many (about 40%) of the patients had their medications changed during the study.1
Therefore, a critical look at the study enrollment criteria may shed more light on the reasons for the negative findings. Did these patients truly have resistant hypertension? Before they underwent the treatment, was their prestudy pharmacologic regimen adequately intensified?
ONGOING STUDIES
After the findings of the SYMPLICITY HTN-3 study were released, several other trials—such as the Renal Denervation for Hypertension (DENERHTN)14 and Prague-15 trials15—reported conflicting results. Notably, these were not sham-controlled trials.
Newer studies with robust trial designs are ongoing. A quick search of www.clinicaltrials.gov reveals that at least 89 active clinical trials of renal denervation are registered as of the date of this writing. Excluding those with unknown status, there are 63 trials open or ongoing.
Clinical trials are also ongoing to determine the effects of renal denervation in patients with heart failure, atrial fibrillation, sleep apnea, and chronic kidney disease, all of which are known to involve heightened sympathetic nervous system activity.
NOT READY FOR CLINICAL USE
Although nonpharmacologic treatments of hypertension continue to be studied and are supported by an avalanche of trials in animals and small, mostly nonrandomized trials in humans, one should not forget that the SYMPLICITY HTN-3 trial simply did not meet its primary efficacy end points. We need definitive clinical evidence showing that renal denervation reduces either blood pressure or clinical events before it becomes a mainstream therapy in humans.
Additional trials are being conducted that were designed in accordance with the recommendations of the European Clinical Consensus Conference for Renal Denervation16 in terms of study population, design, and end points. Well-designed studies that conform to those recommendations are critical.
Finally, although our enthusiasm for renal denervation as a treatment of hypertension is tempered, there have been no noteworthy safety concerns related to the procedure, which certainly helps maintain the research momentum in this field.
- Bhatt DL, Kandzari DE, O’Neill WW, et al; SYMPLICITY HTN-3 Investigators. A controlled trial of renal denervation for resistant hypertension. N Engl J Med 2014; 370:1393–1401.
- Shishehbor MH, Hammad TA, Thomas G. Renal denervation: what happened, and why? Cleve Clin J Med 2017; 84:681–686.
- Kearney PM, Whelton M, Reynolds K, Whelton PK, He J. Global burden of hypertension: analysis of worldwide data. Lancet 2005; 365:217–223.
- Kearney PM, Whelton M, Reynolds K, Whelton PK, He J. Worldwide prevalence of hypertension: a systematic review. J Hypertens 2004; 22:11–19.
- Calhoun DA, Jones D, Textor S, et al; American Heart Association Professional Education Committee. Resistant hypertension: diagnosis, evaluation, and treatment: a scientific statement from the American Heart Association Professional Education Committee of the Council for High Blood Pressure Research. Circulation 2008; 117:e510–e526.
- Tsioufis C, Papademetriou V, Thomopoulos C, Stefanadis C. Renal denervation for sleep apnea and resistant hypertension: alternative or complementary to effective continuous positive airway pressure treatment? Hypertension 2011; 58:e191–e192.
- Calhoun DA, Jones D, Textor S, et al. Resistant hypertension: diagnosis, evaluation, and treatment. A scientific statement from the American Heart Association Professional Education Committee of the Council for High Blood Pressure Research.Hypertension 2008; 51:1403–1419.
- Persell SD. Prevalence of resistant hypertension in the United States, 2003–2008. Hypertension 2011; 57:1076–1080.
- Papademetriou V, Doumas M, Tsioufis K. Renal sympathetic denervation for the treatment of difficult-to-control or resistant hypertension. Int J Hypertens 2011; 2011:196518.
- Doumas M, Faselis C, Papademetriou V. Renal sympathetic denervation in hypertension. Curr Opin Nephrol Hypertens 2011; 20:647–653.
- Veterans Administration Cooperative Study Group on Antihypertensive Agents. Effect of treatment on morbidity in hypertension: results in patients with diastolic blood pressures averaging 115 through 129 mm Hg. JAMA 1967; 202:1028–1034.
- Lewington S, Clarke R, Qizilbash N, Peto R, Collins R; Prospective Studies Collaboration. Age-specific relevance of usual blood pressure to vascular mortality: a meta-analysis of individual data for one million adults in 61 prospective studies. Lancet 2002; 360:1903–1913.
- Henegar JR, Zhang Y, Hata C, Narciso I, Hall ME, Hall JE. Catheter-based radiofrequency renal denervation: location effects on renal norepinephrine. Am J Hypertens 2015; 28:909–914.
- Azizi M, Sapoval M, Gosse P, et al; Renal Denervation for Hypertension (DENERHTN) investigators. Optimum and stepped care standardised antihypertensive treatment with or without renal denervation for resistant hypertension (DENERHTN): a multicentre, open-label, randomised controlled trial. Lancet 2015; 385:1957–1965.
- Rosa J, Widimsky P, Waldauf P, et al. Role of adding spironolactone and renal denervation in true resistant hypertension: one-year outcomes of randomized PRAGUE-15 study. Hypertension 2016; 67:397–403.
- Mahfoud F, Bohm M, Azizi M, et al. Proceedings from the European Clinical Consensus Conference for Renal Denervation: Considerations on Future Clinical Trial Design. Eur Heart J 2015; 6:2219–2227.
- Bhatt DL, Kandzari DE, O’Neill WW, et al; SYMPLICITY HTN-3 Investigators. A controlled trial of renal denervation for resistant hypertension. N Engl J Med 2014; 370:1393–1401.
- Shishehbor MH, Hammad TA, Thomas G. Renal denervation: what happened, and why? Cleve Clin J Med 2017; 84:681–686.
- Kearney PM, Whelton M, Reynolds K, Whelton PK, He J. Global burden of hypertension: analysis of worldwide data. Lancet 2005; 365:217–223.
- Kearney PM, Whelton M, Reynolds K, Whelton PK, He J. Worldwide prevalence of hypertension: a systematic review. J Hypertens 2004; 22:11–19.
- Calhoun DA, Jones D, Textor S, et al; American Heart Association Professional Education Committee. Resistant hypertension: diagnosis, evaluation, and treatment: a scientific statement from the American Heart Association Professional Education Committee of the Council for High Blood Pressure Research. Circulation 2008; 117:e510–e526.
- Tsioufis C, Papademetriou V, Thomopoulos C, Stefanadis C. Renal denervation for sleep apnea and resistant hypertension: alternative or complementary to effective continuous positive airway pressure treatment? Hypertension 2011; 58:e191–e192.
- Calhoun DA, Jones D, Textor S, et al. Resistant hypertension: diagnosis, evaluation, and treatment. A scientific statement from the American Heart Association Professional Education Committee of the Council for High Blood Pressure Research.Hypertension 2008; 51:1403–1419.
- Persell SD. Prevalence of resistant hypertension in the United States, 2003–2008. Hypertension 2011; 57:1076–1080.
- Papademetriou V, Doumas M, Tsioufis K. Renal sympathetic denervation for the treatment of difficult-to-control or resistant hypertension. Int J Hypertens 2011; 2011:196518.
- Doumas M, Faselis C, Papademetriou V. Renal sympathetic denervation in hypertension. Curr Opin Nephrol Hypertens 2011; 20:647–653.
- Veterans Administration Cooperative Study Group on Antihypertensive Agents. Effect of treatment on morbidity in hypertension: results in patients with diastolic blood pressures averaging 115 through 129 mm Hg. JAMA 1967; 202:1028–1034.
- Lewington S, Clarke R, Qizilbash N, Peto R, Collins R; Prospective Studies Collaboration. Age-specific relevance of usual blood pressure to vascular mortality: a meta-analysis of individual data for one million adults in 61 prospective studies. Lancet 2002; 360:1903–1913.
- Henegar JR, Zhang Y, Hata C, Narciso I, Hall ME, Hall JE. Catheter-based radiofrequency renal denervation: location effects on renal norepinephrine. Am J Hypertens 2015; 28:909–914.
- Azizi M, Sapoval M, Gosse P, et al; Renal Denervation for Hypertension (DENERHTN) investigators. Optimum and stepped care standardised antihypertensive treatment with or without renal denervation for resistant hypertension (DENERHTN): a multicentre, open-label, randomised controlled trial. Lancet 2015; 385:1957–1965.
- Rosa J, Widimsky P, Waldauf P, et al. Role of adding spironolactone and renal denervation in true resistant hypertension: one-year outcomes of randomized PRAGUE-15 study. Hypertension 2016; 67:397–403.
- Mahfoud F, Bohm M, Azizi M, et al. Proceedings from the European Clinical Consensus Conference for Renal Denervation: Considerations on Future Clinical Trial Design. Eur Heart J 2015; 6:2219–2227.
Biostatistics and epidemiology lecture series, part 1

Supplement Editor:
Aanchal Kapoor, MD
Contents
Introduction: Biostatistics and epidemiology lecture series, part 1
Aanchal Kapoor, MD
The architecture of clinical research
James K. Stoller
Basics of study design: Practical considerations
Robert L. Chatburn
Chi-square and Fisher's exact tests
Amy Nowacki
Supplement Editor:
Aanchal Kapoor, MD
Contents
Introduction: Biostatistics and epidemiology lecture series, part 1
Aanchal Kapoor, MD
The architecture of clinical research
James K. Stoller
Basics of study design: Practical considerations
Robert L. Chatburn
Chi-square and Fisher's exact tests
Amy Nowacki
Supplement Editor:
Aanchal Kapoor, MD
Contents
Introduction: Biostatistics and epidemiology lecture series, part 1
Aanchal Kapoor, MD
The architecture of clinical research
James K. Stoller
Basics of study design: Practical considerations
Robert L. Chatburn
Chi-square and Fisher's exact tests
Amy Nowacki

Introduction: Biostatistics and epidemiology lecture series, part 1
Physicians are inundated with clinical research findings that potentially impact patient care. Evaluating the strength and clinical application of research results requires an understanding of the underlying biostatistics and epidemiological principles.
The articles in this supplement are based on a series of lectures originally developed for fellows in pulmonary and critical care medicine to provide them with the tools to transform a scientific or clinical question into research projects, and then pursue the answer to their question with the appropriate methods. The same skills also enable them to appraise the published literature in a systematic and rigorous manner.
Each topic in the series began with a presentation and discussion of statistical principles and methods, then moved to a practical module using the principles to appraise a specific publication. Participants in the course had an immediate opportunity to try the techniques, both to demonstrate understanding and to reinforce the concepts to each learner. The articles of this series follow the same outline, providing clinicians of all specialties the basic statistical tools to conduct and appraise clinical research, along with a sample article for practicing each statistical method presented.
This Cleveland Clinic Journal of Medicine supplement includes 3 lectures from the “Biostatistics and Epidemiology Lecture Series.” Dr. Stoller’s presentation, The Architecture of Clinical Research, describes the basic structure of clinical research and the nomenclature to understand trial design and sources of bias.
Building on those concepts, Dr. Chatburn’s lecture, Basics of Study Design: Practical Considerations, outlines the structured approach to develop a formal research protocol. How to identify a problem, expand the scope of it through a literature review, create a hypothesis, design a study, and an introduction to basic statistical methods are discussed.
And in Chi-square and Fisher’s Exact Tests, Dr. Nowacki introduces the statistical methodology of these 2 tests to assess associations between 2 independent categorical variables. The sample article illustrates step-by-step calculation of both the large sample approximation (chi-square) and exact (Fisher’s) methodologies providing insight into how these tests are conducted.
My hope is that these articles, and future installments based on forthcoming lectures, are helpful to physicians both in conducting their own research and in evaluating the research of others
Physicians are inundated with clinical research findings that potentially impact patient care. Evaluating the strength and clinical application of research results requires an understanding of the underlying biostatistics and epidemiological principles.
The articles in this supplement are based on a series of lectures originally developed for fellows in pulmonary and critical care medicine to provide them with the tools to transform a scientific or clinical question into research projects, and then pursue the answer to their question with the appropriate methods. The same skills also enable them to appraise the published literature in a systematic and rigorous manner.
Each topic in the series began with a presentation and discussion of statistical principles and methods, then moved to a practical module using the principles to appraise a specific publication. Participants in the course had an immediate opportunity to try the techniques, both to demonstrate understanding and to reinforce the concepts to each learner. The articles of this series follow the same outline, providing clinicians of all specialties the basic statistical tools to conduct and appraise clinical research, along with a sample article for practicing each statistical method presented.
This Cleveland Clinic Journal of Medicine supplement includes 3 lectures from the “Biostatistics and Epidemiology Lecture Series.” Dr. Stoller’s presentation, The Architecture of Clinical Research, describes the basic structure of clinical research and the nomenclature to understand trial design and sources of bias.
Building on those concepts, Dr. Chatburn’s lecture, Basics of Study Design: Practical Considerations, outlines the structured approach to develop a formal research protocol. How to identify a problem, expand the scope of it through a literature review, create a hypothesis, design a study, and an introduction to basic statistical methods are discussed.
And in Chi-square and Fisher’s Exact Tests, Dr. Nowacki introduces the statistical methodology of these 2 tests to assess associations between 2 independent categorical variables. The sample article illustrates step-by-step calculation of both the large sample approximation (chi-square) and exact (Fisher’s) methodologies providing insight into how these tests are conducted.
My hope is that these articles, and future installments based on forthcoming lectures, are helpful to physicians both in conducting their own research and in evaluating the research of others
Physicians are inundated with clinical research findings that potentially impact patient care. Evaluating the strength and clinical application of research results requires an understanding of the underlying biostatistics and epidemiological principles.
The articles in this supplement are based on a series of lectures originally developed for fellows in pulmonary and critical care medicine to provide them with the tools to transform a scientific or clinical question into research projects, and then pursue the answer to their question with the appropriate methods. The same skills also enable them to appraise the published literature in a systematic and rigorous manner.
Each topic in the series began with a presentation and discussion of statistical principles and methods, then moved to a practical module using the principles to appraise a specific publication. Participants in the course had an immediate opportunity to try the techniques, both to demonstrate understanding and to reinforce the concepts to each learner. The articles of this series follow the same outline, providing clinicians of all specialties the basic statistical tools to conduct and appraise clinical research, along with a sample article for practicing each statistical method presented.
This Cleveland Clinic Journal of Medicine supplement includes 3 lectures from the “Biostatistics and Epidemiology Lecture Series.” Dr. Stoller’s presentation, The Architecture of Clinical Research, describes the basic structure of clinical research and the nomenclature to understand trial design and sources of bias.
Building on those concepts, Dr. Chatburn’s lecture, Basics of Study Design: Practical Considerations, outlines the structured approach to develop a formal research protocol. How to identify a problem, expand the scope of it through a literature review, create a hypothesis, design a study, and an introduction to basic statistical methods are discussed.
And in Chi-square and Fisher’s Exact Tests, Dr. Nowacki introduces the statistical methodology of these 2 tests to assess associations between 2 independent categorical variables. The sample article illustrates step-by-step calculation of both the large sample approximation (chi-square) and exact (Fisher’s) methodologies providing insight into how these tests are conducted.
My hope is that these articles, and future installments based on forthcoming lectures, are helpful to physicians both in conducting their own research and in evaluating the research of others
The architecture of clinical research
I am flattered to present the inaugural talk in the biostatistics and clinical research design series on the architecture of clinical research. This content is based on the teachings of my mentor, Dr. Alvan Feinstein, who together with Dr. David Sackett, is credited with pioneering clinical epidemiology. Dr. Feinstein was a Sterling Professor at the Yale School of Medicine. His main opus of work is a book called, Clinical Epidemiology: The Architecture of Clinical Research.1 This paper is named in credit to Dr. Feinstein’s enormous contribution. I will review some important terms defined by Dr. Feinstein to provide the background necessary for the remainder of the talks in this series.
To start, I will frame this topic by asking the following question: Why do we do research? I’ll talk about the basic structure of research studies and provide a taxonomy, as Dr. Feinstein would say, a nomenclature with which to understand trial design and the sources of bias in those trials. Then, I will discuss these sources of bias in detail using the taxonomy that Dr. Feinstein described in his aforementioned book. Finally, I will share with you some examples of bias in clinical trials to help you better understand these concepts.
Now, the answer to the basic question posed above is: basically, we do cause-and-effect research to establish the causality of a risk factor or the efficacy of a therapy. Does cigarette smoking cause lung cancer? Does taking hydrochlorothiazide help systemic hypertension? Does air pollution worsen asthma? Does supplemental oxygen help patients with chronic obstructive pulmonary disease (COPD)?
Cause-and-effect research can be subsumed under 2 broad issues: causal risk factors and therapeutic efficacy. In his review of early false understandings in medicine that were based on anecdotal observation alone, Thomas cites many examples—“the undue longevity of useless and even harmful drugs can be laid at the door of authority,” ie, empiricism, lack of rigorous research.2 The field is full of these: yellow fever causality, the value of cupping, and even intermittent mandatory ventilation when it was described by John Downs in 1973 and touted as a superior mode for weaning patients from mechanical ventilation.3 Twenty-five years later, randomized controlled trials by Brochard et al4 indicated not only that intermittent mandatory ventilation was not the best mode to wean but was, in fact, the worst mode for weaning patients from mechanical ventilation compared with either pressure support or spontaneous breathing trials. Many more examples exist to demonstrate the false understandings that can be ascribed to lack of rigorous study or evidence in medicine.

Before systematically exploring the sources of bias in Feinstein’s construct, let us define some very basic terms from his book. Dr. Feinstein talks about the baseline state, which refers to the group of patients under study who are culled from a larger population to whom the results are intended to be applied (Figure 1).1 This baseline group is hopefully representative of this larger target population. As a nod to the later discussion, Dr. Feinstein would call bias introduced by unusual assembly of the study population from the larger intended population as “assembly bias.” So, if the group under study is not representative of either the patients you see or the world of patients with this condition or if there is something special or distinctively nonrepresentative about the study population, then the results may be subject to “assembly bias.” Assembly bias can compromise the so-called “external” validity of the study—its ability to be applied to populations beyond the study group.
Having assembled a baseline group for study, that group is classically allocated to 1 of 2 (or sometimes more than 2) compared therapies. In a controlled trial, patients can be allocated using a variety of strategies, including randomization. Using the paradigm diagram (Figure 1, which considers a 2-arm trial), patients are allocated to 1 of 2 compared groups—group A and group B. Then, in a treatment trial, 1 group receives the principal maneuver, which is the drug or intervention under study—for example, supplemental oxygen for patients with COPD. The comparative maneuver is allocated to group B, which also receives all the other treatments (called “co-maneuvers”) that are used to treat the condition under study. In a trial of supplemental oxygen for COPD evaluating lung function and exacerbation frequency as outcome measures, such co-maneuvers might include inhaled bronchodilators, inhaled corticosteroids, pulmonary rehabilitation, and Pneumovax vaccine. Ideally, these co-maneuvers are equally distributed between the compared groups (A and B).
So, in summary, we have a comparative maneuver, which is the nonadministration of supplemental oxygen in this proposed trial of supplemental oxygen in COPD, the principal maneuver—administration of oxygen—and all the co-maneuvers that are ideally equally distributed between both groups. This balanced distribution of co-maneuvers between the compared groups helps to ensure that any differences in the study outcome measures (ie, what is counted as the main impact of the intervention under study) can be solely attributed to the principal maneuver. When this condition—that the difference in outcomes can be reliably ascribed to the study intervention—is satisfied, the study is felt to be “internally” valid. As we will see, ensuring internal validity requires freedom from the many sources of what Dr. Feinstein calls “internal bias.”
Back to basic terms: “cohort” in Dr. Feinstein’s language is a group that shares common traits and is followed forward in a longitudinal study. The “outcome measure” is self-evident—it is what is being measured, with the “primary outcome” being the pre-defined measure that is considered the most important (and ideally most clinically relevant) impact of the study intervention. Later in this series of lectures, there will be discussions of power calculations and the so-called “effect size”—the magnitude of effect that the intervention is expected to produce and that is ideally deemed clinically important.
An important consideration in designing a trial is to define and declare the primary outcome measure carefully because defining the primary outcome measure has important implications for the study. I will provide an example from the alpha-1 antitrypsin deficiency literature. Some of you have probably read what has been called the RAPID trial.5 RAPID was a trial of augmentation therapy vs placebo in patients with severe alpha-1 antitrypsin deficiency. The primary outcome measure (which was pre-negotiated with the US Food and Drug Administration [FDA]) was computer tomography (CT) lung density determined at functional residual capacity (FRC) and total lung capacity (TLC). The trial failed to achieve statistical significance in regard to CT lung density, although the study authors argued that CT density measurements made at TLC were more reproducible than those made at FRC. When the results were analyzed by TLC alone, the results were statistically significant, but when they were analyzed with FRC and TLC combined, they were not. In the end, based on the pre-negotiated primary outcome measure of CT density based on both FRC and TLC, the FDA rejected the proposal for a label change to say that augmentation therapy slowed the loss of lung density even though the weight of evidence was clearly in its favor. This case exemplifies just how critical the choice of primary outcome measure can be.

The wash-out period refers to an interval in a subset of randomized trials called “crossover trials” in which the primary intervention is discontinued and the patient returns to his baseline state before the comparative maneuver is then implemented (Figure 2).6 In order to perform a crossover trial, it is important that the effects of the initial intervention can “wash out” or be fully extinguished. So, for example, in trials of radiation therapy vs surgery, it is impossible to do a crossover trial because the effects of radiation can never completely wash out nor can those of surgery, which are similarly permanent. For example, we cannot replace the colon once it is resected for cancer or replace the appendix once removed. Therefore, producing a wash-out requires some very specific pharmacokinetic and pharmacodynamic features in order for a crossover trial to be considered. Later talks in this series will discuss the enhanced statistical power of a crossover trial, where one is comparing every patient to him or herself rather than to another patient.
So, there is always an appetite to do a crossover trial as long as the criteria for wash-out can be met, namely again that the primary intervention can dissipate completely to the baseline state before the alternative intervention is implemented.
“Placebo” is a fairly self-evident and well-understood term; placebo refers to the administration of a maneuver in a way that is identical to the principal maneuver except that the placebo is not expected to exert any clinical effect.
“Blinding” is the unawareness of either the investigator or of the patient to which the intervention is being administered. “Single-blinding” refers to the condition in which either the study or the investigator (but not both) is unaware, and “double-blinding” refers to the condition in which both the subjects and the investigators are unaware. There can be some subtle issues that compromise whether the patient is aware of the intervention that he or she is receiving and that can potentially condition the patient’s response, particularly if there is any subjective component of the assessment of the outcome. So, blinding is important.
With these terms describing the elements of a clinical study now described, let us turn to the types of studies that comprise clinical research. The first group of study types is what Dr. Feinstein called descriptive studies—studies that simply describe phenomena without comparison to a control group. As an example of a descriptive study, Sehgal et al7 recently described the workup of a focal, segmental pneumonia in a patient taking pembrolizumab for lung cancer. In this paper, there were four other cases of focal pneumonia accompanying pembrolizumab use that were assembled from the literature, making this descriptive paper a so-called case series. A “case series” differs from a “single case report,” which reports a single patient experience. Though limited in their ability to establish cause and effect, case reports and case series can help researchers develop proof of principle, so I would not discount the value of case reports.8
I can cite a case report from of my own experience that demonstrates this point. In 1987, I saw a patient from Buffalo who had primary biliary cirrhosis and the hepatopulmonary syndrome (HPS). She was so debilitated by her HPS that she could not stand up without desaturating severely. Although she had normal liver synthetic function, she was severely debilitated by her HPS and the decision was made to offer her a liver transplant, which, at that time, was considered to be relatively contraindicated. Much to everyone’s amazement and satisfaction, her HPS completely resolved after the transplant surgery. Her oxygenation and alveolar-arterial oxygen gradient normalized, and her clubbing resolved. We reported this in a case report, which began to affect the way people thought about the feasibility of liver transplant for the HPS.8 The lesson is: do not underestimate the power of a thoughtful case report.
The second group of research study types is called “cohort studies,” in which one actually compares outcomes between 2 groups in the study. Cohort studies fall into the bucket of either “observational cohort studies,” in which allocation to the compared maneuvers is not performed by randomization but by any other strategy, and “randomized trials.” In observational studies, allocation could occur through physician choice, as when the physician prescribes a treatment to 1 group but not another, or by patient choice or circumstance. For example, an observational cohort study of the risk of cigarette smoking would compare outcomes between smokers and non-smokers where the patient choses to smoke under his/her own volition. Alternatively, the circumstances of an exposure could allocate someone to the principal maneuver, as when we are studying the effect of exposure to World Trade Center dust in the firefighters who responded or of exposure to nuclear radiation in Hiroshima survivors. These are examples of observational cohort studies that compare exposed individuals to unexposed individuals, where the exposure did not occur by randomization but by choice or unfortunate circumstance.
In contrast to observational studies, allocation in randomized trials occurs through a formal process. Randomization has the specific purpose of attempting to ensure that patients are allocated to 2 comparative groups from the baseline group with comparable risk for developing the outcome measure. When randomization is effective, differences in study outcomes can be reliably ascribed to the intervention rather than to differences in the baseline susceptibility of the compared groups.
While randomization is an excellent strategy to ensure baseline similarity between compared groups, randomization can fail, and its effectiveness must be checked. Specifically, in a randomized trial, it is customary to examine the compared groups at baseline on all features that can affect the likelihood of developing the outcome measure. If the groups turn out to be dissimilar at baseline in an important way, then the study is at risk for bias, which is specifically called “susceptibility bias” in Feinstein’s construct. Obviously, the larger number of baseline clinical and demographic features that can condition the likelihood of developing the outcome measure, the more difficult it is to achieve baseline similarity between compared groups and the more important it becomes to ensure that randomization has been effective. In this circumstance, larger numbers of participants in both compared groups are generally needed. More about susceptibility bias later.
There are generally 2 types of randomized trials: the so-called “parallel controlled trials” in which each group receives either the principal or the comparative maneuver and is followed and “crossover trials” in which each compared group receives both the principal maneuver and the co-maneuver at different times after an effective wash-out period. Wash-out was discussed above. Figure 2 shows an example of a crossover trial examining the effects of terbutaline on diaphragmatic function.6 The investigators administered terbutaline for a week, measured transdiaphragmatic pressures, gave the patient a terbutaline vacation (the “wash-out period”), and then crossed over those patients who were initially receiving terbutaline to placebo and initial placebo recipients to terbutaline, having remeasured diaphragmatic function after the wash-out period to assure that the patient’s diaphragmatic function prior to the second crossover was identical to his/her baseline state. If this return to baseline is accomplished, then the criteria from effective wash-out are satisfied.


As we begin to talk about sources of bias, consider a study in which we compare survival of patients allocated to surgery vs nonsurgical therapy for lung cancer (Figure 3).1 This study is subject to the first type of so-called “internal bias” in the Feinsteinian construct—so-called “selection bias.” For example, all patients treated surgically were considered healthy enough by their doctors to undergo surgery, whereas patients treated without surgery may have been deemed inoperable because of comorbidities, lung dysfunction, cardiac dysfunction, and so on. If the results of such a comparison show that the mortality rate among surgical patients in this study was lower, the question then becomes: is the improved survival in surgical candidates due to the superior efficacy of surgery vs other therapy or was the enhanced survival due to the surgical patients being healthier to begin with? You can intuitively sense that the answer to this question is that the enhanced survival may be due to the better health of patients treated surgically rather than to the surgery itself because of how the patients were selected to receive it. So, this is a simple example of what Dr. Feinstein would call “susceptibility bias.” Susceptibility bias occurs when the 2 baseline groups are not comparably at risk or susceptible to developing the outcome measure, leading the naïve investigator in this specific example to attribute the difference in outcomes to the superiority of surgery when in fact it may have nothing to do with the surgery vs. the other maneuver. When susceptibility bias is in play, the difference between the outcomes in the compared groups could be attributed to the baseline imbalance of the groups rather than to the principal maneuver itself.
Turning back to the taxonomy of bias, there are four types that can threaten internal validity—“susceptibility,” “performance,” “detection,” and “transfer” bias—and 1 type of bias (called “external bias”) that can affect the generalizability of the study called “assembly bias” (Table 1).

Figure 4 shows where these various sources of bias appear in the architecture of a clinical trial. As just discussed, susceptibility bias affects the baseline state and the comparability of the groups. Performance bias relates to how effective and how comparably the co-maneuvers are given and whether the primary intervention is potent enough to affect an outcome. Both transfer and detection bias operate in detecting the outcome, especially regarding the rigor and frequency with which they are investigated. Transfer bias has to do with selective loss to follow-up of those included in the trial. If there is a systematic reason for loss to follow-up that is related to the impact of the intervention, then the study is at risk for transfer bias. For example, in a randomized trial of drug A vs placebo for pneumonia, if drug A is effective but all the drug A recipients fail to follow-up because they feel too good to return for follow-up, then transfer bias could be causing the study to show nonefficacy even though the drug works. So, if those who respond favorably are systematically lost to follow-up, and if all the patients who felt lousy wanted to see the doctor and came back for follow-up, such transfer bias would bias towards nonefficacy. Specifically, only patients remaining in the trial would be those who failed to respond and that would dilute any difference between the 2 groups despite the active efficacy of drug A.
Hopefully, you are already beginning to get a sense that one has to be extremely disciplined in thinking about each of these sources of bias because they can have some very subtle nuances in randomized trials that can easily escape attention.
Returning to sources of bias, let’s consider the second type of bias, “performance bias.” Performance bias relates to the administration of the compared maneuvers—the primary or principal maneuver, compared with the comparative maneuver. Performance bias can occur when the main maneuver is not administered adequately or when the co-maneuvers are administered in an imbalanced way between the compared groups. Consider the example of the Long-Term Oxygen Treatment Trial (LOTT) trial, which compared use of supplemental oxygen with no supplemental oxygen in patients with stable COPD and resting or exercise-induced moderate desaturation.9 The principal outcome measure of LOTT was all-cause hospitalization or death. In such a study, many potential sources of performance bias exist. For example, performance bias might exist if none of the patients allocated to oxygen actually used supplemental oxygen. Alternately, to the extent that use of inhaled corticosteroids or antimuscarinic agents lessens the risk of COPD exacerbation, performance bias could occur if use of these co-maneuvers was imbalanced between the compared groups. As a specific extreme circumstance, if all patients in the nonoxygen group used these inhalers but none of the patients in the oxygen group did, then a lack of difference between exacerbation frequency could be related to this imbalance in co-maneuvers (a form of performance bias) rather than to the lack of efficacy of supplemental oxygen.
“Compliance bias” is a subset of performance bias which occurs when 2 conditions are satisfied: (1) the main maneuver is not administered adequately, and (2) the investigator is unaware of that nonreceipt so that this cannot be accounted for in interpreting the study results. For example, if a drug has efficacy but if no one in the treatment arm of the trial takes the drug, the absence of a difference in outcomes between the compared groups will be ascribed to nonefficacy, whereas “compliance bias” (ie, no one actually took the drug) could actually be the cause. Ideally, randomized studies should be evaluated on an “intention to treat” basis irrespective of compliance, but there is an analytic approach called “per protocol” analysis in which you can analyze the results according to whether the patient actually used the intervention in an effective way. “Per protocol” analysis is a secondary analysis of the primary results but it can nonetheless help determine whether the negative result is likely related to noncompliance or not.
A third type of internal bias, “detection bias,” is fairly straightforward. Detection bias is related to how avidly and how comparably the outcomes are measured between the 2 compared groups. Let’s say that you are conducting a trial of a new antibiotic and the primary outcome is colony counts on petri dishes of plated collected specimens. If the technicians who read the petri dish counts are unblinded, they may look at the colony counts with a biased eye, seeing fewer colonies on plates collected from patients receiving the antibiotic.
Overall, detection bias occurs when outcomes are ascertained or detected unequally between the compared groups, and detection bias can involve any of the following: is there comparable surveillance of the 2 groups for analysis of the outcome measure? Are the diagnostic tests comparably performed in both groups and is the interpretation comparably unbiased with equipoise? Investigators who know which patients are receiving an active drug and those who are not could experience subliminal bias that renders them more likely to find that the drug under study is efficacious.
Depending on the principal study maneuver, ensuring blinding can be challenging. To demonstrate this point, let’s consider the example of conducting a randomized control trial of Vicks VapoRub. Vicks VapoRub is an old product that smells like wintergreen and that mothers used to rub on the chests of their infants in the hope of speeding recovery from colds and bronchitis episodes. It was felt that the distinctive smell of the product was materially related to wintergreen, which gives rise to the odor. So, imagine a randomized trial of Vicks VaporRub. A trial is designed in which sick children receive Vicks VapoRub on their chest and others receive a placebo rub that lacks the distinctive wintergreen odor. But, the odor itself is felt to be related to how Vicks VapoRub actually works. Thus, it is the odor itself that creates the blinding challenge here.
The primary outcomes in this study are the duration of the child’s cold symptoms, as ascertained by pediatricians actually examining the children. So, pediatricians would come and listen to the infants’ chests: “Yeah, this chest is clear, but this other infant is still full of rhonchi,” and they would ascertain the outcome measure in this way. So, my blinding question to you is: how do you blind a trial of Vicks VapoRub given the conditions described? Namely, you put the VapoRub on the chest, it smells and the smell is the intervention—how do you blind such a trial?
The clever answer is that you should put Vicks VapoRub on the upper lips of all the examiners, so what they smell is Vicks VapoRub independent of whether the child they are examining also has the Vicks VapoRub or placebo on their chest. In this way, single blinding of the examiners is preserved and detection bias is averted. It is important to point out that double blinding could also be achieved by placing Vicks VapoRub on the child’s upper lip, but there is little reason to suspect that the infants being studied have a bias related to whether they smell the Vicks VapoRub.
The fourth potential source of internal bias is called “transfer bias.” Transfer bias is the selective loss to follow-up of patients from 1 of the 2 compared groups in the trial for a systematic reason. By systematic, I mean that that the drop-out is associated with the development of the outcome event or some impact of the intervention regarding the likelihood to develop the outcome event. As an example, if all patients respond favorably to a drug and everybody fails to follow up because they feel too good to come back, then that would bias the study towards nonefficacy even in the face of an efficacious intervention.
Finally, let’s consider a source of bias that can affect the “external validity,” or the generalizability of the study results to populations other than that included in the study itself. Dr. Feinstein calls this 5th type of bias “assembly bias” (Table 1).1 Assembly bias occurs when the results of the study cannot be reliably applied to populations outside the study itself.
For example, if I screen patients during a study of digoxin for heart rate control in atrial fibrillation, I could establish whether the subject was compliant or not by checking his/her serum digoxin levels. Serum levels of 0 indicate that the patient has not taken the digoxin. If I include a run-in period for the trial—an interval before the actual study when I am assessing potential subjects’ eligibility to participate—and check serum digoxin levels to include only patients who are shown to be taking the drug, then I am screening for study inclusion on compliance. In this way, I will have assembled a population that is highly compliant so that I can truly assess whether digoxin has efficacy in controlling the heart rate in patients with atrial fibrillation. At the same time, this study population is not highly representative of the population of patients with atrial fibrillation at large, because we know that rates of drug noncompliances may be as high as 30% to 40%. So, culling a population with run-in periods on demonstrated compliance criteria may be very important to assess efficacy (ie, whether the drug works), but this design will trade off on the effectiveness of the drug (ie, which asks the question “does the drug work in actual practice?”). This is because, in the yin-yang between assessing efficacy and assessing effectiveness, the focus on assessing efficacy naturally undermines the ability to assess whether the drug works in real-world conditions.
As another example of potential assembly bias, let’s say you are studying an antihypertensive drug at a Veterans Administration (VA) hospital, where most veterans are men. But you are treating women in your practice and wonder whether the drug, which works in a predominately male population, will work in your female patients. So, there could be assembly bias in applying the results of a VA study to a non-VA predominantly female population.
Having now described the design of clinical trials and the major sources of bias, let’s apply this thinking to the earliest clinical trial. James Lind, a British Naval officer, was credited with conducting the first clinical trial of citrus fruits for scurvy while sailing on the ship Salisbury in 1747.2 The question that Lind addressed was “does citrus fruit treat and prevent scurvy?” In describing this trial, Lind stated “I took 12 patients with scurvy, these patients were as similar as I could have them, had one diet common to all.” As you read this through your new Feinsteinian bias lens, Lind is addressing 2 potential sources of bias, namely, susceptibility bias and performance bias. In trying to make the “cases as similar as I could have them,” he is trying to avoid susceptibility bias and in “providing one diet common to all,” he is trying to avoid performance bias.
In terms of the intervention in this trial, these 12 patients were allocated in pairs to several interventions: a quart of cider a day, 25 drops of elixir of vitriol 3 times a day on an empty stomach, 2 spoonsful of vinegar 3 times a day on an empty stomach, ½ pint a day of sea water, 2 oranges and 1 lemon given every day, and a “bigness of nutmeg” 3 times per day. In describing the outcome of the trial, Lind states “the consequence was that the most sudden and visible good effects were perceived from the use of oranges and lemons; one of those who had taken them, being at the end of 6 days fit for duty. The spots were not indeed at that time quite off his body, nor his gums sound, but without any other medicine then a gargarism of elixir vitriol, he became quite healthy before we came into Plymouth which was on the 16th of June. The other was the best recovered of any in his condition; and being now deemed pretty well, was appointed nurse to the rest of the sick.”
In analyzing this trial, we could characterize it as a parallel controlled trial. Whether the allocation was done by randomization is not clear, but it was certainly an observational cohort study in that there were concurrent controls who were treated as similarly as possible except for the principal maneuver, which was the administration of citrus fruit. Already mentioned was the attention to averting susceptibility and performance bias. There was no evidence of compliance bias as the interventions were enforced, nor was there evidence of transfer bias because all subjects who were enrolled in the study completed the study because they were a captive group on a sailing ship. Finally, the likelihood of assembly bias seems small, as these sailors seemed to be representative of victims of scurvy in general, namely in being otherwise deprived of access to citrus fruits.
In terms of the statistical results of this study, subsequent analysis of the research showed that the impact of lemons and oranges was dramatic and showed a trend (P = .09) towards statistical significance. Notwithstanding the lack of a P < .05, Dr. Feinstein would likely say that this study satisfied the “intra-ocular test” in that the efficacy of the citrus fruit was so dramatic that it “hit you between the eyes.” He often argued that the widespread practice of prescribing penicillin for pneumococcal pneumonia was not based on the results of a convincing randomized controlled trial because the efficacy of penicillin in that setting was so dramatic that a randomized trial was not necessary (and potentially even unethical if the condition of “intra-ocular” efficacy was satisfied).
The final question to address in this lecture is whether randomized controlled trials, for all their rigor, always produce more reliable results than observational studies. This issue has been addressed by several authors.10–12 Sacks et al10 contended in 1983 that observational studies systematically overestimate the magnitude of association between exposure and outcome and therefore argued that randomized trials were more reliable than observational studies. Subsequent analyses tended to challenge this view.11,12 Specifically, Benson and Hartz11 compared the results of 136 reports regarding 19 different therapies that were studied between 1985 and 1998. In only 2 of the 19 analyses did the treatment effects in the observational studies fall outside the 95% confidence interval for the randomized controlled trial results. In this way, these authors argued that observational studies generally are concordant with the results of randomized trials. They stated that “our finding that observational studies and randomized controlled trials usually produce similar results differs from the conclusions of previous authors. The fundamental criticism of observational studies is that unrecognized confounding factors may distort the results. According to the conventional wisdom, this distortion is sufficiently common and unpredictable that observational studies are not liable and should not be funded. Our results suggested observational studies usually do provide valid information.”11
An additional analysis of this issue was performed by Concato et al,12 who identified 99 articles regarding 5 clinical topics. Again, the results from randomized trials were compared with those of observational cohort or case-controlled studies regarding the same intervention. The authors reported that “contrary to prevailing belief, the average results from well-designed observational studies did not systematically overestimate the magnitude of the associations between exposure and outcome as compared with the results of randomized, controlled trials on the same topic. Rather, the summary results of randomized, controlled trials and observational studies were remarkably similar.”12
On the basis of these studies, it appears that randomized control trials continue to serve as the gold standard in clinical research, but we must also recognize that circumstances often preclude the conduct of a randomized trial. As an example, consider a randomized trial of whether cigarette smoking is harmful, which, given the strong suspicion of harm, would be unethical in that patients cannot be randomized to smoke. Similarly, from the example before, a randomized trial of penicillin for pneumococcal pneumonia would be unethical because denying patients in the placebo group access to penicillin would exclude them from access to a drug that has “intra-ocular” efficacy. In circumstances like these, well-performed observational studies that are attentive to sources of bias can likely produce comparably reliable results to randomized trials.
In the end, of course, the interpretation of the study results requires the reader’s careful attention to potential sources of bias that can compromise study validity. The hope is that with Dr. Feinstein’s framework, you can be better equipped to think critically about study results that you review and to keenly ascertain whether there is any threat to internal or to external validity. Similarly, as you go on to design clinical trials yourselves, you can pay attention to these potential sources of bias that, if present, can compromise the reliability of the study conclusions internally or their applicability to patients outside of the study.
- Feinstein AR. Clinical Epidemiology: The Architecture of Clinical Research. Philadelphia, PA: WB Saunders; 1985.
- Thomas DP. Experiment versus authority: James Lind and Benjamin Rush. N Engl J Med 1969; 281:932–934.
- Downs JB, Klein EF Jr, Desautels D, Modell JH, Kirby RR. Intermittent mandatory ventilation: a new approach to weaning patients from mechanical ventilators. Chest 1973; 64:331–335.
- Brochard L, Rauss A, Benito S, et al. Comparison of three methods of gradual withdrawal from ventilatory support during weaning from mechanical ventilation. Am J Respir Crit Care Med 1994; 150:896–903.
- Chapman KR, Burdon JGW, Piitulainen E, et al; on behalf of the RAPID Trial Study Group. Intravenous augmentation treatment and lung density in severe 1 antitrypsin deficiency (RAPID): a randomised, double-blind, placebo-controlled trial. Lancet 2015; 386:360–368.
- Stoller JK, Wiedemann HP, Loke J, Snyder P, Virgulto J, Matthay RA. Terbutaline and diaphragm function in chronic obstructive pulmonary disease: a double-blind randomized clinical trial. Br J Dis Chest 1988; 82:242–250.
- Sehgal S, Velcheti V, Mukhopadhyay S, Stoller JK. Focal lung infiltrate complicating PD-1 inhibitor use: a new pattern of drug-associated lung toxicity? Respir Med Case Rep 2016; 19:118–120.
- Stoller JK, Moodie D, Schiavone WA, et al. Reduction of intrapulmonary shunt and resolution of digital clubbing associated with primary biliary cirrhosis after liver transplantation. Hepatology 1990; 11:54–58.
- Albert RK, Au DH, Blackford AL, et al; for the Long-Term Oxygen Treatment Trial Group. A randomized trial of long-term oxygen for COPD with moderate desaturation. N Engl J Med 2016; 375:1617–1627.
- Sacks HS, Chalmers TC, Smith H Jr. Sensitivity and specificity of clinical trials: randomized v historical controls. Arch Intern Med 1983; 143:753–755.
- Benson K, Hartz AJ. A comparison of observational studies and randomized, controlled trials. N Engl J Med 2000; 342:1878–1886.
- Concato J, Shah N, Horwitz RI. Randomized, controlled trials, observational studies, and the hierarchy of research designs. N Engl J Med 2000; 342:1887–1892.
I am flattered to present the inaugural talk in the biostatistics and clinical research design series on the architecture of clinical research. This content is based on the teachings of my mentor, Dr. Alvan Feinstein, who together with Dr. David Sackett, is credited with pioneering clinical epidemiology. Dr. Feinstein was a Sterling Professor at the Yale School of Medicine. His main opus of work is a book called, Clinical Epidemiology: The Architecture of Clinical Research.1 This paper is named in credit to Dr. Feinstein’s enormous contribution. I will review some important terms defined by Dr. Feinstein to provide the background necessary for the remainder of the talks in this series.
To start, I will frame this topic by asking the following question: Why do we do research? I’ll talk about the basic structure of research studies and provide a taxonomy, as Dr. Feinstein would say, a nomenclature with which to understand trial design and the sources of bias in those trials. Then, I will discuss these sources of bias in detail using the taxonomy that Dr. Feinstein described in his aforementioned book. Finally, I will share with you some examples of bias in clinical trials to help you better understand these concepts.
Now, the answer to the basic question posed above is: basically, we do cause-and-effect research to establish the causality of a risk factor or the efficacy of a therapy. Does cigarette smoking cause lung cancer? Does taking hydrochlorothiazide help systemic hypertension? Does air pollution worsen asthma? Does supplemental oxygen help patients with chronic obstructive pulmonary disease (COPD)?
Cause-and-effect research can be subsumed under 2 broad issues: causal risk factors and therapeutic efficacy. In his review of early false understandings in medicine that were based on anecdotal observation alone, Thomas cites many examples—“the undue longevity of useless and even harmful drugs can be laid at the door of authority,” ie, empiricism, lack of rigorous research.2 The field is full of these: yellow fever causality, the value of cupping, and even intermittent mandatory ventilation when it was described by John Downs in 1973 and touted as a superior mode for weaning patients from mechanical ventilation.3 Twenty-five years later, randomized controlled trials by Brochard et al4 indicated not only that intermittent mandatory ventilation was not the best mode to wean but was, in fact, the worst mode for weaning patients from mechanical ventilation compared with either pressure support or spontaneous breathing trials. Many more examples exist to demonstrate the false understandings that can be ascribed to lack of rigorous study or evidence in medicine.
Before systematically exploring the sources of bias in Feinstein’s construct, let us define some very basic terms from his book. Dr. Feinstein talks about the baseline state, which refers to the group of patients under study who are culled from a larger population to whom the results are intended to be applied (Figure 1).1 This baseline group is hopefully representative of this larger target population. As a nod to the later discussion, Dr. Feinstein would call bias introduced by unusual assembly of the study population from the larger intended population as “assembly bias.” So, if the group under study is not representative of either the patients you see or the world of patients with this condition or if there is something special or distinctively nonrepresentative about the study population, then the results may be subject to “assembly bias.” Assembly bias can compromise the so-called “external” validity of the study—its ability to be applied to populations beyond the study group.
Having assembled a baseline group for study, that group is classically allocated to 1 of 2 (or sometimes more than 2) compared therapies. In a controlled trial, patients can be allocated using a variety of strategies, including randomization. Using the paradigm diagram (Figure 1, which considers a 2-arm trial), patients are allocated to 1 of 2 compared groups—group A and group B. Then, in a treatment trial, 1 group receives the principal maneuver, which is the drug or intervention under study—for example, supplemental oxygen for patients with COPD. The comparative maneuver is allocated to group B, which also receives all the other treatments (called “co-maneuvers”) that are used to treat the condition under study. In a trial of supplemental oxygen for COPD evaluating lung function and exacerbation frequency as outcome measures, such co-maneuvers might include inhaled bronchodilators, inhaled corticosteroids, pulmonary rehabilitation, and Pneumovax vaccine. Ideally, these co-maneuvers are equally distributed between the compared groups (A and B).
So, in summary, we have a comparative maneuver, which is the nonadministration of supplemental oxygen in this proposed trial of supplemental oxygen in COPD, the principal maneuver—administration of oxygen—and all the co-maneuvers that are ideally equally distributed between both groups. This balanced distribution of co-maneuvers between the compared groups helps to ensure that any differences in the study outcome measures (ie, what is counted as the main impact of the intervention under study) can be solely attributed to the principal maneuver. When this condition—that the difference in outcomes can be reliably ascribed to the study intervention—is satisfied, the study is felt to be “internally” valid. As we will see, ensuring internal validity requires freedom from the many sources of what Dr. Feinstein calls “internal bias.”
Back to basic terms: “cohort” in Dr. Feinstein’s language is a group that shares common traits and is followed forward in a longitudinal study. The “outcome measure” is self-evident—it is what is being measured, with the “primary outcome” being the pre-defined measure that is considered the most important (and ideally most clinically relevant) impact of the study intervention. Later in this series of lectures, there will be discussions of power calculations and the so-called “effect size”—the magnitude of effect that the intervention is expected to produce and that is ideally deemed clinically important.
An important consideration in designing a trial is to define and declare the primary outcome measure carefully because defining the primary outcome measure has important implications for the study. I will provide an example from the alpha-1 antitrypsin deficiency literature. Some of you have probably read what has been called the RAPID trial.5 RAPID was a trial of augmentation therapy vs placebo in patients with severe alpha-1 antitrypsin deficiency. The primary outcome measure (which was pre-negotiated with the US Food and Drug Administration [FDA]) was computer tomography (CT) lung density determined at functional residual capacity (FRC) and total lung capacity (TLC). The trial failed to achieve statistical significance in regard to CT lung density, although the study authors argued that CT density measurements made at TLC were more reproducible than those made at FRC. When the results were analyzed by TLC alone, the results were statistically significant, but when they were analyzed with FRC and TLC combined, they were not. In the end, based on the pre-negotiated primary outcome measure of CT density based on both FRC and TLC, the FDA rejected the proposal for a label change to say that augmentation therapy slowed the loss of lung density even though the weight of evidence was clearly in its favor. This case exemplifies just how critical the choice of primary outcome measure can be.
The wash-out period refers to an interval in a subset of randomized trials called “crossover trials” in which the primary intervention is discontinued and the patient returns to his baseline state before the comparative maneuver is then implemented (Figure 2).6 In order to perform a crossover trial, it is important that the effects of the initial intervention can “wash out” or be fully extinguished. So, for example, in trials of radiation therapy vs surgery, it is impossible to do a crossover trial because the effects of radiation can never completely wash out nor can those of surgery, which are similarly permanent. For example, we cannot replace the colon once it is resected for cancer or replace the appendix once removed. Therefore, producing a wash-out requires some very specific pharmacokinetic and pharmacodynamic features in order for a crossover trial to be considered. Later talks in this series will discuss the enhanced statistical power of a crossover trial, where one is comparing every patient to him or herself rather than to another patient.
So, there is always an appetite to do a crossover trial as long as the criteria for wash-out can be met, namely again that the primary intervention can dissipate completely to the baseline state before the alternative intervention is implemented.
“Placebo” is a fairly self-evident and well-understood term; placebo refers to the administration of a maneuver in a way that is identical to the principal maneuver except that the placebo is not expected to exert any clinical effect.
“Blinding” is the unawareness of either the investigator or of the patient to which the intervention is being administered. “Single-blinding” refers to the condition in which either the study or the investigator (but not both) is unaware, and “double-blinding” refers to the condition in which both the subjects and the investigators are unaware. There can be some subtle issues that compromise whether the patient is aware of the intervention that he or she is receiving and that can potentially condition the patient’s response, particularly if there is any subjective component of the assessment of the outcome. So, blinding is important.
With these terms describing the elements of a clinical study now described, let us turn to the types of studies that comprise clinical research. The first group of study types is what Dr. Feinstein called descriptive studies—studies that simply describe phenomena without comparison to a control group. As an example of a descriptive study, Sehgal et al7 recently described the workup of a focal, segmental pneumonia in a patient taking pembrolizumab for lung cancer. In this paper, there were four other cases of focal pneumonia accompanying pembrolizumab use that were assembled from the literature, making this descriptive paper a so-called case series. A “case series” differs from a “single case report,” which reports a single patient experience. Though limited in their ability to establish cause and effect, case reports and case series can help researchers develop proof of principle, so I would not discount the value of case reports.8
I can cite a case report from of my own experience that demonstrates this point. In 1987, I saw a patient from Buffalo who had primary biliary cirrhosis and the hepatopulmonary syndrome (HPS). She was so debilitated by her HPS that she could not stand up without desaturating severely. Although she had normal liver synthetic function, she was severely debilitated by her HPS and the decision was made to offer her a liver transplant, which, at that time, was considered to be relatively contraindicated. Much to everyone’s amazement and satisfaction, her HPS completely resolved after the transplant surgery. Her oxygenation and alveolar-arterial oxygen gradient normalized, and her clubbing resolved. We reported this in a case report, which began to affect the way people thought about the feasibility of liver transplant for the HPS.8 The lesson is: do not underestimate the power of a thoughtful case report.
The second group of research study types is called “cohort studies,” in which one actually compares outcomes between 2 groups in the study. Cohort studies fall into the bucket of either “observational cohort studies,” in which allocation to the compared maneuvers is not performed by randomization but by any other strategy, and “randomized trials.” In observational studies, allocation could occur through physician choice, as when the physician prescribes a treatment to 1 group but not another, or by patient choice or circumstance. For example, an observational cohort study of the risk of cigarette smoking would compare outcomes between smokers and non-smokers where the patient choses to smoke under his/her own volition. Alternatively, the circumstances of an exposure could allocate someone to the principal maneuver, as when we are studying the effect of exposure to World Trade Center dust in the firefighters who responded or of exposure to nuclear radiation in Hiroshima survivors. These are examples of observational cohort studies that compare exposed individuals to unexposed individuals, where the exposure did not occur by randomization but by choice or unfortunate circumstance.
In contrast to observational studies, allocation in randomized trials occurs through a formal process. Randomization has the specific purpose of attempting to ensure that patients are allocated to 2 comparative groups from the baseline group with comparable risk for developing the outcome measure. When randomization is effective, differences in study outcomes can be reliably ascribed to the intervention rather than to differences in the baseline susceptibility of the compared groups.
While randomization is an excellent strategy to ensure baseline similarity between compared groups, randomization can fail, and its effectiveness must be checked. Specifically, in a randomized trial, it is customary to examine the compared groups at baseline on all features that can affect the likelihood of developing the outcome measure. If the groups turn out to be dissimilar at baseline in an important way, then the study is at risk for bias, which is specifically called “susceptibility bias” in Feinstein’s construct. Obviously, the larger number of baseline clinical and demographic features that can condition the likelihood of developing the outcome measure, the more difficult it is to achieve baseline similarity between compared groups and the more important it becomes to ensure that randomization has been effective. In this circumstance, larger numbers of participants in both compared groups are generally needed. More about susceptibility bias later.
There are generally 2 types of randomized trials: the so-called “parallel controlled trials” in which each group receives either the principal or the comparative maneuver and is followed and “crossover trials” in which each compared group receives both the principal maneuver and the co-maneuver at different times after an effective wash-out period. Wash-out was discussed above. Figure 2 shows an example of a crossover trial examining the effects of terbutaline on diaphragmatic function.6 The investigators administered terbutaline for a week, measured transdiaphragmatic pressures, gave the patient a terbutaline vacation (the “wash-out period”), and then crossed over those patients who were initially receiving terbutaline to placebo and initial placebo recipients to terbutaline, having remeasured diaphragmatic function after the wash-out period to assure that the patient’s diaphragmatic function prior to the second crossover was identical to his/her baseline state. If this return to baseline is accomplished, then the criteria from effective wash-out are satisfied.
As we begin to talk about sources of bias, consider a study in which we compare survival of patients allocated to surgery vs nonsurgical therapy for lung cancer (Figure 3).1 This study is subject to the first type of so-called “internal bias” in the Feinsteinian construct—so-called “selection bias.” For example, all patients treated surgically were considered healthy enough by their doctors to undergo surgery, whereas patients treated without surgery may have been deemed inoperable because of comorbidities, lung dysfunction, cardiac dysfunction, and so on. If the results of such a comparison show that the mortality rate among surgical patients in this study was lower, the question then becomes: is the improved survival in surgical candidates due to the superior efficacy of surgery vs other therapy or was the enhanced survival due to the surgical patients being healthier to begin with? You can intuitively sense that the answer to this question is that the enhanced survival may be due to the better health of patients treated surgically rather than to the surgery itself because of how the patients were selected to receive it. So, this is a simple example of what Dr. Feinstein would call “susceptibility bias.” Susceptibility bias occurs when the 2 baseline groups are not comparably at risk or susceptible to developing the outcome measure, leading the naïve investigator in this specific example to attribute the difference in outcomes to the superiority of surgery when in fact it may have nothing to do with the surgery vs. the other maneuver. When susceptibility bias is in play, the difference between the outcomes in the compared groups could be attributed to the baseline imbalance of the groups rather than to the principal maneuver itself.
Turning back to the taxonomy of bias, there are four types that can threaten internal validity—“susceptibility,” “performance,” “detection,” and “transfer” bias—and 1 type of bias (called “external bias”) that can affect the generalizability of the study called “assembly bias” (Table 1).
Figure 4 shows where these various sources of bias appear in the architecture of a clinical trial. As just discussed, susceptibility bias affects the baseline state and the comparability of the groups. Performance bias relates to how effective and how comparably the co-maneuvers are given and whether the primary intervention is potent enough to affect an outcome. Both transfer and detection bias operate in detecting the outcome, especially regarding the rigor and frequency with which they are investigated. Transfer bias has to do with selective loss to follow-up of those included in the trial. If there is a systematic reason for loss to follow-up that is related to the impact of the intervention, then the study is at risk for transfer bias. For example, in a randomized trial of drug A vs placebo for pneumonia, if drug A is effective but all the drug A recipients fail to follow-up because they feel too good to return for follow-up, then transfer bias could be causing the study to show nonefficacy even though the drug works. So, if those who respond favorably are systematically lost to follow-up, and if all the patients who felt lousy wanted to see the doctor and came back for follow-up, such transfer bias would bias towards nonefficacy. Specifically, only patients remaining in the trial would be those who failed to respond and that would dilute any difference between the 2 groups despite the active efficacy of drug A.
Hopefully, you are already beginning to get a sense that one has to be extremely disciplined in thinking about each of these sources of bias because they can have some very subtle nuances in randomized trials that can easily escape attention.
Returning to sources of bias, let’s consider the second type of bias, “performance bias.” Performance bias relates to the administration of the compared maneuvers—the primary or principal maneuver, compared with the comparative maneuver. Performance bias can occur when the main maneuver is not administered adequately or when the co-maneuvers are administered in an imbalanced way between the compared groups. Consider the example of the Long-Term Oxygen Treatment Trial (LOTT) trial, which compared use of supplemental oxygen with no supplemental oxygen in patients with stable COPD and resting or exercise-induced moderate desaturation.9 The principal outcome measure of LOTT was all-cause hospitalization or death. In such a study, many potential sources of performance bias exist. For example, performance bias might exist if none of the patients allocated to oxygen actually used supplemental oxygen. Alternately, to the extent that use of inhaled corticosteroids or antimuscarinic agents lessens the risk of COPD exacerbation, performance bias could occur if use of these co-maneuvers was imbalanced between the compared groups. As a specific extreme circumstance, if all patients in the nonoxygen group used these inhalers but none of the patients in the oxygen group did, then a lack of difference between exacerbation frequency could be related to this imbalance in co-maneuvers (a form of performance bias) rather than to the lack of efficacy of supplemental oxygen.
“Compliance bias” is a subset of performance bias which occurs when 2 conditions are satisfied: (1) the main maneuver is not administered adequately, and (2) the investigator is unaware of that nonreceipt so that this cannot be accounted for in interpreting the study results. For example, if a drug has efficacy but if no one in the treatment arm of the trial takes the drug, the absence of a difference in outcomes between the compared groups will be ascribed to nonefficacy, whereas “compliance bias” (ie, no one actually took the drug) could actually be the cause. Ideally, randomized studies should be evaluated on an “intention to treat” basis irrespective of compliance, but there is an analytic approach called “per protocol” analysis in which you can analyze the results according to whether the patient actually used the intervention in an effective way. “Per protocol” analysis is a secondary analysis of the primary results but it can nonetheless help determine whether the negative result is likely related to noncompliance or not.
A third type of internal bias, “detection bias,” is fairly straightforward. Detection bias is related to how avidly and how comparably the outcomes are measured between the 2 compared groups. Let’s say that you are conducting a trial of a new antibiotic and the primary outcome is colony counts on petri dishes of plated collected specimens. If the technicians who read the petri dish counts are unblinded, they may look at the colony counts with a biased eye, seeing fewer colonies on plates collected from patients receiving the antibiotic.
Overall, detection bias occurs when outcomes are ascertained or detected unequally between the compared groups, and detection bias can involve any of the following: is there comparable surveillance of the 2 groups for analysis of the outcome measure? Are the diagnostic tests comparably performed in both groups and is the interpretation comparably unbiased with equipoise? Investigators who know which patients are receiving an active drug and those who are not could experience subliminal bias that renders them more likely to find that the drug under study is efficacious.
Depending on the principal study maneuver, ensuring blinding can be challenging. To demonstrate this point, let’s consider the example of conducting a randomized control trial of Vicks VapoRub. Vicks VapoRub is an old product that smells like wintergreen and that mothers used to rub on the chests of their infants in the hope of speeding recovery from colds and bronchitis episodes. It was felt that the distinctive smell of the product was materially related to wintergreen, which gives rise to the odor. So, imagine a randomized trial of Vicks VaporRub. A trial is designed in which sick children receive Vicks VapoRub on their chest and others receive a placebo rub that lacks the distinctive wintergreen odor. But, the odor itself is felt to be related to how Vicks VapoRub actually works. Thus, it is the odor itself that creates the blinding challenge here.
The primary outcomes in this study are the duration of the child’s cold symptoms, as ascertained by pediatricians actually examining the children. So, pediatricians would come and listen to the infants’ chests: “Yeah, this chest is clear, but this other infant is still full of rhonchi,” and they would ascertain the outcome measure in this way. So, my blinding question to you is: how do you blind a trial of Vicks VapoRub given the conditions described? Namely, you put the VapoRub on the chest, it smells and the smell is the intervention—how do you blind such a trial?
The clever answer is that you should put Vicks VapoRub on the upper lips of all the examiners, so what they smell is Vicks VapoRub independent of whether the child they are examining also has the Vicks VapoRub or placebo on their chest. In this way, single blinding of the examiners is preserved and detection bias is averted. It is important to point out that double blinding could also be achieved by placing Vicks VapoRub on the child’s upper lip, but there is little reason to suspect that the infants being studied have a bias related to whether they smell the Vicks VapoRub.
The fourth potential source of internal bias is called “transfer bias.” Transfer bias is the selective loss to follow-up of patients from 1 of the 2 compared groups in the trial for a systematic reason. By systematic, I mean that that the drop-out is associated with the development of the outcome event or some impact of the intervention regarding the likelihood to develop the outcome event. As an example, if all patients respond favorably to a drug and everybody fails to follow up because they feel too good to come back, then that would bias the study towards nonefficacy even in the face of an efficacious intervention.
Finally, let’s consider a source of bias that can affect the “external validity,” or the generalizability of the study results to populations other than that included in the study itself. Dr. Feinstein calls this 5th type of bias “assembly bias” (Table 1).1 Assembly bias occurs when the results of the study cannot be reliably applied to populations outside the study itself.
For example, if I screen patients during a study of digoxin for heart rate control in atrial fibrillation, I could establish whether the subject was compliant or not by checking his/her serum digoxin levels. Serum levels of 0 indicate that the patient has not taken the digoxin. If I include a run-in period for the trial—an interval before the actual study when I am assessing potential subjects’ eligibility to participate—and check serum digoxin levels to include only patients who are shown to be taking the drug, then I am screening for study inclusion on compliance. In this way, I will have assembled a population that is highly compliant so that I can truly assess whether digoxin has efficacy in controlling the heart rate in patients with atrial fibrillation. At the same time, this study population is not highly representative of the population of patients with atrial fibrillation at large, because we know that rates of drug noncompliances may be as high as 30% to 40%. So, culling a population with run-in periods on demonstrated compliance criteria may be very important to assess efficacy (ie, whether the drug works), but this design will trade off on the effectiveness of the drug (ie, which asks the question “does the drug work in actual practice?”). This is because, in the yin-yang between assessing efficacy and assessing effectiveness, the focus on assessing efficacy naturally undermines the ability to assess whether the drug works in real-world conditions.
As another example of potential assembly bias, let’s say you are studying an antihypertensive drug at a Veterans Administration (VA) hospital, where most veterans are men. But you are treating women in your practice and wonder whether the drug, which works in a predominately male population, will work in your female patients. So, there could be assembly bias in applying the results of a VA study to a non-VA predominantly female population.
Having now described the design of clinical trials and the major sources of bias, let’s apply this thinking to the earliest clinical trial. James Lind, a British Naval officer, was credited with conducting the first clinical trial of citrus fruits for scurvy while sailing on the ship Salisbury in 1747.2 The question that Lind addressed was “does citrus fruit treat and prevent scurvy?” In describing this trial, Lind stated “I took 12 patients with scurvy, these patients were as similar as I could have them, had one diet common to all.” As you read this through your new Feinsteinian bias lens, Lind is addressing 2 potential sources of bias, namely, susceptibility bias and performance bias. In trying to make the “cases as similar as I could have them,” he is trying to avoid susceptibility bias and in “providing one diet common to all,” he is trying to avoid performance bias.
In terms of the intervention in this trial, these 12 patients were allocated in pairs to several interventions: a quart of cider a day, 25 drops of elixir of vitriol 3 times a day on an empty stomach, 2 spoonsful of vinegar 3 times a day on an empty stomach, ½ pint a day of sea water, 2 oranges and 1 lemon given every day, and a “bigness of nutmeg” 3 times per day. In describing the outcome of the trial, Lind states “the consequence was that the most sudden and visible good effects were perceived from the use of oranges and lemons; one of those who had taken them, being at the end of 6 days fit for duty. The spots were not indeed at that time quite off his body, nor his gums sound, but without any other medicine then a gargarism of elixir vitriol, he became quite healthy before we came into Plymouth which was on the 16th of June. The other was the best recovered of any in his condition; and being now deemed pretty well, was appointed nurse to the rest of the sick.”
In analyzing this trial, we could characterize it as a parallel controlled trial. Whether the allocation was done by randomization is not clear, but it was certainly an observational cohort study in that there were concurrent controls who were treated as similarly as possible except for the principal maneuver, which was the administration of citrus fruit. Already mentioned was the attention to averting susceptibility and performance bias. There was no evidence of compliance bias as the interventions were enforced, nor was there evidence of transfer bias because all subjects who were enrolled in the study completed the study because they were a captive group on a sailing ship. Finally, the likelihood of assembly bias seems small, as these sailors seemed to be representative of victims of scurvy in general, namely in being otherwise deprived of access to citrus fruits.
In terms of the statistical results of this study, subsequent analysis of the research showed that the impact of lemons and oranges was dramatic and showed a trend (P = .09) towards statistical significance. Notwithstanding the lack of a P < .05, Dr. Feinstein would likely say that this study satisfied the “intra-ocular test” in that the efficacy of the citrus fruit was so dramatic that it “hit you between the eyes.” He often argued that the widespread practice of prescribing penicillin for pneumococcal pneumonia was not based on the results of a convincing randomized controlled trial because the efficacy of penicillin in that setting was so dramatic that a randomized trial was not necessary (and potentially even unethical if the condition of “intra-ocular” efficacy was satisfied).
The final question to address in this lecture is whether randomized controlled trials, for all their rigor, always produce more reliable results than observational studies. This issue has been addressed by several authors.10–12 Sacks et al10 contended in 1983 that observational studies systematically overestimate the magnitude of association between exposure and outcome and therefore argued that randomized trials were more reliable than observational studies. Subsequent analyses tended to challenge this view.11,12 Specifically, Benson and Hartz11 compared the results of 136 reports regarding 19 different therapies that were studied between 1985 and 1998. In only 2 of the 19 analyses did the treatment effects in the observational studies fall outside the 95% confidence interval for the randomized controlled trial results. In this way, these authors argued that observational studies generally are concordant with the results of randomized trials. They stated that “our finding that observational studies and randomized controlled trials usually produce similar results differs from the conclusions of previous authors. The fundamental criticism of observational studies is that unrecognized confounding factors may distort the results. According to the conventional wisdom, this distortion is sufficiently common and unpredictable that observational studies are not liable and should not be funded. Our results suggested observational studies usually do provide valid information.”11
An additional analysis of this issue was performed by Concato et al,12 who identified 99 articles regarding 5 clinical topics. Again, the results from randomized trials were compared with those of observational cohort or case-controlled studies regarding the same intervention. The authors reported that “contrary to prevailing belief, the average results from well-designed observational studies did not systematically overestimate the magnitude of the associations between exposure and outcome as compared with the results of randomized, controlled trials on the same topic. Rather, the summary results of randomized, controlled trials and observational studies were remarkably similar.”12
On the basis of these studies, it appears that randomized control trials continue to serve as the gold standard in clinical research, but we must also recognize that circumstances often preclude the conduct of a randomized trial. As an example, consider a randomized trial of whether cigarette smoking is harmful, which, given the strong suspicion of harm, would be unethical in that patients cannot be randomized to smoke. Similarly, from the example before, a randomized trial of penicillin for pneumococcal pneumonia would be unethical because denying patients in the placebo group access to penicillin would exclude them from access to a drug that has “intra-ocular” efficacy. In circumstances like these, well-performed observational studies that are attentive to sources of bias can likely produce comparably reliable results to randomized trials.
In the end, of course, the interpretation of the study results requires the reader’s careful attention to potential sources of bias that can compromise study validity. The hope is that with Dr. Feinstein’s framework, you can be better equipped to think critically about study results that you review and to keenly ascertain whether there is any threat to internal or to external validity. Similarly, as you go on to design clinical trials yourselves, you can pay attention to these potential sources of bias that, if present, can compromise the reliability of the study conclusions internally or their applicability to patients outside of the study.
I am flattered to present the inaugural talk in the biostatistics and clinical research design series on the architecture of clinical research. This content is based on the teachings of my mentor, Dr. Alvan Feinstein, who together with Dr. David Sackett, is credited with pioneering clinical epidemiology. Dr. Feinstein was a Sterling Professor at the Yale School of Medicine. His main opus of work is a book called, Clinical Epidemiology: The Architecture of Clinical Research.1 This paper is named in credit to Dr. Feinstein’s enormous contribution. I will review some important terms defined by Dr. Feinstein to provide the background necessary for the remainder of the talks in this series.
To start, I will frame this topic by asking the following question: Why do we do research? I’ll talk about the basic structure of research studies and provide a taxonomy, as Dr. Feinstein would say, a nomenclature with which to understand trial design and the sources of bias in those trials. Then, I will discuss these sources of bias in detail using the taxonomy that Dr. Feinstein described in his aforementioned book. Finally, I will share with you some examples of bias in clinical trials to help you better understand these concepts.
Now, the answer to the basic question posed above is: basically, we do cause-and-effect research to establish the causality of a risk factor or the efficacy of a therapy. Does cigarette smoking cause lung cancer? Does taking hydrochlorothiazide help systemic hypertension? Does air pollution worsen asthma? Does supplemental oxygen help patients with chronic obstructive pulmonary disease (COPD)?
Cause-and-effect research can be subsumed under 2 broad issues: causal risk factors and therapeutic efficacy. In his review of early false understandings in medicine that were based on anecdotal observation alone, Thomas cites many examples—“the undue longevity of useless and even harmful drugs can be laid at the door of authority,” ie, empiricism, lack of rigorous research.2 The field is full of these: yellow fever causality, the value of cupping, and even intermittent mandatory ventilation when it was described by John Downs in 1973 and touted as a superior mode for weaning patients from mechanical ventilation.3 Twenty-five years later, randomized controlled trials by Brochard et al4 indicated not only that intermittent mandatory ventilation was not the best mode to wean but was, in fact, the worst mode for weaning patients from mechanical ventilation compared with either pressure support or spontaneous breathing trials. Many more examples exist to demonstrate the false understandings that can be ascribed to lack of rigorous study or evidence in medicine.
Before systematically exploring the sources of bias in Feinstein’s construct, let us define some very basic terms from his book. Dr. Feinstein talks about the baseline state, which refers to the group of patients under study who are culled from a larger population to whom the results are intended to be applied (Figure 1).1 This baseline group is hopefully representative of this larger target population. As a nod to the later discussion, Dr. Feinstein would call bias introduced by unusual assembly of the study population from the larger intended population as “assembly bias.” So, if the group under study is not representative of either the patients you see or the world of patients with this condition or if there is something special or distinctively nonrepresentative about the study population, then the results may be subject to “assembly bias.” Assembly bias can compromise the so-called “external” validity of the study—its ability to be applied to populations beyond the study group.
Having assembled a baseline group for study, that group is classically allocated to 1 of 2 (or sometimes more than 2) compared therapies. In a controlled trial, patients can be allocated using a variety of strategies, including randomization. Using the paradigm diagram (Figure 1, which considers a 2-arm trial), patients are allocated to 1 of 2 compared groups—group A and group B. Then, in a treatment trial, 1 group receives the principal maneuver, which is the drug or intervention under study—for example, supplemental oxygen for patients with COPD. The comparative maneuver is allocated to group B, which also receives all the other treatments (called “co-maneuvers”) that are used to treat the condition under study. In a trial of supplemental oxygen for COPD evaluating lung function and exacerbation frequency as outcome measures, such co-maneuvers might include inhaled bronchodilators, inhaled corticosteroids, pulmonary rehabilitation, and Pneumovax vaccine. Ideally, these co-maneuvers are equally distributed between the compared groups (A and B).
So, in summary, we have a comparative maneuver, which is the nonadministration of supplemental oxygen in this proposed trial of supplemental oxygen in COPD, the principal maneuver—administration of oxygen—and all the co-maneuvers that are ideally equally distributed between both groups. This balanced distribution of co-maneuvers between the compared groups helps to ensure that any differences in the study outcome measures (ie, what is counted as the main impact of the intervention under study) can be solely attributed to the principal maneuver. When this condition—that the difference in outcomes can be reliably ascribed to the study intervention—is satisfied, the study is felt to be “internally” valid. As we will see, ensuring internal validity requires freedom from the many sources of what Dr. Feinstein calls “internal bias.”
Back to basic terms: “cohort” in Dr. Feinstein’s language is a group that shares common traits and is followed forward in a longitudinal study. The “outcome measure” is self-evident—it is what is being measured, with the “primary outcome” being the pre-defined measure that is considered the most important (and ideally most clinically relevant) impact of the study intervention. Later in this series of lectures, there will be discussions of power calculations and the so-called “effect size”—the magnitude of effect that the intervention is expected to produce and that is ideally deemed clinically important.
An important consideration in designing a trial is to define and declare the primary outcome measure carefully because defining the primary outcome measure has important implications for the study. I will provide an example from the alpha-1 antitrypsin deficiency literature. Some of you have probably read what has been called the RAPID trial.5 RAPID was a trial of augmentation therapy vs placebo in patients with severe alpha-1 antitrypsin deficiency. The primary outcome measure (which was pre-negotiated with the US Food and Drug Administration [FDA]) was computer tomography (CT) lung density determined at functional residual capacity (FRC) and total lung capacity (TLC). The trial failed to achieve statistical significance in regard to CT lung density, although the study authors argued that CT density measurements made at TLC were more reproducible than those made at FRC. When the results were analyzed by TLC alone, the results were statistically significant, but when they were analyzed with FRC and TLC combined, they were not. In the end, based on the pre-negotiated primary outcome measure of CT density based on both FRC and TLC, the FDA rejected the proposal for a label change to say that augmentation therapy slowed the loss of lung density even though the weight of evidence was clearly in its favor. This case exemplifies just how critical the choice of primary outcome measure can be.
The wash-out period refers to an interval in a subset of randomized trials called “crossover trials” in which the primary intervention is discontinued and the patient returns to his baseline state before the comparative maneuver is then implemented (Figure 2).6 In order to perform a crossover trial, it is important that the effects of the initial intervention can “wash out” or be fully extinguished. So, for example, in trials of radiation therapy vs surgery, it is impossible to do a crossover trial because the effects of radiation can never completely wash out nor can those of surgery, which are similarly permanent. For example, we cannot replace the colon once it is resected for cancer or replace the appendix once removed. Therefore, producing a wash-out requires some very specific pharmacokinetic and pharmacodynamic features in order for a crossover trial to be considered. Later talks in this series will discuss the enhanced statistical power of a crossover trial, where one is comparing every patient to him or herself rather than to another patient.
So, there is always an appetite to do a crossover trial as long as the criteria for wash-out can be met, namely again that the primary intervention can dissipate completely to the baseline state before the alternative intervention is implemented.
“Placebo” is a fairly self-evident and well-understood term; placebo refers to the administration of a maneuver in a way that is identical to the principal maneuver except that the placebo is not expected to exert any clinical effect.
“Blinding” is the unawareness of either the investigator or of the patient to which the intervention is being administered. “Single-blinding” refers to the condition in which either the study or the investigator (but not both) is unaware, and “double-blinding” refers to the condition in which both the subjects and the investigators are unaware. There can be some subtle issues that compromise whether the patient is aware of the intervention that he or she is receiving and that can potentially condition the patient’s response, particularly if there is any subjective component of the assessment of the outcome. So, blinding is important.
With these terms describing the elements of a clinical study now described, let us turn to the types of studies that comprise clinical research. The first group of study types is what Dr. Feinstein called descriptive studies—studies that simply describe phenomena without comparison to a control group. As an example of a descriptive study, Sehgal et al7 recently described the workup of a focal, segmental pneumonia in a patient taking pembrolizumab for lung cancer. In this paper, there were four other cases of focal pneumonia accompanying pembrolizumab use that were assembled from the literature, making this descriptive paper a so-called case series. A “case series” differs from a “single case report,” which reports a single patient experience. Though limited in their ability to establish cause and effect, case reports and case series can help researchers develop proof of principle, so I would not discount the value of case reports.8
I can cite a case report from of my own experience that demonstrates this point. In 1987, I saw a patient from Buffalo who had primary biliary cirrhosis and the hepatopulmonary syndrome (HPS). She was so debilitated by her HPS that she could not stand up without desaturating severely. Although she had normal liver synthetic function, she was severely debilitated by her HPS and the decision was made to offer her a liver transplant, which, at that time, was considered to be relatively contraindicated. Much to everyone’s amazement and satisfaction, her HPS completely resolved after the transplant surgery. Her oxygenation and alveolar-arterial oxygen gradient normalized, and her clubbing resolved. We reported this in a case report, which began to affect the way people thought about the feasibility of liver transplant for the HPS.8 The lesson is: do not underestimate the power of a thoughtful case report.
The second group of research study types is called “cohort studies,” in which one actually compares outcomes between 2 groups in the study. Cohort studies fall into the bucket of either “observational cohort studies,” in which allocation to the compared maneuvers is not performed by randomization but by any other strategy, and “randomized trials.” In observational studies, allocation could occur through physician choice, as when the physician prescribes a treatment to 1 group but not another, or by patient choice or circumstance. For example, an observational cohort study of the risk of cigarette smoking would compare outcomes between smokers and non-smokers where the patient choses to smoke under his/her own volition. Alternatively, the circumstances of an exposure could allocate someone to the principal maneuver, as when we are studying the effect of exposure to World Trade Center dust in the firefighters who responded or of exposure to nuclear radiation in Hiroshima survivors. These are examples of observational cohort studies that compare exposed individuals to unexposed individuals, where the exposure did not occur by randomization but by choice or unfortunate circumstance.
In contrast to observational studies, allocation in randomized trials occurs through a formal process. Randomization has the specific purpose of attempting to ensure that patients are allocated to 2 comparative groups from the baseline group with comparable risk for developing the outcome measure. When randomization is effective, differences in study outcomes can be reliably ascribed to the intervention rather than to differences in the baseline susceptibility of the compared groups.
While randomization is an excellent strategy to ensure baseline similarity between compared groups, randomization can fail, and its effectiveness must be checked. Specifically, in a randomized trial, it is customary to examine the compared groups at baseline on all features that can affect the likelihood of developing the outcome measure. If the groups turn out to be dissimilar at baseline in an important way, then the study is at risk for bias, which is specifically called “susceptibility bias” in Feinstein’s construct. Obviously, the larger number of baseline clinical and demographic features that can condition the likelihood of developing the outcome measure, the more difficult it is to achieve baseline similarity between compared groups and the more important it becomes to ensure that randomization has been effective. In this circumstance, larger numbers of participants in both compared groups are generally needed. More about susceptibility bias later.
There are generally 2 types of randomized trials: the so-called “parallel controlled trials” in which each group receives either the principal or the comparative maneuver and is followed and “crossover trials” in which each compared group receives both the principal maneuver and the co-maneuver at different times after an effective wash-out period. Wash-out was discussed above. Figure 2 shows an example of a crossover trial examining the effects of terbutaline on diaphragmatic function.6 The investigators administered terbutaline for a week, measured transdiaphragmatic pressures, gave the patient a terbutaline vacation (the “wash-out period”), and then crossed over those patients who were initially receiving terbutaline to placebo and initial placebo recipients to terbutaline, having remeasured diaphragmatic function after the wash-out period to assure that the patient’s diaphragmatic function prior to the second crossover was identical to his/her baseline state. If this return to baseline is accomplished, then the criteria from effective wash-out are satisfied.
As we begin to talk about sources of bias, consider a study in which we compare survival of patients allocated to surgery vs nonsurgical therapy for lung cancer (Figure 3).1 This study is subject to the first type of so-called “internal bias” in the Feinsteinian construct—so-called “selection bias.” For example, all patients treated surgically were considered healthy enough by their doctors to undergo surgery, whereas patients treated without surgery may have been deemed inoperable because of comorbidities, lung dysfunction, cardiac dysfunction, and so on. If the results of such a comparison show that the mortality rate among surgical patients in this study was lower, the question then becomes: is the improved survival in surgical candidates due to the superior efficacy of surgery vs other therapy or was the enhanced survival due to the surgical patients being healthier to begin with? You can intuitively sense that the answer to this question is that the enhanced survival may be due to the better health of patients treated surgically rather than to the surgery itself because of how the patients were selected to receive it. So, this is a simple example of what Dr. Feinstein would call “susceptibility bias.” Susceptibility bias occurs when the 2 baseline groups are not comparably at risk or susceptible to developing the outcome measure, leading the naïve investigator in this specific example to attribute the difference in outcomes to the superiority of surgery when in fact it may have nothing to do with the surgery vs. the other maneuver. When susceptibility bias is in play, the difference between the outcomes in the compared groups could be attributed to the baseline imbalance of the groups rather than to the principal maneuver itself.
Turning back to the taxonomy of bias, there are four types that can threaten internal validity—“susceptibility,” “performance,” “detection,” and “transfer” bias—and 1 type of bias (called “external bias”) that can affect the generalizability of the study called “assembly bias” (Table 1).
Figure 4 shows where these various sources of bias appear in the architecture of a clinical trial. As just discussed, susceptibility bias affects the baseline state and the comparability of the groups. Performance bias relates to how effective and how comparably the co-maneuvers are given and whether the primary intervention is potent enough to affect an outcome. Both transfer and detection bias operate in detecting the outcome, especially regarding the rigor and frequency with which they are investigated. Transfer bias has to do with selective loss to follow-up of those included in the trial. If there is a systematic reason for loss to follow-up that is related to the impact of the intervention, then the study is at risk for transfer bias. For example, in a randomized trial of drug A vs placebo for pneumonia, if drug A is effective but all the drug A recipients fail to follow-up because they feel too good to return for follow-up, then transfer bias could be causing the study to show nonefficacy even though the drug works. So, if those who respond favorably are systematically lost to follow-up, and if all the patients who felt lousy wanted to see the doctor and came back for follow-up, such transfer bias would bias towards nonefficacy. Specifically, only patients remaining in the trial would be those who failed to respond and that would dilute any difference between the 2 groups despite the active efficacy of drug A.
Hopefully, you are already beginning to get a sense that one has to be extremely disciplined in thinking about each of these sources of bias because they can have some very subtle nuances in randomized trials that can easily escape attention.
Returning to sources of bias, let’s consider the second type of bias, “performance bias.” Performance bias relates to the administration of the compared maneuvers—the primary or principal maneuver, compared with the comparative maneuver. Performance bias can occur when the main maneuver is not administered adequately or when the co-maneuvers are administered in an imbalanced way between the compared groups. Consider the example of the Long-Term Oxygen Treatment Trial (LOTT) trial, which compared use of supplemental oxygen with no supplemental oxygen in patients with stable COPD and resting or exercise-induced moderate desaturation.9 The principal outcome measure of LOTT was all-cause hospitalization or death. In such a study, many potential sources of performance bias exist. For example, performance bias might exist if none of the patients allocated to oxygen actually used supplemental oxygen. Alternately, to the extent that use of inhaled corticosteroids or antimuscarinic agents lessens the risk of COPD exacerbation, performance bias could occur if use of these co-maneuvers was imbalanced between the compared groups. As a specific extreme circumstance, if all patients in the nonoxygen group used these inhalers but none of the patients in the oxygen group did, then a lack of difference between exacerbation frequency could be related to this imbalance in co-maneuvers (a form of performance bias) rather than to the lack of efficacy of supplemental oxygen.
“Compliance bias” is a subset of performance bias which occurs when 2 conditions are satisfied: (1) the main maneuver is not administered adequately, and (2) the investigator is unaware of that nonreceipt so that this cannot be accounted for in interpreting the study results. For example, if a drug has efficacy but if no one in the treatment arm of the trial takes the drug, the absence of a difference in outcomes between the compared groups will be ascribed to nonefficacy, whereas “compliance bias” (ie, no one actually took the drug) could actually be the cause. Ideally, randomized studies should be evaluated on an “intention to treat” basis irrespective of compliance, but there is an analytic approach called “per protocol” analysis in which you can analyze the results according to whether the patient actually used the intervention in an effective way. “Per protocol” analysis is a secondary analysis of the primary results but it can nonetheless help determine whether the negative result is likely related to noncompliance or not.
A third type of internal bias, “detection bias,” is fairly straightforward. Detection bias is related to how avidly and how comparably the outcomes are measured between the 2 compared groups. Let’s say that you are conducting a trial of a new antibiotic and the primary outcome is colony counts on petri dishes of plated collected specimens. If the technicians who read the petri dish counts are unblinded, they may look at the colony counts with a biased eye, seeing fewer colonies on plates collected from patients receiving the antibiotic.
Overall, detection bias occurs when outcomes are ascertained or detected unequally between the compared groups, and detection bias can involve any of the following: is there comparable surveillance of the 2 groups for analysis of the outcome measure? Are the diagnostic tests comparably performed in both groups and is the interpretation comparably unbiased with equipoise? Investigators who know which patients are receiving an active drug and those who are not could experience subliminal bias that renders them more likely to find that the drug under study is efficacious.
Depending on the principal study maneuver, ensuring blinding can be challenging. To demonstrate this point, let’s consider the example of conducting a randomized control trial of Vicks VapoRub. Vicks VapoRub is an old product that smells like wintergreen and that mothers used to rub on the chests of their infants in the hope of speeding recovery from colds and bronchitis episodes. It was felt that the distinctive smell of the product was materially related to wintergreen, which gives rise to the odor. So, imagine a randomized trial of Vicks VaporRub. A trial is designed in which sick children receive Vicks VapoRub on their chest and others receive a placebo rub that lacks the distinctive wintergreen odor. But, the odor itself is felt to be related to how Vicks VapoRub actually works. Thus, it is the odor itself that creates the blinding challenge here.
The primary outcomes in this study are the duration of the child’s cold symptoms, as ascertained by pediatricians actually examining the children. So, pediatricians would come and listen to the infants’ chests: “Yeah, this chest is clear, but this other infant is still full of rhonchi,” and they would ascertain the outcome measure in this way. So, my blinding question to you is: how do you blind a trial of Vicks VapoRub given the conditions described? Namely, you put the VapoRub on the chest, it smells and the smell is the intervention—how do you blind such a trial?
The clever answer is that you should put Vicks VapoRub on the upper lips of all the examiners, so what they smell is Vicks VapoRub independent of whether the child they are examining also has the Vicks VapoRub or placebo on their chest. In this way, single blinding of the examiners is preserved and detection bias is averted. It is important to point out that double blinding could also be achieved by placing Vicks VapoRub on the child’s upper lip, but there is little reason to suspect that the infants being studied have a bias related to whether they smell the Vicks VapoRub.
The fourth potential source of internal bias is called “transfer bias.” Transfer bias is the selective loss to follow-up of patients from 1 of the 2 compared groups in the trial for a systematic reason. By systematic, I mean that that the drop-out is associated with the development of the outcome event or some impact of the intervention regarding the likelihood to develop the outcome event. As an example, if all patients respond favorably to a drug and everybody fails to follow up because they feel too good to come back, then that would bias the study towards nonefficacy even in the face of an efficacious intervention.
Finally, let’s consider a source of bias that can affect the “external validity,” or the generalizability of the study results to populations other than that included in the study itself. Dr. Feinstein calls this 5th type of bias “assembly bias” (Table 1).1 Assembly bias occurs when the results of the study cannot be reliably applied to populations outside the study itself.
For example, if I screen patients during a study of digoxin for heart rate control in atrial fibrillation, I could establish whether the subject was compliant or not by checking his/her serum digoxin levels. Serum levels of 0 indicate that the patient has not taken the digoxin. If I include a run-in period for the trial—an interval before the actual study when I am assessing potential subjects’ eligibility to participate—and check serum digoxin levels to include only patients who are shown to be taking the drug, then I am screening for study inclusion on compliance. In this way, I will have assembled a population that is highly compliant so that I can truly assess whether digoxin has efficacy in controlling the heart rate in patients with atrial fibrillation. At the same time, this study population is not highly representative of the population of patients with atrial fibrillation at large, because we know that rates of drug noncompliances may be as high as 30% to 40%. So, culling a population with run-in periods on demonstrated compliance criteria may be very important to assess efficacy (ie, whether the drug works), but this design will trade off on the effectiveness of the drug (ie, which asks the question “does the drug work in actual practice?”). This is because, in the yin-yang between assessing efficacy and assessing effectiveness, the focus on assessing efficacy naturally undermines the ability to assess whether the drug works in real-world conditions.
As another example of potential assembly bias, let’s say you are studying an antihypertensive drug at a Veterans Administration (VA) hospital, where most veterans are men. But you are treating women in your practice and wonder whether the drug, which works in a predominately male population, will work in your female patients. So, there could be assembly bias in applying the results of a VA study to a non-VA predominantly female population.
Having now described the design of clinical trials and the major sources of bias, let’s apply this thinking to the earliest clinical trial. James Lind, a British Naval officer, was credited with conducting the first clinical trial of citrus fruits for scurvy while sailing on the ship Salisbury in 1747.2 The question that Lind addressed was “does citrus fruit treat and prevent scurvy?” In describing this trial, Lind stated “I took 12 patients with scurvy, these patients were as similar as I could have them, had one diet common to all.” As you read this through your new Feinsteinian bias lens, Lind is addressing 2 potential sources of bias, namely, susceptibility bias and performance bias. In trying to make the “cases as similar as I could have them,” he is trying to avoid susceptibility bias and in “providing one diet common to all,” he is trying to avoid performance bias.
In terms of the intervention in this trial, these 12 patients were allocated in pairs to several interventions: a quart of cider a day, 25 drops of elixir of vitriol 3 times a day on an empty stomach, 2 spoonsful of vinegar 3 times a day on an empty stomach, ½ pint a day of sea water, 2 oranges and 1 lemon given every day, and a “bigness of nutmeg” 3 times per day. In describing the outcome of the trial, Lind states “the consequence was that the most sudden and visible good effects were perceived from the use of oranges and lemons; one of those who had taken them, being at the end of 6 days fit for duty. The spots were not indeed at that time quite off his body, nor his gums sound, but without any other medicine then a gargarism of elixir vitriol, he became quite healthy before we came into Plymouth which was on the 16th of June. The other was the best recovered of any in his condition; and being now deemed pretty well, was appointed nurse to the rest of the sick.”
In analyzing this trial, we could characterize it as a parallel controlled trial. Whether the allocation was done by randomization is not clear, but it was certainly an observational cohort study in that there were concurrent controls who were treated as similarly as possible except for the principal maneuver, which was the administration of citrus fruit. Already mentioned was the attention to averting susceptibility and performance bias. There was no evidence of compliance bias as the interventions were enforced, nor was there evidence of transfer bias because all subjects who were enrolled in the study completed the study because they were a captive group on a sailing ship. Finally, the likelihood of assembly bias seems small, as these sailors seemed to be representative of victims of scurvy in general, namely in being otherwise deprived of access to citrus fruits.
In terms of the statistical results of this study, subsequent analysis of the research showed that the impact of lemons and oranges was dramatic and showed a trend (P = .09) towards statistical significance. Notwithstanding the lack of a P < .05, Dr. Feinstein would likely say that this study satisfied the “intra-ocular test” in that the efficacy of the citrus fruit was so dramatic that it “hit you between the eyes.” He often argued that the widespread practice of prescribing penicillin for pneumococcal pneumonia was not based on the results of a convincing randomized controlled trial because the efficacy of penicillin in that setting was so dramatic that a randomized trial was not necessary (and potentially even unethical if the condition of “intra-ocular” efficacy was satisfied).
The final question to address in this lecture is whether randomized controlled trials, for all their rigor, always produce more reliable results than observational studies. This issue has been addressed by several authors.10–12 Sacks et al10 contended in 1983 that observational studies systematically overestimate the magnitude of association between exposure and outcome and therefore argued that randomized trials were more reliable than observational studies. Subsequent analyses tended to challenge this view.11,12 Specifically, Benson and Hartz11 compared the results of 136 reports regarding 19 different therapies that were studied between 1985 and 1998. In only 2 of the 19 analyses did the treatment effects in the observational studies fall outside the 95% confidence interval for the randomized controlled trial results. In this way, these authors argued that observational studies generally are concordant with the results of randomized trials. They stated that “our finding that observational studies and randomized controlled trials usually produce similar results differs from the conclusions of previous authors. The fundamental criticism of observational studies is that unrecognized confounding factors may distort the results. According to the conventional wisdom, this distortion is sufficiently common and unpredictable that observational studies are not liable and should not be funded. Our results suggested observational studies usually do provide valid information.”11
An additional analysis of this issue was performed by Concato et al,12 who identified 99 articles regarding 5 clinical topics. Again, the results from randomized trials were compared with those of observational cohort or case-controlled studies regarding the same intervention. The authors reported that “contrary to prevailing belief, the average results from well-designed observational studies did not systematically overestimate the magnitude of the associations between exposure and outcome as compared with the results of randomized, controlled trials on the same topic. Rather, the summary results of randomized, controlled trials and observational studies were remarkably similar.”12
On the basis of these studies, it appears that randomized control trials continue to serve as the gold standard in clinical research, but we must also recognize that circumstances often preclude the conduct of a randomized trial. As an example, consider a randomized trial of whether cigarette smoking is harmful, which, given the strong suspicion of harm, would be unethical in that patients cannot be randomized to smoke. Similarly, from the example before, a randomized trial of penicillin for pneumococcal pneumonia would be unethical because denying patients in the placebo group access to penicillin would exclude them from access to a drug that has “intra-ocular” efficacy. In circumstances like these, well-performed observational studies that are attentive to sources of bias can likely produce comparably reliable results to randomized trials.
In the end, of course, the interpretation of the study results requires the reader’s careful attention to potential sources of bias that can compromise study validity. The hope is that with Dr. Feinstein’s framework, you can be better equipped to think critically about study results that you review and to keenly ascertain whether there is any threat to internal or to external validity. Similarly, as you go on to design clinical trials yourselves, you can pay attention to these potential sources of bias that, if present, can compromise the reliability of the study conclusions internally or their applicability to patients outside of the study.
- Feinstein AR. Clinical Epidemiology: The Architecture of Clinical Research. Philadelphia, PA: WB Saunders; 1985.
- Thomas DP. Experiment versus authority: James Lind and Benjamin Rush. N Engl J Med 1969; 281:932–934.
- Downs JB, Klein EF Jr, Desautels D, Modell JH, Kirby RR. Intermittent mandatory ventilation: a new approach to weaning patients from mechanical ventilators. Chest 1973; 64:331–335.
- Brochard L, Rauss A, Benito S, et al. Comparison of three methods of gradual withdrawal from ventilatory support during weaning from mechanical ventilation. Am J Respir Crit Care Med 1994; 150:896–903.
- Chapman KR, Burdon JGW, Piitulainen E, et al; on behalf of the RAPID Trial Study Group. Intravenous augmentation treatment and lung density in severe 1 antitrypsin deficiency (RAPID): a randomised, double-blind, placebo-controlled trial. Lancet 2015; 386:360–368.
- Stoller JK, Wiedemann HP, Loke J, Snyder P, Virgulto J, Matthay RA. Terbutaline and diaphragm function in chronic obstructive pulmonary disease: a double-blind randomized clinical trial. Br J Dis Chest 1988; 82:242–250.
- Sehgal S, Velcheti V, Mukhopadhyay S, Stoller JK. Focal lung infiltrate complicating PD-1 inhibitor use: a new pattern of drug-associated lung toxicity? Respir Med Case Rep 2016; 19:118–120.
- Stoller JK, Moodie D, Schiavone WA, et al. Reduction of intrapulmonary shunt and resolution of digital clubbing associated with primary biliary cirrhosis after liver transplantation. Hepatology 1990; 11:54–58.
- Albert RK, Au DH, Blackford AL, et al; for the Long-Term Oxygen Treatment Trial Group. A randomized trial of long-term oxygen for COPD with moderate desaturation. N Engl J Med 2016; 375:1617–1627.
- Sacks HS, Chalmers TC, Smith H Jr. Sensitivity and specificity of clinical trials: randomized v historical controls. Arch Intern Med 1983; 143:753–755.
- Benson K, Hartz AJ. A comparison of observational studies and randomized, controlled trials. N Engl J Med 2000; 342:1878–1886.
- Concato J, Shah N, Horwitz RI. Randomized, controlled trials, observational studies, and the hierarchy of research designs. N Engl J Med 2000; 342:1887–1892.
- Feinstein AR. Clinical Epidemiology: The Architecture of Clinical Research. Philadelphia, PA: WB Saunders; 1985.
- Thomas DP. Experiment versus authority: James Lind and Benjamin Rush. N Engl J Med 1969; 281:932–934.
- Downs JB, Klein EF Jr, Desautels D, Modell JH, Kirby RR. Intermittent mandatory ventilation: a new approach to weaning patients from mechanical ventilators. Chest 1973; 64:331–335.
- Brochard L, Rauss A, Benito S, et al. Comparison of three methods of gradual withdrawal from ventilatory support during weaning from mechanical ventilation. Am J Respir Crit Care Med 1994; 150:896–903.
- Chapman KR, Burdon JGW, Piitulainen E, et al; on behalf of the RAPID Trial Study Group. Intravenous augmentation treatment and lung density in severe 1 antitrypsin deficiency (RAPID): a randomised, double-blind, placebo-controlled trial. Lancet 2015; 386:360–368.
- Stoller JK, Wiedemann HP, Loke J, Snyder P, Virgulto J, Matthay RA. Terbutaline and diaphragm function in chronic obstructive pulmonary disease: a double-blind randomized clinical trial. Br J Dis Chest 1988; 82:242–250.
- Sehgal S, Velcheti V, Mukhopadhyay S, Stoller JK. Focal lung infiltrate complicating PD-1 inhibitor use: a new pattern of drug-associated lung toxicity? Respir Med Case Rep 2016; 19:118–120.
- Stoller JK, Moodie D, Schiavone WA, et al. Reduction of intrapulmonary shunt and resolution of digital clubbing associated with primary biliary cirrhosis after liver transplantation. Hepatology 1990; 11:54–58.
- Albert RK, Au DH, Blackford AL, et al; for the Long-Term Oxygen Treatment Trial Group. A randomized trial of long-term oxygen for COPD with moderate desaturation. N Engl J Med 2016; 375:1617–1627.
- Sacks HS, Chalmers TC, Smith H Jr. Sensitivity and specificity of clinical trials: randomized v historical controls. Arch Intern Med 1983; 143:753–755.
- Benson K, Hartz AJ. A comparison of observational studies and randomized, controlled trials. N Engl J Med 2000; 342:1878–1886.
- Concato J, Shah N, Horwitz RI. Randomized, controlled trials, observational studies, and the hierarchy of research designs. N Engl J Med 2000; 342:1887–1892.

Basics of study design: Practical considerations
INTRODUCTION
Basic research skills are not acquired from medical school but from a mentor.1,2 A mentor with experience in study design and technical writing can make a real difference in your career. Most good mentors have more ideas for studies than they have time for research, so they are willing to share and guide your course. Your daily clinical experience provides a wealth of ideas in the form of “why do we do it this way” or “what is the evidence for” or “how can we improve outcomes or cut cost?” Of course, just about every study you read in a medical journal has suggestions for further research in the discussion section. Finally, keep in mind that the creation of study ideas and in particular, hypotheses, is a mysterious process, as this quote indicates: “It is not possible, deliberately, to create ideas or to control their creation. What we can do deliberately is to prepare our minds.” 3 Remember that chance favors the prepared mind.
DEVELOPING THE STUDY IDEA
Often, the most difficult task for someone new to research is developing a practical study idea. This section will explain a detailed process for creating a formal research protocol. We will focus on two common sticking points: (1) finding a good idea, and (2) developing a good idea into a problem statement.
Novice researchers with little experience, no mentors, and short time frames are encouraged not to take on a clinical human study as the principle investigator. Instead, device evaluations are a low-cost, time-efficient alternative. Human studies in the form of a survey are also possible and are often exempt from full Institutional Review Board (IRB) review. Many human-like conditions can be simulated, as was done, for example, in the study of patient-ventilator synchrony.4,5 And if you have the aptitude, whole studies can be based on mathematical models and predictions, particularly with the vast array of computer tools now available.6,7 And don’t forget studies based on surveys.8
A structured approach

A formal research protocol is required for any human research. However, it is also recommended for all but the simplest investigations. Most of the new researchers I have mentored take a rather lax approach to developing the protocol, and most IRBs are more interested in protecting human rights than validating the study design. As a result, much time is wasted and sometimes an entire study has to be abandoned due to poor planning. Figure 1 illustrates a structured approach that helps to ensure success. It shows a 3-step, iterative process.
The first step is a process of expanding the scope of the project, primarily through literature review. Along the way you learn (or invent) appropriate terminology and become familiar with the current state of the research art on a broad topic. For example, let’s suppose you were interested in the factors that affect the duration of mechanical ventilation. The literature review might include topics such as weaning and patient-ventilator synchrony as well as ventilator-associated pneumonia. During this process, you might discover that the topic of synchrony is currently generating a lot of interest in the literature and generating a lot of questions or confusion. You then focus on expanding your knowledge in this area.
In the second step, you might develop a theoretical framework for understanding patient-ventilator synchrony that could include a mathematical model and, perhaps, an idea to include simulation to study the problem.
In the third step, you need to narrow the scope of the study to a manageable level that includes identifying measurable outcome variables, creating testable hypotheses, considering experimental designs, and evaluating the overall feasibility of the study. At this point, you may discover that you cannot measure the specific outcome variables indicated by your theoretical framework. In that case, you need to create a new framework for supporting your research. Alternatively, you may find that it is not possible to conduct the study you envision given your resources. In that case, it is back to step 1.
Eventually, this process will result in a well-planned research protocol that is ready for review. Keep in mind that many times a protocol needs to be refined after some initial experiments are conducted. For human studies, any changes to the protocol must be approved by the IRB.
The problem statement rubric
The most common problem I have seen novices struggle with is creating a meaningful problem statement and hypothesis. This is crucial because the problem statement sets the stage for the methods, the methods yield the results, and the results are analyzed in light of the original problem statement and hypotheses. To get past any writer’s block, I recommend that you start by just describing what you see happening and why you think it is important. For example, you might say, “Patients with acute lung injury often seem to be fighting the ventilator.” This is important because patient-ventilator asynchrony may lead to increased sedation levels and prolonged intensive care unit stays. Now you can more easily envision a specific purpose and testable hypothesis. For example, you could state that the purpose of this study is to determine the baseline rates of different kinds of patient-ventilator synchrony problems. The hypothesis is that the rate of dyssynchrony is correlated with duration of mechanical ventilation.
Here is an actual example of how a problem statement evolved from a vague notion to a testable hypothesis.
Original: The purpose of this study is to determine whether measures of ineffective cough in patients with stroke recently liberated from mechanical ventilation correlate with risk of extubation failure and reintubation.
Final: The purpose of this study is to test the hypothesis that use of CoughAssist device in the immediate post-extubation period by stroke patients reduces the rate of extubation failure and pneumonia.
The original statement is a run-on sentence that is vague and hard to follow. Once the actual treatment and outcome measures are in focus, then a clear hypothesis statement can be made. Notice that the hypothesis should be clear enough that the reader can anticipate the actual experimental measures and procedures to be described in the methods section of the protocol.
Here is another example:
Original: The purpose of this study is to evaluate a device that allows continuous electronic cuff pressure control.
Final: The purpose of this study is to test the hypothesis that the Pressure Eyes electronic cuff monitor will maintain constant endotracheal tube cuff pressures better than manual cuff inflation during mechanical ventilation.
The problem with the original statement is that “to evaluate” is vague. The final statement makes the outcome variable explicit and suggests what the experimental procedure will be.
This is a final example:
Original: Following cardiac/respiratory arrest, many patients are profoundly acidotic. Ventilator settings based on initial arterial blood gases may result in inappropriate hyperventilation when follow-up is delayed. The purpose of this study is to establish the frequency of this occurrence at a large academic institution and the feasibility of a quality improvement project.
Final: The primary purpose of this study is to evaluate the frequency of hyperventilation occurring post-arrest during the first 24 hours. A secondary purpose is to determine if this hyperventilation is associated with an initial diagnosis of acidosis.
Note that the original statement follows the rubric of telling us what is observed and why it is important. However, the actual problem statement derived from the observation is vague: what is “this occurrence” and is the study really to establish any kind of feasibility? The purpose is simply to evaluate the frequency of hyperventilation and determine if the condition is associated with acidosis.
EXAMPLES OF RESEARCH PROJECTS BY FELLOWS
The following are examples of well-written statements of study purpose from actual studies conducted by our fellows.
Device evaluation
Defining “Flow Starvation” in volume control mechanical ventilation.
- The purpose of this study is to evaluate the relationship between the patient and ventilator inspiratory work of breathing to define the term “Flow Starvation.”
Auto-positive end expiratory pressure (auto-PEEP) during airway pressure release ventilation varies with the ventilator model.
- The purpose of this study was to compare auto-PEEP levels, peak expiratory flows, and flow decay profiles among 4 common intensive care ventilators.
Patient study
Diaphragmatic electrical activity and extubation outcomes in newborn infants: an observational study.
- The purpose of this study is to describe the electrical activity of the diaphragm before, during, and after extubation in a mixed-age cohort of preterm infants.
Comparison of predicted and measured carbon dioxide production for monitoring dead space fraction during mechanical ventilation.
- The purpose of this pilot study was to compare dead space with tidal volume ratios calculated from estimated and measured values for carbon dioxide production.
Practice evaluation
Incidence of asynchronies during invasive mechanical ventilation in a medical intensive care unit.
- The purpose of this study is to conduct a pilot investigation to determine the baseline incidence of various forms of patient-ventilator dyssynchrony during invasive mechanical ventilation.
Simulation training results in improved knowledge about intubation policies and procedures.
- The purpose of this study was to develop and test a simulation-based rapid-sequence intubation curriculum for fellows in pulmonary and critical care training.
HOW TO SEARCH THE LITERATURE
After creating a problem statement, the next step in planning research is to search the literature. The 10th issue of Respiratory Care journal in 2009 was devoted to research. Here are the articles in that issue related to the literature search:
- How to find the best evidence (search internet)9
- How to read a scientific research paper10
- How to read a case report (or teaching case of the month)11
- How to read a review paper.12
I recommend that you read these papers.
Literature search resources
My best advice is to befriend your local librarian.13 These people seldom get the recognition they deserve as experts at finding information and even as co-investigators.14 In addition to personal help, some libraries offer training sessions on various useful skills.
PubMed
The Internet resource I use most often is PubMed (www.ncbi.nlm.nih.gov/pubmed). It offers free access to MEDLINE, which is the National Library of Medicine’s database of citations and abstracts in the fields of medicine, nursing, dentistry, veterinary medicine, health care systems, and preclinical sciences. There are links to full-text articles and other resources. The website provides a clinical queries search filters page as well as a special queries page. Using a feature called “My NCBI,” you can have automatic e-mailing of search updates and save records and filters for search results. Access the PubMed Quick Start Guide for frequently asked questions and tutorials.
SearchMedica.com
The SearchMedica website (www.searchmedica.co.uk) is free and intended for medical professionals. It provides answers for clinical questions. Searches return articles, abstracts, and recommended medical websites.
Synthetic databases
There is a class of websites called synthetic databases, which are essentially prefiltered records for particular topics. However, these sites are usually subscription-based, and the cost is relatively high. You should check with your medical library to get access. Their advantage is that often they provide the best evidence without extensive searches of standard, bibliographic databases. Examples include the Cochrane Database of Systematic Reviews (www.cochrane.org/evidence), the National Guideline Clearinghouse (www.guideline.gov), and UpToDate (www.uptodate.com). UpToDate claims to be the largest clinical community in the world dedicated to synthesized knowledge for clinicians and patients. It features the work of more than 6,000 expert clinician authors/reviewers on more than 10,000 topics in 23 medical specialties. The site offers graded recommendations based on the best medical evidence.
Portals
Portals are web pages that act as a starting point for using the web or web-based services. One popular example is ClinicalKey (www.clinicalkey.com/info), formerly called MD Consult, which offers books, journals, patient education materials, and images. Another popular portal is Ovid (ovid.com), offering books, journals, evidence-based medicine databases, and CINAHL (Cumulative Index to Nursing and Allied Health Literature).
Electronic journals
Many medical journals now have online databases of current and archived issues. Such sites may require membership to access the databases, so again, check with your medical library. Popular examples in pulmonary and critical care medicine include the following:
- American Journal of Respiratory and Critical Care Medicine (www.atsjournals.org/journal/ajrccm)
- The New England Journal of Medicine (www.nejm.org)
- Chest (journal.publications.chestnet.org)
- Respiratory Care (rc.rcjournal.com)
Electronic books
Amazon.com is a great database search engine for books on specific topics. It even finds out-of-print books. And you don’t have to buy the books, because now you can rent them. Sometimes, I find what I wanted by using the “Look Inside” feature for some books. Note that you can look for books at PubMed. Just change the search box from PubMed to Books on the PubMed home page. Of course, Google also has a book search feature. A great (subscription) resource for medical and technical books is Safari (https://www.safaribooksonline.com). Once again, your library may have a subscription.
General Internet resources
You probably already know about Google Scholar (scholar.google.com) and Wikipedia.com. Because of its open source nature, you should use Wikipedia with caution. However, I have found it to be a very good first step in finding technical information, particularly about mathematics, physics, and statistics.
Using reference management software
One of the most important things you can do to make your research life easier is to use some sort of reference management software. As described in Wikipedia, “Reference management software, citation management software or personal bibliographic management software is software for scholars and authors to use for recording and using bibliographic citations (references). Once a citation has been recorded, it can be used time and again in generating bibliographies, such as lists of references in scholarly books, articles, and essays.” I was late in adopting this technology, but now I am a firm believer. Most Internet reference sources offer the ability to download citations to your reference management software. Downloading automatically places the citation into a searchable database on your computer with backup to the Internet. In addition, you can get the reference manager software to find a PDF version of the manuscript and store it with the citation on your computer (and/or in the Cloud) automatically.
But the most powerful feature of such software is its ability to add or subtract and rearrange the order of references in your manuscripts as you are writing, using seamless integration with Microsoft Word. The references can be automatically formatted using just about any journal’s style. This is a great time saver for resubmitting manuscripts to different journals. If you are still numbering references by hand (God forbid) or even using the Insert Endnote feature in Word (deficient when using multiple occurrences of the same reference), your life will be much easier if you take the time to start using reference management software.
The most popular commercial software is probably EndNote (endnote.com). A really good free software system with about the same functionality as Zotero (zotero.com). Search for “comparison of reference management software” in Wikipedia. You can find tutorials on software packages in YouTube.
STUDY DESIGN

When designing the experiment, note that there are many different approaches, each with their advantages and disadvantages. A full treatment of this topic is beyond the scope of this article. Suffice it to say that pre-experimental designs (Figure 2) are considered to generate weak evidence. But they are quick and easy and might be appropriate for pilot studies.

Quasi-experimental designs (Figure 3) generate a higher level of evidence. Such a design might be appropriate when you are stuck with collecting a convenience sample, rather than being able to use a full randomized assignment of study subjects.

The fully randomized design (Figure 4) generates the highest level of evidence. This is because if the sample size is large enough, the unknown and uncontrollable sources of bias are evenly distributed between the study groups.
BASIC MEASUREMENT METHODS
If your research involves physical measurements, you need to be familiar with the devices considered to be the gold standards. In cardiopulmonary research, most measurements involve pressure volume, flow, and gas concentration. You need to know which devices are appropriate for static vs dynamic measurements of these variables. In addition, you need to understand issues related to systematic and random measurement errors and how these errors are managed through calibration and calibration verification. I recommend these two textbooks:
Principles and Practice of Intensive Care Monitoring 1st Edition by Martin J. Tobin MD.
- This book is out of print, but if you can find a used copy or one in a library, it describes just about every kind of physiologic measurement used in clinical medicine.
Medical Instrumentation: Application and Design 4th Edition by John G. Webster.
- This book is readily available and reasonably priced. It is a more technical book describing medical instrumentation and measurement principles. It is a standard textbook for biometrical engineers.
STATISTICS FOR THE UNINTERESTED
I know what you are thinking: I hate statistics. Look at the book Essential Biostatistics: A Nonmathematical Approach.15 It is a short, inexpensive paperback book that is easy to read. The author does a great job of explaining why we use statistics rather than getting bogged down explaining how we calculate them. After all, novice researchers usually seek the help of a professional statistician to do the heavy lifting.
My book, Handbook for Health Care Research,16 covers most of the statistical procedures you will encounter in medical research and gives examples of how to use a popular tactical software package called SigmaPlot. By the way, I strongly suggest that you consult a statistician early in your study design phase to avoid the disappointment of finding out later that your results are uninterpretable. For an in-depth treatment of the subject, I recommend How to Report Statistics in Medicine.17
Statistical bare essentials

To do research or even just to understand published research reports, you must have at least a minimal skill set. The necessary skills include understanding some basic terminology, if only to be able to communicate with a statistician consultant. Important terms include levels of measurement (nominal, ordinal, continuous), accuracy, precision, measures of central tendency (mean, median, mode), measures of variability (variance, standard deviation, coefficient of variation), and percentile. The first step in analyzing your results is usually to represent it graphically. That means you should be able to use a spreadsheet to make simple graphs (Figure 5).

You should also know the basics of inferential statistics (ie, hypothesis testing). For example, you need to know the difference between parametric and non-parametric tests. You should be able to explain correlation and regression and know when to use Chi-squared vs a Fisher exact test. You should know that when comparing two mean values, you typically use the Student’s t test (and know when to use paired vs unpaired versions of the test). When comparing more than 2 mean values, you use analysis of variance methods (ANOVA). You can teach yourself these concepts from a book,16 but even an introductory college level course on statistics will be immensely helpful. Most statistics textbooks provide some sort of map to guide your selection of the appropriate statistical test (Figure 6), and there are good articles in medical journals.
You can learn a lot simply by reading the Methods section of research articles. Authors will often describe the statistical tests used and why they were used. But be aware that a certain percentage of papers get published with the wrong statistics.18
One of the underlying assumptions of most parametric statistical methods is that the data may be adequately described by a normal or Gaussian distribution. This assumption needs to be verified before selecting a statistical test. The common test for data normality is the Kolmogorov-Smirnov test. The following text from a methods section describes 2 very common procedures—the Student’s t test for comparing 2 mean values and the one-way ANOVA for comparing more than 2 mean values.19
“Normal distribution of data was verified using the Kolmogorov-Smirnov test. Body weights between groups were compared using one-way ANOVA for repeated measures to investigate temporal differences. At each time point, all data were analyzed using one-way ANOVA to compare PCV and VCV groups. Tukey’s post hoc analyses were performed when significant time effects were detected within groups, and Student’s t test was used to investigate differences between groups. Data were analyzed using commercial software and values were presented as mean ± SD. A P value < .05 was considered statistically significant.”
Estimating sample size and power analysis
One very important consideration in any study is the required number of study subjects for meaningful statistical conclusions. In other words, how big should the sample size be? Sample size is important because it affects the feasibility of the study and the reliability of the conclusions in terms of statistical power. The necessary sample size depends on 2 basic factors. One factor is the variability of the data (often expressed as the standard deviation). The other factor is the effect size, meaning, for example, how big of a difference between mean values you want to detect. In general, the bigger the variability and the smaller the difference, the bigger the sample size required.
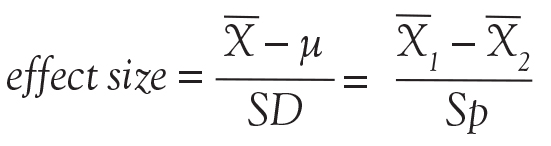
As the above equation shows, the effect size is expressed, in general, as a mean difference divided by a standard deviation. In the first case, the numerator represents the difference between the sample mean and the assumed population mean. In the denominator, SD is the standard deviation of the sample (used to estimate the standard deviation of the population). In the second case, the numerator represents the difference between the mean values of 2 samples and the denominator is the pooled standard deviation of the 2 samples.
In order to understand the issues involved with selecting sample size, we need to first understand the types of errors that can be made in any type of decision. Suppose our research goal is to make a decision about whether a new treatment results in a clinical difference (improvement). The results of our statistical test are dichotomous—we decide either yes there is a significant difference or no there isn’t. The truth, which we may never know, is that in reality, the difference exists or it doesn’t.

As Figure 7 shows, the result of our decision making is that there are 2 ways to be right and 2 ways to be wrong. If we decide there is a difference (eg, our statistical tests yields P ≤ .05) but in realty there is not a difference, then we make what is called a type I error. On the other hand, if we conclude that there is not a difference (ie, our statistical test yields P > .05) but in reality there is a difference that we did not detect, then we have made a type II error.

The associated math is shown in Figure 8. The probability of making a type I error is called alpha. By convention in medicine, we set our rejection criterion to alpha = 0.05. In other words, we would reject the null hypothesis (that there is no difference) anytime our statistical test yields a P value less than alpha. The probability of making a type II error is called beta. For historical reasons, the probability of not making a type II error is called the statistical power of the test and is equal to 1 minus beta. Power is affected by sample size: the larger the sample the larger the power. Most researchers, by convention, keep the sample size large enough to keep power above 0.80.

Figure 9 is a nomogram that brings all these ideas together. The red line shows that for your study, given the desired effect size (0.8), if you collected samples from the 30 patients you planned on then the power would be unacceptable at 0.60, indicating a high probability of a false negative decision if the P value comes out greater than .50. The solution is to increase the sample size to about 50 (or more), as indicated by the blue line. From this nomogram we can generalize to say that when you want to detect a small effect with data that have high variability, you need a large sample size to provide acceptable power.
The text below is an example of a power analysis presented in the methods section of a published study.20 Note that the authors give their reasoning for the sample size they selected. This kind of explanation may inform your study design. But what if you don’t know the variability of the data you want to collect? In that case, you need to collect some pilot data and calculate from that an appropriate sample size for a subsequent study.
A prospective power calculation indicated that a sample size of 25 per group was required to achieve 80% power based on an effect size of probability of 0.24 that an observation in the PRVCa group is less than an observation in the ASV group using the Mann-Whitney tests, an alpha of 0.05 (two-tailed) and a 20% dropout.
JUDGING FEASIBILITY
Once you have a draft of your study design, including the estimated sample size, it is time to judge the overall feasibility of the study before committing to it.

Every study has associated costs. Those costs and the sources of funding must be identified. Don’t forget costs for consultants, particularly if you need statistical consultation.
Finally, consider your level of experience. If you are contemplating your first study, a human clinical trial might not be the best choice, given the complexity of such a project. Studies such as a meta-analysis or mathematical simulation require special training beyond basic research procedures, and should be avoided.
- Tobin MJ. Mentoring: seven roles and some specifics. Am J Respir Crit Care Med 2004; 170:114–117.
- Chatburn RL. Advancing beyond the average: the importance of mentoring in professional achievement. Respir Care 2004; 49:304–308.
- Beveridge WIB. The Art of Scientific Investigation. New York, NY: WW Norton & Company; 1950.
- Chatburn RL, Mireles-Cabodevila E, Sasidhar M. Tidal volume measurement error in pressure control modes of mechanical ventilation: a model study. Comput Biol Med 2016; 75:235–242.
- Mireles-Cabodevila E, Chatburn RL. Work of breathing in adaptive pressure control continuous mandatory ventilation. Respir Care 2009; 54:1467–1472.
- Chatburn RL, Ford RM. Procedure to normalize data for benchmarking. Respir Care 2006; 51:145–157.
- Bou-Khalil P, Zeineldine S, Chatburn R, et al. Prediction of inspired oxygen fraction for targeted arterial oxygen tension following open heart surgery in non-smoking and smoking patients. J Clin Monit Comput 2016. https://doi.org/10.1007/s10877-016-9941-6.
- Mireles-Cabodevila E, Diaz-Guzman E, Arroliga AC, Chatburn RL. Human versus computer controlled selection of ventilator settings: an evaluation of adaptive support ventilation and mid-frequency ventilation. Crit Care Res Pract 2012; 2012:204314.
- Chatburn RL. How to find the best evidence. Respir Care 2009; 54:1360–1365.
- Durbin CG Jr. How to read a scientific research paper. Respir Care 2009; 54:1366–1371.
- Pierson DJ. How to read a case report (or teaching case of the month). Respir Care 2009; 54:1372–1378.
- Callcut RA, Branson RD. How to read a review paper. Respir Care 2009; 54:1379–1385.
- Eresuma E, Lake E. How do I find the evidence? Find your librarian—stat! Orthop Nurs 2016; 35:421–423.
- Janke R, Rush KL. The academic librarian as co-investigator on an interprofessional primary research team: a case study. Health Info Libr J 2014; 31:116–122.
- Motulsky H. Essential Biostatistics: A Nonmathematical Approach. New York, NY: Oxford University Press; 2016.
- Chatburn RL. Handbook for Health Care Research. 2nd ed. Sudbury, MA: Jones and Bartlett Publishers; 2011.
- Lang TA, Secic M. How to Report Statistics in Medicine. 2nd ed. Philadelphia, PA: American College of Physicians; 2006.
- Prescott RJ, Civil I. Lies, damn lies and statistics: errors and omission in papers submitted to INJURY 2010–2012. Injury 2013; 44:6–11.
- Fantoni DT, Ida KK, Lopes TF, Otsuki DA, Auler JO Jr, Ambrosio AM. A comparison of the cardiopulmonary effects of pressure controlled ventilation and volume controlled ventilation in healthy anesthetized dogs. J Vet Emerg Crit Care (San Antonio) 2016; 26:524–530.
- Gruber PC, Gomersall CD, Leung P, et al. Randomized controlled trial comparing adaptive-support ventilation with pressure-regulated volume-controlled ventilation with automode in weaning patients after cardiac surgery. Anesthesiology 2008; 109:81–87.
INTRODUCTION
Basic research skills are not acquired from medical school but from a mentor.1,2 A mentor with experience in study design and technical writing can make a real difference in your career. Most good mentors have more ideas for studies than they have time for research, so they are willing to share and guide your course. Your daily clinical experience provides a wealth of ideas in the form of “why do we do it this way” or “what is the evidence for” or “how can we improve outcomes or cut cost?” Of course, just about every study you read in a medical journal has suggestions for further research in the discussion section. Finally, keep in mind that the creation of study ideas and in particular, hypotheses, is a mysterious process, as this quote indicates: “It is not possible, deliberately, to create ideas or to control their creation. What we can do deliberately is to prepare our minds.” 3 Remember that chance favors the prepared mind.
DEVELOPING THE STUDY IDEA
Often, the most difficult task for someone new to research is developing a practical study idea. This section will explain a detailed process for creating a formal research protocol. We will focus on two common sticking points: (1) finding a good idea, and (2) developing a good idea into a problem statement.
Novice researchers with little experience, no mentors, and short time frames are encouraged not to take on a clinical human study as the principle investigator. Instead, device evaluations are a low-cost, time-efficient alternative. Human studies in the form of a survey are also possible and are often exempt from full Institutional Review Board (IRB) review. Many human-like conditions can be simulated, as was done, for example, in the study of patient-ventilator synchrony.4,5 And if you have the aptitude, whole studies can be based on mathematical models and predictions, particularly with the vast array of computer tools now available.6,7 And don’t forget studies based on surveys.8
A structured approach
A formal research protocol is required for any human research. However, it is also recommended for all but the simplest investigations. Most of the new researchers I have mentored take a rather lax approach to developing the protocol, and most IRBs are more interested in protecting human rights than validating the study design. As a result, much time is wasted and sometimes an entire study has to be abandoned due to poor planning. Figure 1 illustrates a structured approach that helps to ensure success. It shows a 3-step, iterative process.
The first step is a process of expanding the scope of the project, primarily through literature review. Along the way you learn (or invent) appropriate terminology and become familiar with the current state of the research art on a broad topic. For example, let’s suppose you were interested in the factors that affect the duration of mechanical ventilation. The literature review might include topics such as weaning and patient-ventilator synchrony as well as ventilator-associated pneumonia. During this process, you might discover that the topic of synchrony is currently generating a lot of interest in the literature and generating a lot of questions or confusion. You then focus on expanding your knowledge in this area.
In the second step, you might develop a theoretical framework for understanding patient-ventilator synchrony that could include a mathematical model and, perhaps, an idea to include simulation to study the problem.
In the third step, you need to narrow the scope of the study to a manageable level that includes identifying measurable outcome variables, creating testable hypotheses, considering experimental designs, and evaluating the overall feasibility of the study. At this point, you may discover that you cannot measure the specific outcome variables indicated by your theoretical framework. In that case, you need to create a new framework for supporting your research. Alternatively, you may find that it is not possible to conduct the study you envision given your resources. In that case, it is back to step 1.
Eventually, this process will result in a well-planned research protocol that is ready for review. Keep in mind that many times a protocol needs to be refined after some initial experiments are conducted. For human studies, any changes to the protocol must be approved by the IRB.
The problem statement rubric
The most common problem I have seen novices struggle with is creating a meaningful problem statement and hypothesis. This is crucial because the problem statement sets the stage for the methods, the methods yield the results, and the results are analyzed in light of the original problem statement and hypotheses. To get past any writer’s block, I recommend that you start by just describing what you see happening and why you think it is important. For example, you might say, “Patients with acute lung injury often seem to be fighting the ventilator.” This is important because patient-ventilator asynchrony may lead to increased sedation levels and prolonged intensive care unit stays. Now you can more easily envision a specific purpose and testable hypothesis. For example, you could state that the purpose of this study is to determine the baseline rates of different kinds of patient-ventilator synchrony problems. The hypothesis is that the rate of dyssynchrony is correlated with duration of mechanical ventilation.
Here is an actual example of how a problem statement evolved from a vague notion to a testable hypothesis.
Original: The purpose of this study is to determine whether measures of ineffective cough in patients with stroke recently liberated from mechanical ventilation correlate with risk of extubation failure and reintubation.
Final: The purpose of this study is to test the hypothesis that use of CoughAssist device in the immediate post-extubation period by stroke patients reduces the rate of extubation failure and pneumonia.
The original statement is a run-on sentence that is vague and hard to follow. Once the actual treatment and outcome measures are in focus, then a clear hypothesis statement can be made. Notice that the hypothesis should be clear enough that the reader can anticipate the actual experimental measures and procedures to be described in the methods section of the protocol.
Here is another example:
Original: The purpose of this study is to evaluate a device that allows continuous electronic cuff pressure control.
Final: The purpose of this study is to test the hypothesis that the Pressure Eyes electronic cuff monitor will maintain constant endotracheal tube cuff pressures better than manual cuff inflation during mechanical ventilation.
The problem with the original statement is that “to evaluate” is vague. The final statement makes the outcome variable explicit and suggests what the experimental procedure will be.
This is a final example:
Original: Following cardiac/respiratory arrest, many patients are profoundly acidotic. Ventilator settings based on initial arterial blood gases may result in inappropriate hyperventilation when follow-up is delayed. The purpose of this study is to establish the frequency of this occurrence at a large academic institution and the feasibility of a quality improvement project.
Final: The primary purpose of this study is to evaluate the frequency of hyperventilation occurring post-arrest during the first 24 hours. A secondary purpose is to determine if this hyperventilation is associated with an initial diagnosis of acidosis.
Note that the original statement follows the rubric of telling us what is observed and why it is important. However, the actual problem statement derived from the observation is vague: what is “this occurrence” and is the study really to establish any kind of feasibility? The purpose is simply to evaluate the frequency of hyperventilation and determine if the condition is associated with acidosis.
EXAMPLES OF RESEARCH PROJECTS BY FELLOWS
The following are examples of well-written statements of study purpose from actual studies conducted by our fellows.
Device evaluation
Defining “Flow Starvation” in volume control mechanical ventilation.
- The purpose of this study is to evaluate the relationship between the patient and ventilator inspiratory work of breathing to define the term “Flow Starvation.”
Auto-positive end expiratory pressure (auto-PEEP) during airway pressure release ventilation varies with the ventilator model.
- The purpose of this study was to compare auto-PEEP levels, peak expiratory flows, and flow decay profiles among 4 common intensive care ventilators.
Patient study
Diaphragmatic electrical activity and extubation outcomes in newborn infants: an observational study.
- The purpose of this study is to describe the electrical activity of the diaphragm before, during, and after extubation in a mixed-age cohort of preterm infants.
Comparison of predicted and measured carbon dioxide production for monitoring dead space fraction during mechanical ventilation.
- The purpose of this pilot study was to compare dead space with tidal volume ratios calculated from estimated and measured values for carbon dioxide production.
Practice evaluation
Incidence of asynchronies during invasive mechanical ventilation in a medical intensive care unit.
- The purpose of this study is to conduct a pilot investigation to determine the baseline incidence of various forms of patient-ventilator dyssynchrony during invasive mechanical ventilation.
Simulation training results in improved knowledge about intubation policies and procedures.
- The purpose of this study was to develop and test a simulation-based rapid-sequence intubation curriculum for fellows in pulmonary and critical care training.
HOW TO SEARCH THE LITERATURE
After creating a problem statement, the next step in planning research is to search the literature. The 10th issue of Respiratory Care journal in 2009 was devoted to research. Here are the articles in that issue related to the literature search:
- How to find the best evidence (search internet)9
- How to read a scientific research paper10
- How to read a case report (or teaching case of the month)11
- How to read a review paper.12
I recommend that you read these papers.
Literature search resources
My best advice is to befriend your local librarian.13 These people seldom get the recognition they deserve as experts at finding information and even as co-investigators.14 In addition to personal help, some libraries offer training sessions on various useful skills.
PubMed
The Internet resource I use most often is PubMed (www.ncbi.nlm.nih.gov/pubmed). It offers free access to MEDLINE, which is the National Library of Medicine’s database of citations and abstracts in the fields of medicine, nursing, dentistry, veterinary medicine, health care systems, and preclinical sciences. There are links to full-text articles and other resources. The website provides a clinical queries search filters page as well as a special queries page. Using a feature called “My NCBI,” you can have automatic e-mailing of search updates and save records and filters for search results. Access the PubMed Quick Start Guide for frequently asked questions and tutorials.
SearchMedica.com
The SearchMedica website (www.searchmedica.co.uk) is free and intended for medical professionals. It provides answers for clinical questions. Searches return articles, abstracts, and recommended medical websites.
Synthetic databases
There is a class of websites called synthetic databases, which are essentially prefiltered records for particular topics. However, these sites are usually subscription-based, and the cost is relatively high. You should check with your medical library to get access. Their advantage is that often they provide the best evidence without extensive searches of standard, bibliographic databases. Examples include the Cochrane Database of Systematic Reviews (www.cochrane.org/evidence), the National Guideline Clearinghouse (www.guideline.gov), and UpToDate (www.uptodate.com). UpToDate claims to be the largest clinical community in the world dedicated to synthesized knowledge for clinicians and patients. It features the work of more than 6,000 expert clinician authors/reviewers on more than 10,000 topics in 23 medical specialties. The site offers graded recommendations based on the best medical evidence.
Portals
Portals are web pages that act as a starting point for using the web or web-based services. One popular example is ClinicalKey (www.clinicalkey.com/info), formerly called MD Consult, which offers books, journals, patient education materials, and images. Another popular portal is Ovid (ovid.com), offering books, journals, evidence-based medicine databases, and CINAHL (Cumulative Index to Nursing and Allied Health Literature).
Electronic journals
Many medical journals now have online databases of current and archived issues. Such sites may require membership to access the databases, so again, check with your medical library. Popular examples in pulmonary and critical care medicine include the following:
- American Journal of Respiratory and Critical Care Medicine (www.atsjournals.org/journal/ajrccm)
- The New England Journal of Medicine (www.nejm.org)
- Chest (journal.publications.chestnet.org)
- Respiratory Care (rc.rcjournal.com)
Electronic books
Amazon.com is a great database search engine for books on specific topics. It even finds out-of-print books. And you don’t have to buy the books, because now you can rent them. Sometimes, I find what I wanted by using the “Look Inside” feature for some books. Note that you can look for books at PubMed. Just change the search box from PubMed to Books on the PubMed home page. Of course, Google also has a book search feature. A great (subscription) resource for medical and technical books is Safari (https://www.safaribooksonline.com). Once again, your library may have a subscription.
General Internet resources
You probably already know about Google Scholar (scholar.google.com) and Wikipedia.com. Because of its open source nature, you should use Wikipedia with caution. However, I have found it to be a very good first step in finding technical information, particularly about mathematics, physics, and statistics.
Using reference management software
One of the most important things you can do to make your research life easier is to use some sort of reference management software. As described in Wikipedia, “Reference management software, citation management software or personal bibliographic management software is software for scholars and authors to use for recording and using bibliographic citations (references). Once a citation has been recorded, it can be used time and again in generating bibliographies, such as lists of references in scholarly books, articles, and essays.” I was late in adopting this technology, but now I am a firm believer. Most Internet reference sources offer the ability to download citations to your reference management software. Downloading automatically places the citation into a searchable database on your computer with backup to the Internet. In addition, you can get the reference manager software to find a PDF version of the manuscript and store it with the citation on your computer (and/or in the Cloud) automatically.
But the most powerful feature of such software is its ability to add or subtract and rearrange the order of references in your manuscripts as you are writing, using seamless integration with Microsoft Word. The references can be automatically formatted using just about any journal’s style. This is a great time saver for resubmitting manuscripts to different journals. If you are still numbering references by hand (God forbid) or even using the Insert Endnote feature in Word (deficient when using multiple occurrences of the same reference), your life will be much easier if you take the time to start using reference management software.
The most popular commercial software is probably EndNote (endnote.com). A really good free software system with about the same functionality as Zotero (zotero.com). Search for “comparison of reference management software” in Wikipedia. You can find tutorials on software packages in YouTube.
STUDY DESIGN
When designing the experiment, note that there are many different approaches, each with their advantages and disadvantages. A full treatment of this topic is beyond the scope of this article. Suffice it to say that pre-experimental designs (Figure 2) are considered to generate weak evidence. But they are quick and easy and might be appropriate for pilot studies.
Quasi-experimental designs (Figure 3) generate a higher level of evidence. Such a design might be appropriate when you are stuck with collecting a convenience sample, rather than being able to use a full randomized assignment of study subjects.
The fully randomized design (Figure 4) generates the highest level of evidence. This is because if the sample size is large enough, the unknown and uncontrollable sources of bias are evenly distributed between the study groups.
BASIC MEASUREMENT METHODS
If your research involves physical measurements, you need to be familiar with the devices considered to be the gold standards. In cardiopulmonary research, most measurements involve pressure volume, flow, and gas concentration. You need to know which devices are appropriate for static vs dynamic measurements of these variables. In addition, you need to understand issues related to systematic and random measurement errors and how these errors are managed through calibration and calibration verification. I recommend these two textbooks:
Principles and Practice of Intensive Care Monitoring 1st Edition by Martin J. Tobin MD.
- This book is out of print, but if you can find a used copy or one in a library, it describes just about every kind of physiologic measurement used in clinical medicine.
Medical Instrumentation: Application and Design 4th Edition by John G. Webster.
- This book is readily available and reasonably priced. It is a more technical book describing medical instrumentation and measurement principles. It is a standard textbook for biometrical engineers.
STATISTICS FOR THE UNINTERESTED
I know what you are thinking: I hate statistics. Look at the book Essential Biostatistics: A Nonmathematical Approach.15 It is a short, inexpensive paperback book that is easy to read. The author does a great job of explaining why we use statistics rather than getting bogged down explaining how we calculate them. After all, novice researchers usually seek the help of a professional statistician to do the heavy lifting.
My book, Handbook for Health Care Research,16 covers most of the statistical procedures you will encounter in medical research and gives examples of how to use a popular tactical software package called SigmaPlot. By the way, I strongly suggest that you consult a statistician early in your study design phase to avoid the disappointment of finding out later that your results are uninterpretable. For an in-depth treatment of the subject, I recommend How to Report Statistics in Medicine.17
Statistical bare essentials
To do research or even just to understand published research reports, you must have at least a minimal skill set. The necessary skills include understanding some basic terminology, if only to be able to communicate with a statistician consultant. Important terms include levels of measurement (nominal, ordinal, continuous), accuracy, precision, measures of central tendency (mean, median, mode), measures of variability (variance, standard deviation, coefficient of variation), and percentile. The first step in analyzing your results is usually to represent it graphically. That means you should be able to use a spreadsheet to make simple graphs (Figure 5).
You should also know the basics of inferential statistics (ie, hypothesis testing). For example, you need to know the difference between parametric and non-parametric tests. You should be able to explain correlation and regression and know when to use Chi-squared vs a Fisher exact test. You should know that when comparing two mean values, you typically use the Student’s t test (and know when to use paired vs unpaired versions of the test). When comparing more than 2 mean values, you use analysis of variance methods (ANOVA). You can teach yourself these concepts from a book,16 but even an introductory college level course on statistics will be immensely helpful. Most statistics textbooks provide some sort of map to guide your selection of the appropriate statistical test (Figure 6), and there are good articles in medical journals.
You can learn a lot simply by reading the Methods section of research articles. Authors will often describe the statistical tests used and why they were used. But be aware that a certain percentage of papers get published with the wrong statistics.18
One of the underlying assumptions of most parametric statistical methods is that the data may be adequately described by a normal or Gaussian distribution. This assumption needs to be verified before selecting a statistical test. The common test for data normality is the Kolmogorov-Smirnov test. The following text from a methods section describes 2 very common procedures—the Student’s t test for comparing 2 mean values and the one-way ANOVA for comparing more than 2 mean values.19
“Normal distribution of data was verified using the Kolmogorov-Smirnov test. Body weights between groups were compared using one-way ANOVA for repeated measures to investigate temporal differences. At each time point, all data were analyzed using one-way ANOVA to compare PCV and VCV groups. Tukey’s post hoc analyses were performed when significant time effects were detected within groups, and Student’s t test was used to investigate differences between groups. Data were analyzed using commercial software and values were presented as mean ± SD. A P value < .05 was considered statistically significant.”
Estimating sample size and power analysis
One very important consideration in any study is the required number of study subjects for meaningful statistical conclusions. In other words, how big should the sample size be? Sample size is important because it affects the feasibility of the study and the reliability of the conclusions in terms of statistical power. The necessary sample size depends on 2 basic factors. One factor is the variability of the data (often expressed as the standard deviation). The other factor is the effect size, meaning, for example, how big of a difference between mean values you want to detect. In general, the bigger the variability and the smaller the difference, the bigger the sample size required.
As the above equation shows, the effect size is expressed, in general, as a mean difference divided by a standard deviation. In the first case, the numerator represents the difference between the sample mean and the assumed population mean. In the denominator, SD is the standard deviation of the sample (used to estimate the standard deviation of the population). In the second case, the numerator represents the difference between the mean values of 2 samples and the denominator is the pooled standard deviation of the 2 samples.
In order to understand the issues involved with selecting sample size, we need to first understand the types of errors that can be made in any type of decision. Suppose our research goal is to make a decision about whether a new treatment results in a clinical difference (improvement). The results of our statistical test are dichotomous—we decide either yes there is a significant difference or no there isn’t. The truth, which we may never know, is that in reality, the difference exists or it doesn’t.
As Figure 7 shows, the result of our decision making is that there are 2 ways to be right and 2 ways to be wrong. If we decide there is a difference (eg, our statistical tests yields P ≤ .05) but in realty there is not a difference, then we make what is called a type I error. On the other hand, if we conclude that there is not a difference (ie, our statistical test yields P > .05) but in reality there is a difference that we did not detect, then we have made a type II error.
The associated math is shown in Figure 8. The probability of making a type I error is called alpha. By convention in medicine, we set our rejection criterion to alpha = 0.05. In other words, we would reject the null hypothesis (that there is no difference) anytime our statistical test yields a P value less than alpha. The probability of making a type II error is called beta. For historical reasons, the probability of not making a type II error is called the statistical power of the test and is equal to 1 minus beta. Power is affected by sample size: the larger the sample the larger the power. Most researchers, by convention, keep the sample size large enough to keep power above 0.80.
Figure 9 is a nomogram that brings all these ideas together. The red line shows that for your study, given the desired effect size (0.8), if you collected samples from the 30 patients you planned on then the power would be unacceptable at 0.60, indicating a high probability of a false negative decision if the P value comes out greater than .50. The solution is to increase the sample size to about 50 (or more), as indicated by the blue line. From this nomogram we can generalize to say that when you want to detect a small effect with data that have high variability, you need a large sample size to provide acceptable power.
The text below is an example of a power analysis presented in the methods section of a published study.20 Note that the authors give their reasoning for the sample size they selected. This kind of explanation may inform your study design. But what if you don’t know the variability of the data you want to collect? In that case, you need to collect some pilot data and calculate from that an appropriate sample size for a subsequent study.
A prospective power calculation indicated that a sample size of 25 per group was required to achieve 80% power based on an effect size of probability of 0.24 that an observation in the PRVCa group is less than an observation in the ASV group using the Mann-Whitney tests, an alpha of 0.05 (two-tailed) and a 20% dropout.
JUDGING FEASIBILITY
Once you have a draft of your study design, including the estimated sample size, it is time to judge the overall feasibility of the study before committing to it.
Every study has associated costs. Those costs and the sources of funding must be identified. Don’t forget costs for consultants, particularly if you need statistical consultation.
Finally, consider your level of experience. If you are contemplating your first study, a human clinical trial might not be the best choice, given the complexity of such a project. Studies such as a meta-analysis or mathematical simulation require special training beyond basic research procedures, and should be avoided.
INTRODUCTION
Basic research skills are not acquired from medical school but from a mentor.1,2 A mentor with experience in study design and technical writing can make a real difference in your career. Most good mentors have more ideas for studies than they have time for research, so they are willing to share and guide your course. Your daily clinical experience provides a wealth of ideas in the form of “why do we do it this way” or “what is the evidence for” or “how can we improve outcomes or cut cost?” Of course, just about every study you read in a medical journal has suggestions for further research in the discussion section. Finally, keep in mind that the creation of study ideas and in particular, hypotheses, is a mysterious process, as this quote indicates: “It is not possible, deliberately, to create ideas or to control their creation. What we can do deliberately is to prepare our minds.” 3 Remember that chance favors the prepared mind.
DEVELOPING THE STUDY IDEA
Often, the most difficult task for someone new to research is developing a practical study idea. This section will explain a detailed process for creating a formal research protocol. We will focus on two common sticking points: (1) finding a good idea, and (2) developing a good idea into a problem statement.
Novice researchers with little experience, no mentors, and short time frames are encouraged not to take on a clinical human study as the principle investigator. Instead, device evaluations are a low-cost, time-efficient alternative. Human studies in the form of a survey are also possible and are often exempt from full Institutional Review Board (IRB) review. Many human-like conditions can be simulated, as was done, for example, in the study of patient-ventilator synchrony.4,5 And if you have the aptitude, whole studies can be based on mathematical models and predictions, particularly with the vast array of computer tools now available.6,7 And don’t forget studies based on surveys.8
A structured approach
A formal research protocol is required for any human research. However, it is also recommended for all but the simplest investigations. Most of the new researchers I have mentored take a rather lax approach to developing the protocol, and most IRBs are more interested in protecting human rights than validating the study design. As a result, much time is wasted and sometimes an entire study has to be abandoned due to poor planning. Figure 1 illustrates a structured approach that helps to ensure success. It shows a 3-step, iterative process.
The first step is a process of expanding the scope of the project, primarily through literature review. Along the way you learn (or invent) appropriate terminology and become familiar with the current state of the research art on a broad topic. For example, let’s suppose you were interested in the factors that affect the duration of mechanical ventilation. The literature review might include topics such as weaning and patient-ventilator synchrony as well as ventilator-associated pneumonia. During this process, you might discover that the topic of synchrony is currently generating a lot of interest in the literature and generating a lot of questions or confusion. You then focus on expanding your knowledge in this area.
In the second step, you might develop a theoretical framework for understanding patient-ventilator synchrony that could include a mathematical model and, perhaps, an idea to include simulation to study the problem.
In the third step, you need to narrow the scope of the study to a manageable level that includes identifying measurable outcome variables, creating testable hypotheses, considering experimental designs, and evaluating the overall feasibility of the study. At this point, you may discover that you cannot measure the specific outcome variables indicated by your theoretical framework. In that case, you need to create a new framework for supporting your research. Alternatively, you may find that it is not possible to conduct the study you envision given your resources. In that case, it is back to step 1.
Eventually, this process will result in a well-planned research protocol that is ready for review. Keep in mind that many times a protocol needs to be refined after some initial experiments are conducted. For human studies, any changes to the protocol must be approved by the IRB.
The problem statement rubric
The most common problem I have seen novices struggle with is creating a meaningful problem statement and hypothesis. This is crucial because the problem statement sets the stage for the methods, the methods yield the results, and the results are analyzed in light of the original problem statement and hypotheses. To get past any writer’s block, I recommend that you start by just describing what you see happening and why you think it is important. For example, you might say, “Patients with acute lung injury often seem to be fighting the ventilator.” This is important because patient-ventilator asynchrony may lead to increased sedation levels and prolonged intensive care unit stays. Now you can more easily envision a specific purpose and testable hypothesis. For example, you could state that the purpose of this study is to determine the baseline rates of different kinds of patient-ventilator synchrony problems. The hypothesis is that the rate of dyssynchrony is correlated with duration of mechanical ventilation.
Here is an actual example of how a problem statement evolved from a vague notion to a testable hypothesis.
Original: The purpose of this study is to determine whether measures of ineffective cough in patients with stroke recently liberated from mechanical ventilation correlate with risk of extubation failure and reintubation.
Final: The purpose of this study is to test the hypothesis that use of CoughAssist device in the immediate post-extubation period by stroke patients reduces the rate of extubation failure and pneumonia.
The original statement is a run-on sentence that is vague and hard to follow. Once the actual treatment and outcome measures are in focus, then a clear hypothesis statement can be made. Notice that the hypothesis should be clear enough that the reader can anticipate the actual experimental measures and procedures to be described in the methods section of the protocol.
Here is another example:
Original: The purpose of this study is to evaluate a device that allows continuous electronic cuff pressure control.
Final: The purpose of this study is to test the hypothesis that the Pressure Eyes electronic cuff monitor will maintain constant endotracheal tube cuff pressures better than manual cuff inflation during mechanical ventilation.
The problem with the original statement is that “to evaluate” is vague. The final statement makes the outcome variable explicit and suggests what the experimental procedure will be.
This is a final example:
Original: Following cardiac/respiratory arrest, many patients are profoundly acidotic. Ventilator settings based on initial arterial blood gases may result in inappropriate hyperventilation when follow-up is delayed. The purpose of this study is to establish the frequency of this occurrence at a large academic institution and the feasibility of a quality improvement project.
Final: The primary purpose of this study is to evaluate the frequency of hyperventilation occurring post-arrest during the first 24 hours. A secondary purpose is to determine if this hyperventilation is associated with an initial diagnosis of acidosis.
Note that the original statement follows the rubric of telling us what is observed and why it is important. However, the actual problem statement derived from the observation is vague: what is “this occurrence” and is the study really to establish any kind of feasibility? The purpose is simply to evaluate the frequency of hyperventilation and determine if the condition is associated with acidosis.
EXAMPLES OF RESEARCH PROJECTS BY FELLOWS
The following are examples of well-written statements of study purpose from actual studies conducted by our fellows.
Device evaluation
Defining “Flow Starvation” in volume control mechanical ventilation.
- The purpose of this study is to evaluate the relationship between the patient and ventilator inspiratory work of breathing to define the term “Flow Starvation.”
Auto-positive end expiratory pressure (auto-PEEP) during airway pressure release ventilation varies with the ventilator model.
- The purpose of this study was to compare auto-PEEP levels, peak expiratory flows, and flow decay profiles among 4 common intensive care ventilators.
Patient study
Diaphragmatic electrical activity and extubation outcomes in newborn infants: an observational study.
- The purpose of this study is to describe the electrical activity of the diaphragm before, during, and after extubation in a mixed-age cohort of preterm infants.
Comparison of predicted and measured carbon dioxide production for monitoring dead space fraction during mechanical ventilation.
- The purpose of this pilot study was to compare dead space with tidal volume ratios calculated from estimated and measured values for carbon dioxide production.
Practice evaluation
Incidence of asynchronies during invasive mechanical ventilation in a medical intensive care unit.
- The purpose of this study is to conduct a pilot investigation to determine the baseline incidence of various forms of patient-ventilator dyssynchrony during invasive mechanical ventilation.
Simulation training results in improved knowledge about intubation policies and procedures.
- The purpose of this study was to develop and test a simulation-based rapid-sequence intubation curriculum for fellows in pulmonary and critical care training.
HOW TO SEARCH THE LITERATURE
After creating a problem statement, the next step in planning research is to search the literature. The 10th issue of Respiratory Care journal in 2009 was devoted to research. Here are the articles in that issue related to the literature search:
- How to find the best evidence (search internet)9
- How to read a scientific research paper10
- How to read a case report (or teaching case of the month)11
- How to read a review paper.12
I recommend that you read these papers.
Literature search resources
My best advice is to befriend your local librarian.13 These people seldom get the recognition they deserve as experts at finding information and even as co-investigators.14 In addition to personal help, some libraries offer training sessions on various useful skills.
PubMed
The Internet resource I use most often is PubMed (www.ncbi.nlm.nih.gov/pubmed). It offers free access to MEDLINE, which is the National Library of Medicine’s database of citations and abstracts in the fields of medicine, nursing, dentistry, veterinary medicine, health care systems, and preclinical sciences. There are links to full-text articles and other resources. The website provides a clinical queries search filters page as well as a special queries page. Using a feature called “My NCBI,” you can have automatic e-mailing of search updates and save records and filters for search results. Access the PubMed Quick Start Guide for frequently asked questions and tutorials.
SearchMedica.com
The SearchMedica website (www.searchmedica.co.uk) is free and intended for medical professionals. It provides answers for clinical questions. Searches return articles, abstracts, and recommended medical websites.
Synthetic databases
There is a class of websites called synthetic databases, which are essentially prefiltered records for particular topics. However, these sites are usually subscription-based, and the cost is relatively high. You should check with your medical library to get access. Their advantage is that often they provide the best evidence without extensive searches of standard, bibliographic databases. Examples include the Cochrane Database of Systematic Reviews (www.cochrane.org/evidence), the National Guideline Clearinghouse (www.guideline.gov), and UpToDate (www.uptodate.com). UpToDate claims to be the largest clinical community in the world dedicated to synthesized knowledge for clinicians and patients. It features the work of more than 6,000 expert clinician authors/reviewers on more than 10,000 topics in 23 medical specialties. The site offers graded recommendations based on the best medical evidence.
Portals
Portals are web pages that act as a starting point for using the web or web-based services. One popular example is ClinicalKey (www.clinicalkey.com/info), formerly called MD Consult, which offers books, journals, patient education materials, and images. Another popular portal is Ovid (ovid.com), offering books, journals, evidence-based medicine databases, and CINAHL (Cumulative Index to Nursing and Allied Health Literature).
Electronic journals
Many medical journals now have online databases of current and archived issues. Such sites may require membership to access the databases, so again, check with your medical library. Popular examples in pulmonary and critical care medicine include the following:
- American Journal of Respiratory and Critical Care Medicine (www.atsjournals.org/journal/ajrccm)
- The New England Journal of Medicine (www.nejm.org)
- Chest (journal.publications.chestnet.org)
- Respiratory Care (rc.rcjournal.com)
Electronic books
Amazon.com is a great database search engine for books on specific topics. It even finds out-of-print books. And you don’t have to buy the books, because now you can rent them. Sometimes, I find what I wanted by using the “Look Inside” feature for some books. Note that you can look for books at PubMed. Just change the search box from PubMed to Books on the PubMed home page. Of course, Google also has a book search feature. A great (subscription) resource for medical and technical books is Safari (https://www.safaribooksonline.com). Once again, your library may have a subscription.
General Internet resources
You probably already know about Google Scholar (scholar.google.com) and Wikipedia.com. Because of its open source nature, you should use Wikipedia with caution. However, I have found it to be a very good first step in finding technical information, particularly about mathematics, physics, and statistics.
Using reference management software
One of the most important things you can do to make your research life easier is to use some sort of reference management software. As described in Wikipedia, “Reference management software, citation management software or personal bibliographic management software is software for scholars and authors to use for recording and using bibliographic citations (references). Once a citation has been recorded, it can be used time and again in generating bibliographies, such as lists of references in scholarly books, articles, and essays.” I was late in adopting this technology, but now I am a firm believer. Most Internet reference sources offer the ability to download citations to your reference management software. Downloading automatically places the citation into a searchable database on your computer with backup to the Internet. In addition, you can get the reference manager software to find a PDF version of the manuscript and store it with the citation on your computer (and/or in the Cloud) automatically.
But the most powerful feature of such software is its ability to add or subtract and rearrange the order of references in your manuscripts as you are writing, using seamless integration with Microsoft Word. The references can be automatically formatted using just about any journal’s style. This is a great time saver for resubmitting manuscripts to different journals. If you are still numbering references by hand (God forbid) or even using the Insert Endnote feature in Word (deficient when using multiple occurrences of the same reference), your life will be much easier if you take the time to start using reference management software.
The most popular commercial software is probably EndNote (endnote.com). A really good free software system with about the same functionality as Zotero (zotero.com). Search for “comparison of reference management software” in Wikipedia. You can find tutorials on software packages in YouTube.
STUDY DESIGN
When designing the experiment, note that there are many different approaches, each with their advantages and disadvantages. A full treatment of this topic is beyond the scope of this article. Suffice it to say that pre-experimental designs (Figure 2) are considered to generate weak evidence. But they are quick and easy and might be appropriate for pilot studies.
Quasi-experimental designs (Figure 3) generate a higher level of evidence. Such a design might be appropriate when you are stuck with collecting a convenience sample, rather than being able to use a full randomized assignment of study subjects.
The fully randomized design (Figure 4) generates the highest level of evidence. This is because if the sample size is large enough, the unknown and uncontrollable sources of bias are evenly distributed between the study groups.
BASIC MEASUREMENT METHODS
If your research involves physical measurements, you need to be familiar with the devices considered to be the gold standards. In cardiopulmonary research, most measurements involve pressure volume, flow, and gas concentration. You need to know which devices are appropriate for static vs dynamic measurements of these variables. In addition, you need to understand issues related to systematic and random measurement errors and how these errors are managed through calibration and calibration verification. I recommend these two textbooks:
Principles and Practice of Intensive Care Monitoring 1st Edition by Martin J. Tobin MD.
- This book is out of print, but if you can find a used copy or one in a library, it describes just about every kind of physiologic measurement used in clinical medicine.
Medical Instrumentation: Application and Design 4th Edition by John G. Webster.
- This book is readily available and reasonably priced. It is a more technical book describing medical instrumentation and measurement principles. It is a standard textbook for biometrical engineers.
STATISTICS FOR THE UNINTERESTED
I know what you are thinking: I hate statistics. Look at the book Essential Biostatistics: A Nonmathematical Approach.15 It is a short, inexpensive paperback book that is easy to read. The author does a great job of explaining why we use statistics rather than getting bogged down explaining how we calculate them. After all, novice researchers usually seek the help of a professional statistician to do the heavy lifting.
My book, Handbook for Health Care Research,16 covers most of the statistical procedures you will encounter in medical research and gives examples of how to use a popular tactical software package called SigmaPlot. By the way, I strongly suggest that you consult a statistician early in your study design phase to avoid the disappointment of finding out later that your results are uninterpretable. For an in-depth treatment of the subject, I recommend How to Report Statistics in Medicine.17
Statistical bare essentials
To do research or even just to understand published research reports, you must have at least a minimal skill set. The necessary skills include understanding some basic terminology, if only to be able to communicate with a statistician consultant. Important terms include levels of measurement (nominal, ordinal, continuous), accuracy, precision, measures of central tendency (mean, median, mode), measures of variability (variance, standard deviation, coefficient of variation), and percentile. The first step in analyzing your results is usually to represent it graphically. That means you should be able to use a spreadsheet to make simple graphs (Figure 5).
You should also know the basics of inferential statistics (ie, hypothesis testing). For example, you need to know the difference between parametric and non-parametric tests. You should be able to explain correlation and regression and know when to use Chi-squared vs a Fisher exact test. You should know that when comparing two mean values, you typically use the Student’s t test (and know when to use paired vs unpaired versions of the test). When comparing more than 2 mean values, you use analysis of variance methods (ANOVA). You can teach yourself these concepts from a book,16 but even an introductory college level course on statistics will be immensely helpful. Most statistics textbooks provide some sort of map to guide your selection of the appropriate statistical test (Figure 6), and there are good articles in medical journals.
You can learn a lot simply by reading the Methods section of research articles. Authors will often describe the statistical tests used and why they were used. But be aware that a certain percentage of papers get published with the wrong statistics.18
One of the underlying assumptions of most parametric statistical methods is that the data may be adequately described by a normal or Gaussian distribution. This assumption needs to be verified before selecting a statistical test. The common test for data normality is the Kolmogorov-Smirnov test. The following text from a methods section describes 2 very common procedures—the Student’s t test for comparing 2 mean values and the one-way ANOVA for comparing more than 2 mean values.19
“Normal distribution of data was verified using the Kolmogorov-Smirnov test. Body weights between groups were compared using one-way ANOVA for repeated measures to investigate temporal differences. At each time point, all data were analyzed using one-way ANOVA to compare PCV and VCV groups. Tukey’s post hoc analyses were performed when significant time effects were detected within groups, and Student’s t test was used to investigate differences between groups. Data were analyzed using commercial software and values were presented as mean ± SD. A P value < .05 was considered statistically significant.”
Estimating sample size and power analysis
One very important consideration in any study is the required number of study subjects for meaningful statistical conclusions. In other words, how big should the sample size be? Sample size is important because it affects the feasibility of the study and the reliability of the conclusions in terms of statistical power. The necessary sample size depends on 2 basic factors. One factor is the variability of the data (often expressed as the standard deviation). The other factor is the effect size, meaning, for example, how big of a difference between mean values you want to detect. In general, the bigger the variability and the smaller the difference, the bigger the sample size required.
As the above equation shows, the effect size is expressed, in general, as a mean difference divided by a standard deviation. In the first case, the numerator represents the difference between the sample mean and the assumed population mean. In the denominator, SD is the standard deviation of the sample (used to estimate the standard deviation of the population). In the second case, the numerator represents the difference between the mean values of 2 samples and the denominator is the pooled standard deviation of the 2 samples.
In order to understand the issues involved with selecting sample size, we need to first understand the types of errors that can be made in any type of decision. Suppose our research goal is to make a decision about whether a new treatment results in a clinical difference (improvement). The results of our statistical test are dichotomous—we decide either yes there is a significant difference or no there isn’t. The truth, which we may never know, is that in reality, the difference exists or it doesn’t.
As Figure 7 shows, the result of our decision making is that there are 2 ways to be right and 2 ways to be wrong. If we decide there is a difference (eg, our statistical tests yields P ≤ .05) but in realty there is not a difference, then we make what is called a type I error. On the other hand, if we conclude that there is not a difference (ie, our statistical test yields P > .05) but in reality there is a difference that we did not detect, then we have made a type II error.
The associated math is shown in Figure 8. The probability of making a type I error is called alpha. By convention in medicine, we set our rejection criterion to alpha = 0.05. In other words, we would reject the null hypothesis (that there is no difference) anytime our statistical test yields a P value less than alpha. The probability of making a type II error is called beta. For historical reasons, the probability of not making a type II error is called the statistical power of the test and is equal to 1 minus beta. Power is affected by sample size: the larger the sample the larger the power. Most researchers, by convention, keep the sample size large enough to keep power above 0.80.
Figure 9 is a nomogram that brings all these ideas together. The red line shows that for your study, given the desired effect size (0.8), if you collected samples from the 30 patients you planned on then the power would be unacceptable at 0.60, indicating a high probability of a false negative decision if the P value comes out greater than .50. The solution is to increase the sample size to about 50 (or more), as indicated by the blue line. From this nomogram we can generalize to say that when you want to detect a small effect with data that have high variability, you need a large sample size to provide acceptable power.
The text below is an example of a power analysis presented in the methods section of a published study.20 Note that the authors give their reasoning for the sample size they selected. This kind of explanation may inform your study design. But what if you don’t know the variability of the data you want to collect? In that case, you need to collect some pilot data and calculate from that an appropriate sample size for a subsequent study.
A prospective power calculation indicated that a sample size of 25 per group was required to achieve 80% power based on an effect size of probability of 0.24 that an observation in the PRVCa group is less than an observation in the ASV group using the Mann-Whitney tests, an alpha of 0.05 (two-tailed) and a 20% dropout.
JUDGING FEASIBILITY
Once you have a draft of your study design, including the estimated sample size, it is time to judge the overall feasibility of the study before committing to it.
Every study has associated costs. Those costs and the sources of funding must be identified. Don’t forget costs for consultants, particularly if you need statistical consultation.
Finally, consider your level of experience. If you are contemplating your first study, a human clinical trial might not be the best choice, given the complexity of such a project. Studies such as a meta-analysis or mathematical simulation require special training beyond basic research procedures, and should be avoided.
- Tobin MJ. Mentoring: seven roles and some specifics. Am J Respir Crit Care Med 2004; 170:114–117.
- Chatburn RL. Advancing beyond the average: the importance of mentoring in professional achievement. Respir Care 2004; 49:304–308.
- Beveridge WIB. The Art of Scientific Investigation. New York, NY: WW Norton & Company; 1950.
- Chatburn RL, Mireles-Cabodevila E, Sasidhar M. Tidal volume measurement error in pressure control modes of mechanical ventilation: a model study. Comput Biol Med 2016; 75:235–242.
- Mireles-Cabodevila E, Chatburn RL. Work of breathing in adaptive pressure control continuous mandatory ventilation. Respir Care 2009; 54:1467–1472.
- Chatburn RL, Ford RM. Procedure to normalize data for benchmarking. Respir Care 2006; 51:145–157.
- Bou-Khalil P, Zeineldine S, Chatburn R, et al. Prediction of inspired oxygen fraction for targeted arterial oxygen tension following open heart surgery in non-smoking and smoking patients. J Clin Monit Comput 2016. https://doi.org/10.1007/s10877-016-9941-6.
- Mireles-Cabodevila E, Diaz-Guzman E, Arroliga AC, Chatburn RL. Human versus computer controlled selection of ventilator settings: an evaluation of adaptive support ventilation and mid-frequency ventilation. Crit Care Res Pract 2012; 2012:204314.
- Chatburn RL. How to find the best evidence. Respir Care 2009; 54:1360–1365.
- Durbin CG Jr. How to read a scientific research paper. Respir Care 2009; 54:1366–1371.
- Pierson DJ. How to read a case report (or teaching case of the month). Respir Care 2009; 54:1372–1378.
- Callcut RA, Branson RD. How to read a review paper. Respir Care 2009; 54:1379–1385.
- Eresuma E, Lake E. How do I find the evidence? Find your librarian—stat! Orthop Nurs 2016; 35:421–423.
- Janke R, Rush KL. The academic librarian as co-investigator on an interprofessional primary research team: a case study. Health Info Libr J 2014; 31:116–122.
- Motulsky H. Essential Biostatistics: A Nonmathematical Approach. New York, NY: Oxford University Press; 2016.
- Chatburn RL. Handbook for Health Care Research. 2nd ed. Sudbury, MA: Jones and Bartlett Publishers; 2011.
- Lang TA, Secic M. How to Report Statistics in Medicine. 2nd ed. Philadelphia, PA: American College of Physicians; 2006.
- Prescott RJ, Civil I. Lies, damn lies and statistics: errors and omission in papers submitted to INJURY 2010–2012. Injury 2013; 44:6–11.
- Fantoni DT, Ida KK, Lopes TF, Otsuki DA, Auler JO Jr, Ambrosio AM. A comparison of the cardiopulmonary effects of pressure controlled ventilation and volume controlled ventilation in healthy anesthetized dogs. J Vet Emerg Crit Care (San Antonio) 2016; 26:524–530.
- Gruber PC, Gomersall CD, Leung P, et al. Randomized controlled trial comparing adaptive-support ventilation with pressure-regulated volume-controlled ventilation with automode in weaning patients after cardiac surgery. Anesthesiology 2008; 109:81–87.
- Tobin MJ. Mentoring: seven roles and some specifics. Am J Respir Crit Care Med 2004; 170:114–117.
- Chatburn RL. Advancing beyond the average: the importance of mentoring in professional achievement. Respir Care 2004; 49:304–308.
- Beveridge WIB. The Art of Scientific Investigation. New York, NY: WW Norton & Company; 1950.
- Chatburn RL, Mireles-Cabodevila E, Sasidhar M. Tidal volume measurement error in pressure control modes of mechanical ventilation: a model study. Comput Biol Med 2016; 75:235–242.
- Mireles-Cabodevila E, Chatburn RL. Work of breathing in adaptive pressure control continuous mandatory ventilation. Respir Care 2009; 54:1467–1472.
- Chatburn RL, Ford RM. Procedure to normalize data for benchmarking. Respir Care 2006; 51:145–157.
- Bou-Khalil P, Zeineldine S, Chatburn R, et al. Prediction of inspired oxygen fraction for targeted arterial oxygen tension following open heart surgery in non-smoking and smoking patients. J Clin Monit Comput 2016. https://doi.org/10.1007/s10877-016-9941-6.
- Mireles-Cabodevila E, Diaz-Guzman E, Arroliga AC, Chatburn RL. Human versus computer controlled selection of ventilator settings: an evaluation of adaptive support ventilation and mid-frequency ventilation. Crit Care Res Pract 2012; 2012:204314.
- Chatburn RL. How to find the best evidence. Respir Care 2009; 54:1360–1365.
- Durbin CG Jr. How to read a scientific research paper. Respir Care 2009; 54:1366–1371.
- Pierson DJ. How to read a case report (or teaching case of the month). Respir Care 2009; 54:1372–1378.
- Callcut RA, Branson RD. How to read a review paper. Respir Care 2009; 54:1379–1385.
- Eresuma E, Lake E. How do I find the evidence? Find your librarian—stat! Orthop Nurs 2016; 35:421–423.
- Janke R, Rush KL. The academic librarian as co-investigator on an interprofessional primary research team: a case study. Health Info Libr J 2014; 31:116–122.
- Motulsky H. Essential Biostatistics: A Nonmathematical Approach. New York, NY: Oxford University Press; 2016.
- Chatburn RL. Handbook for Health Care Research. 2nd ed. Sudbury, MA: Jones and Bartlett Publishers; 2011.
- Lang TA, Secic M. How to Report Statistics in Medicine. 2nd ed. Philadelphia, PA: American College of Physicians; 2006.
- Prescott RJ, Civil I. Lies, damn lies and statistics: errors and omission in papers submitted to INJURY 2010–2012. Injury 2013; 44:6–11.
- Fantoni DT, Ida KK, Lopes TF, Otsuki DA, Auler JO Jr, Ambrosio AM. A comparison of the cardiopulmonary effects of pressure controlled ventilation and volume controlled ventilation in healthy anesthetized dogs. J Vet Emerg Crit Care (San Antonio) 2016; 26:524–530.
- Gruber PC, Gomersall CD, Leung P, et al. Randomized controlled trial comparing adaptive-support ventilation with pressure-regulated volume-controlled ventilation with automode in weaning patients after cardiac surgery. Anesthesiology 2008; 109:81–87.
