User login
For MD-IQ use only
Massive databases unleash discovery, but not so much in the U.S.
Which conditions are caused by infection? Though it may seem like an amateur concern in the era of advanced microscopy, some culprits evade conventional methods of detection. Large medical databases hold the power to unlock answers.
A recent study from Sweden and Denmark meticulously traced the lives and medical histories of nearly one million men and women in those countries who had received blood transfusions over nearly five decades. Some of these patients later experienced brain bleeds. The inescapable question: Could a virus found in some donor blood have caused the hemorrhages?
Traditionally, brain bleeds have been thought to strike at random. But the new study, published in JAMA, points toward an infection that causes or, at the very least, is linked to the condition. The researchers used a large databank to make the discovery. 
“As health data becomes more available and easier to analyze, we’ll see all kinds of cases like this,” said Jingcheng Zhao, MD, of the clinical epidemiology division of Sweden’s Karolinska Institutet in Solna and lead author of the study.
Scientists say the field of medical research is on the cusp of a revolution as immense health databases guide discovery and improve clinical care.
“If you can aggregate data, you have the statistical power to identify associations,” said David R. Crosslin, PhD, professor in the division of biomedical informatics and genomics at Tulane University in New Orleans. “It opens up the world for understanding diseases.”
With access to the large database, Dr. Zhao and his team found that some blood donors later experienced brain bleeds. And it turned out that the recipients of blood from those same donors carried the highest risk of experiencing a brain bleed later in life. Meanwhile, patients whose donors remained bleed-free had the lowest risk.
Not so fast in the United States
In Nordic countries, all hospitals, clinics, and pharmacies report data on diagnoses and health care visits to the government, tracking that began with paper and pen in the 1960s. But the United States health care system is too fragmented to replicate such efforts, with several brands of electronic medical records operating across different systems. Data sharing across institutions is minimal.
Most comparable health data in the United States comes from reimbursement information collected by the Centers for Medicare & Medicaid Services on government-sponsored insurance programs.
“We would need all the health care systems in the country to operate within the same IT system or use the same data model,” said Euan Ashley, MD, PhD, professor of genomics at Stanford (Calif.) University. “It’s an exciting prospect. But I think [the United States] is one of the last countries where it’ll happen.”
States, meanwhile, collect health data on specific areas like sexually transmitted infection cases and rates. Other states have registries, like the Connecticut Tumor Registry, which was established in 1941 and is the oldest population-based cancer registry in the world.
But all of these efforts are ad hoc, and no equivalent exists for heart disease and other conditions.
Health data companies have recently entered the U.S. data industry mainly through partnerships with health systems and insurance companies, using deidentified information from patient charts.
The large databases have yielded important findings that randomized clinical trials simply cannot, according to Dr. Ashley.
For instance, a study found that a heavily-lauded immunotherapy treatment did not provide meaningful outcomes for patients aged 75 years or older, but it did for younger patients.
This sort of analysis might enable clinicians to administer treatments based on how effective they are for patients with particular demographics, according to Cary Gross, MD, professor at Yale University in New Haven, Conn.
“From a bedside standpoint, these large databases can identify who benefits from what,” Dr. Gross said. “Precision medicine is not just about genetic tailoring.” These large datasets also provide insight into genetic and environmental variables that contribute to disease.
For instance, the UK Biobank has more than 500,000 participants paired with their medical records and scans of their body and brain. Researchers perform cognitive tests on participants and extract DNA from blood samples over their lifetime, allowing examination of interactions between risk factors.
A similar but much smaller-scale effort underway in the United States, called the All of Us Research Program, has enrolled more than 650,000 people, less than one-third the size of the UK Biobank by relative populations. The goal of the program is to provide insights into prevention and treatment of chronic disease among a diverse set of at least one million participants. The database includes information on sexual orientation, which is a fairly new datapoint collected by researchers in an effort to study health outcomes and inequities among the LGBTQ+ community.
Dr. Crosslin and his colleagues are writing a grant proposal to use the All of Us database to identify genetic risks for preeclampsia. People with certain genetic profiles may be predisposed to the life-threatening condition, and researchers may discover that lifestyle changes could decrease risk, Dr. Crosslin said.
Changes in the United States
The COVID-19 pandemic exposed the lack of centralized data in the United States because a majority of research on the virus has been conducted abroad in countries with national health care systems and these large databases.
The U.S. gap spurred a group of researchers to create the National Institutes of Health–funded National COVID Cohort Collaborative (N3C), a project that gathers medical records from millions of patients across health systems and provides access to research teams investigating a wide spectrum of topics, such as optimal timing for ventilator use.
But until government or private health systems develop a way to share and regulate health data ethically and efficiently, significant limits will persist on what large-scale databases can do, Dr. Gross said.
“At the federal level, we need to ensure this health information is made available for public health researchers so we don’t create these private fiefdoms of data,” Dr. Gross said. “Things have to be transparent. I think our country needs to take a step back and think about what we’re doing with our health data and how we can make sure it’s being managed ethically.”
A version of this article first appeared on Medscape.com.
Which conditions are caused by infection? Though it may seem like an amateur concern in the era of advanced microscopy, some culprits evade conventional methods of detection. Large medical databases hold the power to unlock answers.
A recent study from Sweden and Denmark meticulously traced the lives and medical histories of nearly one million men and women in those countries who had received blood transfusions over nearly five decades. Some of these patients later experienced brain bleeds. The inescapable question: Could a virus found in some donor blood have caused the hemorrhages?
Traditionally, brain bleeds have been thought to strike at random. But the new study, published in JAMA, points toward an infection that causes or, at the very least, is linked to the condition. The researchers used a large databank to make the discovery.
“As health data becomes more available and easier to analyze, we’ll see all kinds of cases like this,” said Jingcheng Zhao, MD, of the clinical epidemiology division of Sweden’s Karolinska Institutet in Solna and lead author of the study.
Scientists say the field of medical research is on the cusp of a revolution as immense health databases guide discovery and improve clinical care.
“If you can aggregate data, you have the statistical power to identify associations,” said David R. Crosslin, PhD, professor in the division of biomedical informatics and genomics at Tulane University in New Orleans. “It opens up the world for understanding diseases.”
With access to the large database, Dr. Zhao and his team found that some blood donors later experienced brain bleeds. And it turned out that the recipients of blood from those same donors carried the highest risk of experiencing a brain bleed later in life. Meanwhile, patients whose donors remained bleed-free had the lowest risk.
Not so fast in the United States
In Nordic countries, all hospitals, clinics, and pharmacies report data on diagnoses and health care visits to the government, tracking that began with paper and pen in the 1960s. But the United States health care system is too fragmented to replicate such efforts, with several brands of electronic medical records operating across different systems. Data sharing across institutions is minimal.
Most comparable health data in the United States comes from reimbursement information collected by the Centers for Medicare & Medicaid Services on government-sponsored insurance programs.
“We would need all the health care systems in the country to operate within the same IT system or use the same data model,” said Euan Ashley, MD, PhD, professor of genomics at Stanford (Calif.) University. “It’s an exciting prospect. But I think [the United States] is one of the last countries where it’ll happen.”
States, meanwhile, collect health data on specific areas like sexually transmitted infection cases and rates. Other states have registries, like the Connecticut Tumor Registry, which was established in 1941 and is the oldest population-based cancer registry in the world.
But all of these efforts are ad hoc, and no equivalent exists for heart disease and other conditions.
Health data companies have recently entered the U.S. data industry mainly through partnerships with health systems and insurance companies, using deidentified information from patient charts.
The large databases have yielded important findings that randomized clinical trials simply cannot, according to Dr. Ashley.
For instance, a study found that a heavily-lauded immunotherapy treatment did not provide meaningful outcomes for patients aged 75 years or older, but it did for younger patients.
This sort of analysis might enable clinicians to administer treatments based on how effective they are for patients with particular demographics, according to Cary Gross, MD, professor at Yale University in New Haven, Conn.
“From a bedside standpoint, these large databases can identify who benefits from what,” Dr. Gross said. “Precision medicine is not just about genetic tailoring.” These large datasets also provide insight into genetic and environmental variables that contribute to disease.
For instance, the UK Biobank has more than 500,000 participants paired with their medical records and scans of their body and brain. Researchers perform cognitive tests on participants and extract DNA from blood samples over their lifetime, allowing examination of interactions between risk factors.
A similar but much smaller-scale effort underway in the United States, called the All of Us Research Program, has enrolled more than 650,000 people, less than one-third the size of the UK Biobank by relative populations. The goal of the program is to provide insights into prevention and treatment of chronic disease among a diverse set of at least one million participants. The database includes information on sexual orientation, which is a fairly new datapoint collected by researchers in an effort to study health outcomes and inequities among the LGBTQ+ community.
Dr. Crosslin and his colleagues are writing a grant proposal to use the All of Us database to identify genetic risks for preeclampsia. People with certain genetic profiles may be predisposed to the life-threatening condition, and researchers may discover that lifestyle changes could decrease risk, Dr. Crosslin said.
Changes in the United States
The COVID-19 pandemic exposed the lack of centralized data in the United States because a majority of research on the virus has been conducted abroad in countries with national health care systems and these large databases.
The U.S. gap spurred a group of researchers to create the National Institutes of Health–funded National COVID Cohort Collaborative (N3C), a project that gathers medical records from millions of patients across health systems and provides access to research teams investigating a wide spectrum of topics, such as optimal timing for ventilator use.
But until government or private health systems develop a way to share and regulate health data ethically and efficiently, significant limits will persist on what large-scale databases can do, Dr. Gross said.
“At the federal level, we need to ensure this health information is made available for public health researchers so we don’t create these private fiefdoms of data,” Dr. Gross said. “Things have to be transparent. I think our country needs to take a step back and think about what we’re doing with our health data and how we can make sure it’s being managed ethically.”
A version of this article first appeared on Medscape.com.
Which conditions are caused by infection? Though it may seem like an amateur concern in the era of advanced microscopy, some culprits evade conventional methods of detection. Large medical databases hold the power to unlock answers.
A recent study from Sweden and Denmark meticulously traced the lives and medical histories of nearly one million men and women in those countries who had received blood transfusions over nearly five decades. Some of these patients later experienced brain bleeds. The inescapable question: Could a virus found in some donor blood have caused the hemorrhages?
Traditionally, brain bleeds have been thought to strike at random. But the new study, published in JAMA, points toward an infection that causes or, at the very least, is linked to the condition. The researchers used a large databank to make the discovery.
“As health data becomes more available and easier to analyze, we’ll see all kinds of cases like this,” said Jingcheng Zhao, MD, of the clinical epidemiology division of Sweden’s Karolinska Institutet in Solna and lead author of the study.
Scientists say the field of medical research is on the cusp of a revolution as immense health databases guide discovery and improve clinical care.
“If you can aggregate data, you have the statistical power to identify associations,” said David R. Crosslin, PhD, professor in the division of biomedical informatics and genomics at Tulane University in New Orleans. “It opens up the world for understanding diseases.”
With access to the large database, Dr. Zhao and his team found that some blood donors later experienced brain bleeds. And it turned out that the recipients of blood from those same donors carried the highest risk of experiencing a brain bleed later in life. Meanwhile, patients whose donors remained bleed-free had the lowest risk.
Not so fast in the United States
In Nordic countries, all hospitals, clinics, and pharmacies report data on diagnoses and health care visits to the government, tracking that began with paper and pen in the 1960s. But the United States health care system is too fragmented to replicate such efforts, with several brands of electronic medical records operating across different systems. Data sharing across institutions is minimal.
Most comparable health data in the United States comes from reimbursement information collected by the Centers for Medicare & Medicaid Services on government-sponsored insurance programs.
“We would need all the health care systems in the country to operate within the same IT system or use the same data model,” said Euan Ashley, MD, PhD, professor of genomics at Stanford (Calif.) University. “It’s an exciting prospect. But I think [the United States] is one of the last countries where it’ll happen.”
States, meanwhile, collect health data on specific areas like sexually transmitted infection cases and rates. Other states have registries, like the Connecticut Tumor Registry, which was established in 1941 and is the oldest population-based cancer registry in the world.
But all of these efforts are ad hoc, and no equivalent exists for heart disease and other conditions.
Health data companies have recently entered the U.S. data industry mainly through partnerships with health systems and insurance companies, using deidentified information from patient charts.
The large databases have yielded important findings that randomized clinical trials simply cannot, according to Dr. Ashley.
For instance, a study found that a heavily-lauded immunotherapy treatment did not provide meaningful outcomes for patients aged 75 years or older, but it did for younger patients.
This sort of analysis might enable clinicians to administer treatments based on how effective they are for patients with particular demographics, according to Cary Gross, MD, professor at Yale University in New Haven, Conn.
“From a bedside standpoint, these large databases can identify who benefits from what,” Dr. Gross said. “Precision medicine is not just about genetic tailoring.” These large datasets also provide insight into genetic and environmental variables that contribute to disease.
For instance, the UK Biobank has more than 500,000 participants paired with their medical records and scans of their body and brain. Researchers perform cognitive tests on participants and extract DNA from blood samples over their lifetime, allowing examination of interactions between risk factors.
A similar but much smaller-scale effort underway in the United States, called the All of Us Research Program, has enrolled more than 650,000 people, less than one-third the size of the UK Biobank by relative populations. The goal of the program is to provide insights into prevention and treatment of chronic disease among a diverse set of at least one million participants. The database includes information on sexual orientation, which is a fairly new datapoint collected by researchers in an effort to study health outcomes and inequities among the LGBTQ+ community.
Dr. Crosslin and his colleagues are writing a grant proposal to use the All of Us database to identify genetic risks for preeclampsia. People with certain genetic profiles may be predisposed to the life-threatening condition, and researchers may discover that lifestyle changes could decrease risk, Dr. Crosslin said.
Changes in the United States
The COVID-19 pandemic exposed the lack of centralized data in the United States because a majority of research on the virus has been conducted abroad in countries with national health care systems and these large databases.
The U.S. gap spurred a group of researchers to create the National Institutes of Health–funded National COVID Cohort Collaborative (N3C), a project that gathers medical records from millions of patients across health systems and provides access to research teams investigating a wide spectrum of topics, such as optimal timing for ventilator use.
But until government or private health systems develop a way to share and regulate health data ethically and efficiently, significant limits will persist on what large-scale databases can do, Dr. Gross said.
“At the federal level, we need to ensure this health information is made available for public health researchers so we don’t create these private fiefdoms of data,” Dr. Gross said. “Things have to be transparent. I think our country needs to take a step back and think about what we’re doing with our health data and how we can make sure it’s being managed ethically.”
A version of this article first appeared on Medscape.com.
‘Why did I choose this?’ Tackling burnout in oncology
MADRID – “Why did I choose this?”
That is the core question a Portuguese oncologist posed from the audience during a session at the annual meeting of the European Society for Medical Oncology (ESMO) that was dedicated to building a sustainable oncology workforce.
“Ten, twenty years ago, being a doctor was a dream,” she said, but right now doctors are underpaid, under strain, and have very few resources.
This oncologist is hardly alone.
A survey from ESMO conducted almost a decade ago found that more than 50% of oncologists across Europe, many of whom were early in their careers, reported being burned out.
This, Dr. Lim said, “was the starting point,” well before the COVID pandemic struck.
More recently, the pandemic has taken its own toll on the well-being of oncologists. A survey presented at ESMO 2020 revealed that 38% of participants, spanning 101 countries, reported experiencing burnout, and 66% said they were not able to perform their job.
Medscape’s 2023 Physician Burnout and Depression Report highlighted similar burnout rates, with 53% of U.S. physicians and 52% of oncologists saying they felt burned out, compared with about 42% in 2018, before the pandemic.
The oncology workforce is in crisis in every country, said Dr. Lim, from the Cancer Dynamics Lab, the Francis Crick Institute, London.
Burnout, characterized by emotional exhaustion, depersonalization or feelings of cynicism, and a low sense of personal accomplishment, can result in a poor work-life balance as well as poor mental and physical health. Factors linked to burnout include social isolation, increased workload, reduced quality of work, lack of control over work, and stressful professional experiences.
Together, these factors can affect patient care and further exacerbate staffing issues, Dr. Lim said.
Staffing shortages are common. Oncologists often work long hours or on weekends to cover gaps caused by staffing shortages. Recent data revealed that in high-income countries, there are on average 0.65 medical oncologists and 0.25 radiation oncologists per 100 patients — a situation made worse by professionals taking early retirement or leaving medicine during the pandemic.
“We have seen that the shortage of human resources in many countries as well as the increasing workload related to the increasing number of cancers,” as well as patients surviving longer, have increased pressures on the healthcare system, Andrés Cervantes, MD, PhD, president of ESMO, explained in a press conference.
While tackling these oncology workforce problems requires smaller, local changes to a physician’s daily routine, “the real change,” Dr. Lim said, lies at an infrastructure level.
In response to this chronic and growing problem, ESMO launched its Resilience Task Force in 2020 to evaluate burnout and well-being. The task force plans to publish a position paper in which it will propose a set of recommendations regarding the psychosocial risks of burnout as well as flexible work patterns, well-being resources, and targeted support.
A panel of experts at the meeting touched on some of these solutions.
Dealing with staff shortages is a must, said Jean-Yves Blay, MD, PhD, during the session. “It’s a simple mathematical equation,” Dr. Blay said. “We must increase the number of doctors in medical schools and the number of nurses and healthcare professionals in all schools.” Improving staffing would also help reduce chronic workload issues.
Resilience training should also be incorporated into physician training starting in medical school. Teaching oncologists how to deal with bad news and to cope when patients dies is particularly important.
“I was not taught that,” said the oncologist from Portugal. “I had to learn that at my own cost.”
The good news is that it’s possible to develop resiliency skills over time, said Claire Hardy, PhD, from Lancaster University, United Kingdom, who agreed that training programs could be one approach to improve oncologists’ work life.
However, a person’s needs are determined by their institution and personal responsibilities. “No one knows your job better than you,” Dr. Hardy said. “No one knows better than you where the inefficiencies are, where the bureaucracy is that could be taken away, or it could be done by somebody whose role it is to sort all that out.”
But having this understanding is not enough. Physician also need to feel “psychological safety to be able to speak out and say that something isn’t working right now or is too much,” or, “I’m spending too much time doing this.”
In other words, oncologists need to be able to set boundaries and say no.
Dr. Hardy said this concept “has been around a while, but it’s really gaining momentum,” and being able to discuss these issues in a forum such as the ESMO Congress is a promising start.
Dr. Lim has relationships with Janseen and SEOM. No other relevant financial relationships were disclosed.
A version of this article first appeared on Medscape.com.
MADRID – “Why did I choose this?”
That is the core question a Portuguese oncologist posed from the audience during a session at the annual meeting of the European Society for Medical Oncology (ESMO) that was dedicated to building a sustainable oncology workforce.
“Ten, twenty years ago, being a doctor was a dream,” she said, but right now doctors are underpaid, under strain, and have very few resources.
This oncologist is hardly alone.
A survey from ESMO conducted almost a decade ago found that more than 50% of oncologists across Europe, many of whom were early in their careers, reported being burned out.
This, Dr. Lim said, “was the starting point,” well before the COVID pandemic struck.
More recently, the pandemic has taken its own toll on the well-being of oncologists. A survey presented at ESMO 2020 revealed that 38% of participants, spanning 101 countries, reported experiencing burnout, and 66% said they were not able to perform their job.
Medscape’s 2023 Physician Burnout and Depression Report highlighted similar burnout rates, with 53% of U.S. physicians and 52% of oncologists saying they felt burned out, compared with about 42% in 2018, before the pandemic.
The oncology workforce is in crisis in every country, said Dr. Lim, from the Cancer Dynamics Lab, the Francis Crick Institute, London.
Burnout, characterized by emotional exhaustion, depersonalization or feelings of cynicism, and a low sense of personal accomplishment, can result in a poor work-life balance as well as poor mental and physical health. Factors linked to burnout include social isolation, increased workload, reduced quality of work, lack of control over work, and stressful professional experiences.
Together, these factors can affect patient care and further exacerbate staffing issues, Dr. Lim said.
Staffing shortages are common. Oncologists often work long hours or on weekends to cover gaps caused by staffing shortages. Recent data revealed that in high-income countries, there are on average 0.65 medical oncologists and 0.25 radiation oncologists per 100 patients — a situation made worse by professionals taking early retirement or leaving medicine during the pandemic.
“We have seen that the shortage of human resources in many countries as well as the increasing workload related to the increasing number of cancers,” as well as patients surviving longer, have increased pressures on the healthcare system, Andrés Cervantes, MD, PhD, president of ESMO, explained in a press conference.
While tackling these oncology workforce problems requires smaller, local changes to a physician’s daily routine, “the real change,” Dr. Lim said, lies at an infrastructure level.
In response to this chronic and growing problem, ESMO launched its Resilience Task Force in 2020 to evaluate burnout and well-being. The task force plans to publish a position paper in which it will propose a set of recommendations regarding the psychosocial risks of burnout as well as flexible work patterns, well-being resources, and targeted support.
A panel of experts at the meeting touched on some of these solutions.
Dealing with staff shortages is a must, said Jean-Yves Blay, MD, PhD, during the session. “It’s a simple mathematical equation,” Dr. Blay said. “We must increase the number of doctors in medical schools and the number of nurses and healthcare professionals in all schools.” Improving staffing would also help reduce chronic workload issues.
Resilience training should also be incorporated into physician training starting in medical school. Teaching oncologists how to deal with bad news and to cope when patients dies is particularly important.
“I was not taught that,” said the oncologist from Portugal. “I had to learn that at my own cost.”
The good news is that it’s possible to develop resiliency skills over time, said Claire Hardy, PhD, from Lancaster University, United Kingdom, who agreed that training programs could be one approach to improve oncologists’ work life.
However, a person’s needs are determined by their institution and personal responsibilities. “No one knows your job better than you,” Dr. Hardy said. “No one knows better than you where the inefficiencies are, where the bureaucracy is that could be taken away, or it could be done by somebody whose role it is to sort all that out.”
But having this understanding is not enough. Physician also need to feel “psychological safety to be able to speak out and say that something isn’t working right now or is too much,” or, “I’m spending too much time doing this.”
In other words, oncologists need to be able to set boundaries and say no.
Dr. Hardy said this concept “has been around a while, but it’s really gaining momentum,” and being able to discuss these issues in a forum such as the ESMO Congress is a promising start.
Dr. Lim has relationships with Janseen and SEOM. No other relevant financial relationships were disclosed.
A version of this article first appeared on Medscape.com.
MADRID – “Why did I choose this?”
That is the core question a Portuguese oncologist posed from the audience during a session at the annual meeting of the European Society for Medical Oncology (ESMO) that was dedicated to building a sustainable oncology workforce.
“Ten, twenty years ago, being a doctor was a dream,” she said, but right now doctors are underpaid, under strain, and have very few resources.
This oncologist is hardly alone.
A survey from ESMO conducted almost a decade ago found that more than 50% of oncologists across Europe, many of whom were early in their careers, reported being burned out.
This, Dr. Lim said, “was the starting point,” well before the COVID pandemic struck.
More recently, the pandemic has taken its own toll on the well-being of oncologists. A survey presented at ESMO 2020 revealed that 38% of participants, spanning 101 countries, reported experiencing burnout, and 66% said they were not able to perform their job.
Medscape’s 2023 Physician Burnout and Depression Report highlighted similar burnout rates, with 53% of U.S. physicians and 52% of oncologists saying they felt burned out, compared with about 42% in 2018, before the pandemic.
The oncology workforce is in crisis in every country, said Dr. Lim, from the Cancer Dynamics Lab, the Francis Crick Institute, London.
Burnout, characterized by emotional exhaustion, depersonalization or feelings of cynicism, and a low sense of personal accomplishment, can result in a poor work-life balance as well as poor mental and physical health. Factors linked to burnout include social isolation, increased workload, reduced quality of work, lack of control over work, and stressful professional experiences.
Together, these factors can affect patient care and further exacerbate staffing issues, Dr. Lim said.
Staffing shortages are common. Oncologists often work long hours or on weekends to cover gaps caused by staffing shortages. Recent data revealed that in high-income countries, there are on average 0.65 medical oncologists and 0.25 radiation oncologists per 100 patients — a situation made worse by professionals taking early retirement or leaving medicine during the pandemic.
“We have seen that the shortage of human resources in many countries as well as the increasing workload related to the increasing number of cancers,” as well as patients surviving longer, have increased pressures on the healthcare system, Andrés Cervantes, MD, PhD, president of ESMO, explained in a press conference.
While tackling these oncology workforce problems requires smaller, local changes to a physician’s daily routine, “the real change,” Dr. Lim said, lies at an infrastructure level.
In response to this chronic and growing problem, ESMO launched its Resilience Task Force in 2020 to evaluate burnout and well-being. The task force plans to publish a position paper in which it will propose a set of recommendations regarding the psychosocial risks of burnout as well as flexible work patterns, well-being resources, and targeted support.
A panel of experts at the meeting touched on some of these solutions.
Dealing with staff shortages is a must, said Jean-Yves Blay, MD, PhD, during the session. “It’s a simple mathematical equation,” Dr. Blay said. “We must increase the number of doctors in medical schools and the number of nurses and healthcare professionals in all schools.” Improving staffing would also help reduce chronic workload issues.
Resilience training should also be incorporated into physician training starting in medical school. Teaching oncologists how to deal with bad news and to cope when patients dies is particularly important.
“I was not taught that,” said the oncologist from Portugal. “I had to learn that at my own cost.”
The good news is that it’s possible to develop resiliency skills over time, said Claire Hardy, PhD, from Lancaster University, United Kingdom, who agreed that training programs could be one approach to improve oncologists’ work life.
However, a person’s needs are determined by their institution and personal responsibilities. “No one knows your job better than you,” Dr. Hardy said. “No one knows better than you where the inefficiencies are, where the bureaucracy is that could be taken away, or it could be done by somebody whose role it is to sort all that out.”
But having this understanding is not enough. Physician also need to feel “psychological safety to be able to speak out and say that something isn’t working right now or is too much,” or, “I’m spending too much time doing this.”
In other words, oncologists need to be able to set boundaries and say no.
Dr. Hardy said this concept “has been around a while, but it’s really gaining momentum,” and being able to discuss these issues in a forum such as the ESMO Congress is a promising start.
Dr. Lim has relationships with Janseen and SEOM. No other relevant financial relationships were disclosed.
A version of this article first appeared on Medscape.com.
FROM ESMO 2023
The sobering facts about alcohol and cancer
There is an urgent need to raise global awareness about the direct link between alcohol consumption and cancer risk.
That message was delivered by Isabelle Soerjomataram, PhD, with the International Agency for Research on Cancer (IARC), Lyon, France, at a session devoted to alcohol and cancer at the annual meeting of the European Society for Medical Oncology.
Dr. Soerjomataram told the audience. “Health professionals – oncologists, nurses, medical doctors, GPs – have an important role in increasing awareness and bringing this knowledge to people, which may lead to reduced consumption.”
Session chair Gilberto Morgan, MD, medical oncologist, Skåne University Hospital, Lund, Sweden, agreed.
Dr. Morgan noted that healthcare professionals tend to downplay their influence over patients’ drinking habits and often don’t address these behaviors.
But that needs to change.
“We have absolutely no problem asking patients if they take supplements or vitamins or if they’re eating [healthy],” Dr. Morgan said. “So, what is the difference? Why not recommend that they cut down their alcohol intake and leave it up to everybody’s personal choice to do it or not?”
In the session, Dr. Soerjomataram highlighted the global statistics on alcohol use. IARC data show, for instance, that nearly half (46%) of the world’s population consumes alcohol, with rates higher in men (54%) than women (38%).
How much are people drinking?
Globally, on average, the amount comes to about six liters of pure ethanol per year per drinker, or about one wine bottle per week. However, consumption patterns vary widely by country. In France, people consume about 12 liters per year or about two wine bottles per week.
Dr. Soerjomataram stressed the link between alcohol consumption and cancer.
According to IARC data, heavy drinking – defined as more than 60 g/day or about six daily drinks – accounts for 47% of the alcohol-attributable cancers. Risky drinking – between 20 and 60 g/day – accounts for 29%, she explained, while moderate drinking – less than 20 g/day or about two daily drinks – accounts for roughly 14% of cases of alcohol-attributable cancers.
Globally, alcohol intake accounted for 4% of all cancers diagnosed in 2020, according to a 2021 analysis by IARC.
In the United Kingdom alone, “alcohol drinking caused nearly 17,000 cases of cancer in 2020,” Dr. Soerjomataram said, and breast cancer made up almost one in four of those new cases.
In addition to breast cancer, six other cancer types – oral cavity, pharyngeal, laryngeal, esophageal, colorectal, and liver cancer – can be attributed to alcohol consumption, and emerging evidence suggests stomach and pancreatic cancer may be as well.
The good news, said Dr. Soerjomataram, is that long-term trends show declines in alcohol drinking in many countries, including the high wine-producing countries of France and Italy, where large reductions in consumption have been noted since the peak of intake in the 1920s.
“If it’s possible in these countries, I can imagine it’s possible elsewhere,” said Dr. Soerjomataram.
Dr. Soerjomataram and Dr. Morgan report no relevant financial relationships.
A version of this article first appeared on Medscape.com.
There is an urgent need to raise global awareness about the direct link between alcohol consumption and cancer risk.
That message was delivered by Isabelle Soerjomataram, PhD, with the International Agency for Research on Cancer (IARC), Lyon, France, at a session devoted to alcohol and cancer at the annual meeting of the European Society for Medical Oncology.
Dr. Soerjomataram told the audience. “Health professionals – oncologists, nurses, medical doctors, GPs – have an important role in increasing awareness and bringing this knowledge to people, which may lead to reduced consumption.”
Session chair Gilberto Morgan, MD, medical oncologist, Skåne University Hospital, Lund, Sweden, agreed.
Dr. Morgan noted that healthcare professionals tend to downplay their influence over patients’ drinking habits and often don’t address these behaviors.
But that needs to change.
“We have absolutely no problem asking patients if they take supplements or vitamins or if they’re eating [healthy],” Dr. Morgan said. “So, what is the difference? Why not recommend that they cut down their alcohol intake and leave it up to everybody’s personal choice to do it or not?”
In the session, Dr. Soerjomataram highlighted the global statistics on alcohol use. IARC data show, for instance, that nearly half (46%) of the world’s population consumes alcohol, with rates higher in men (54%) than women (38%).
How much are people drinking?
Globally, on average, the amount comes to about six liters of pure ethanol per year per drinker, or about one wine bottle per week. However, consumption patterns vary widely by country. In France, people consume about 12 liters per year or about two wine bottles per week.
Dr. Soerjomataram stressed the link between alcohol consumption and cancer.
According to IARC data, heavy drinking – defined as more than 60 g/day or about six daily drinks – accounts for 47% of the alcohol-attributable cancers. Risky drinking – between 20 and 60 g/day – accounts for 29%, she explained, while moderate drinking – less than 20 g/day or about two daily drinks – accounts for roughly 14% of cases of alcohol-attributable cancers.
Globally, alcohol intake accounted for 4% of all cancers diagnosed in 2020, according to a 2021 analysis by IARC.
In the United Kingdom alone, “alcohol drinking caused nearly 17,000 cases of cancer in 2020,” Dr. Soerjomataram said, and breast cancer made up almost one in four of those new cases.
In addition to breast cancer, six other cancer types – oral cavity, pharyngeal, laryngeal, esophageal, colorectal, and liver cancer – can be attributed to alcohol consumption, and emerging evidence suggests stomach and pancreatic cancer may be as well.
The good news, said Dr. Soerjomataram, is that long-term trends show declines in alcohol drinking in many countries, including the high wine-producing countries of France and Italy, where large reductions in consumption have been noted since the peak of intake in the 1920s.
“If it’s possible in these countries, I can imagine it’s possible elsewhere,” said Dr. Soerjomataram.
Dr. Soerjomataram and Dr. Morgan report no relevant financial relationships.
A version of this article first appeared on Medscape.com.
There is an urgent need to raise global awareness about the direct link between alcohol consumption and cancer risk.
That message was delivered by Isabelle Soerjomataram, PhD, with the International Agency for Research on Cancer (IARC), Lyon, France, at a session devoted to alcohol and cancer at the annual meeting of the European Society for Medical Oncology.
Dr. Soerjomataram told the audience. “Health professionals – oncologists, nurses, medical doctors, GPs – have an important role in increasing awareness and bringing this knowledge to people, which may lead to reduced consumption.”
Session chair Gilberto Morgan, MD, medical oncologist, Skåne University Hospital, Lund, Sweden, agreed.
Dr. Morgan noted that healthcare professionals tend to downplay their influence over patients’ drinking habits and often don’t address these behaviors.
But that needs to change.
“We have absolutely no problem asking patients if they take supplements or vitamins or if they’re eating [healthy],” Dr. Morgan said. “So, what is the difference? Why not recommend that they cut down their alcohol intake and leave it up to everybody’s personal choice to do it or not?”
In the session, Dr. Soerjomataram highlighted the global statistics on alcohol use. IARC data show, for instance, that nearly half (46%) of the world’s population consumes alcohol, with rates higher in men (54%) than women (38%).
How much are people drinking?
Globally, on average, the amount comes to about six liters of pure ethanol per year per drinker, or about one wine bottle per week. However, consumption patterns vary widely by country. In France, people consume about 12 liters per year or about two wine bottles per week.
Dr. Soerjomataram stressed the link between alcohol consumption and cancer.
According to IARC data, heavy drinking – defined as more than 60 g/day or about six daily drinks – accounts for 47% of the alcohol-attributable cancers. Risky drinking – between 20 and 60 g/day – accounts for 29%, she explained, while moderate drinking – less than 20 g/day or about two daily drinks – accounts for roughly 14% of cases of alcohol-attributable cancers.
Globally, alcohol intake accounted for 4% of all cancers diagnosed in 2020, according to a 2021 analysis by IARC.
In the United Kingdom alone, “alcohol drinking caused nearly 17,000 cases of cancer in 2020,” Dr. Soerjomataram said, and breast cancer made up almost one in four of those new cases.
In addition to breast cancer, six other cancer types – oral cavity, pharyngeal, laryngeal, esophageal, colorectal, and liver cancer – can be attributed to alcohol consumption, and emerging evidence suggests stomach and pancreatic cancer may be as well.
The good news, said Dr. Soerjomataram, is that long-term trends show declines in alcohol drinking in many countries, including the high wine-producing countries of France and Italy, where large reductions in consumption have been noted since the peak of intake in the 1920s.
“If it’s possible in these countries, I can imagine it’s possible elsewhere,” said Dr. Soerjomataram.
Dr. Soerjomataram and Dr. Morgan report no relevant financial relationships.
A version of this article first appeared on Medscape.com.
FROM ESMO 2023
AAP: ‘Toddler milk’ unnecessary for most kids
WASHINGTON – These products are not nutritionally complete and are not to be confused with formulas for infants younger than 12 months.
“Toddler drinks do not offer anything nutritionally exceptional,” said George J. Fuchs III, MD, a pediatric gastroenterologist at the University of Kentucky, Lexington, who presented a clinical report on toddler formulas from the American Academy of Pediatrics at the group’s annual meeting. The products are not regulated by the U.S. Food and Drug Administration and should not be given to infants younger than 12 months in place of infant formulas, but murky marketing can leave parents and caregivers confused as to whether these products are essential for good health, Dr. Fuchs said.
Despite the rise in marketing of formulas pitched as toddler milks, growth milks, or transition formulas, among other names, the AAP says these formulas are both unregulated and unnecessary for the vast majority of toddlers because they have adequate diets and do not require supplementation.
Clinicians should understand and explain the distinction between products formulated for infants younger than 12 months and those designed for children aged 12 months or older, Dr. Fuchs added.
Formulas for infants younger than 12 months represent a distinct product category for the FDA and are required to be nutritionally complete for this age, Dr. Fuchs said. Infant formulas sold in the United States must meet nutrition requirements as defined by the Infant Formula Act of 1980 (updated in 1986), and the facilities that manufacture them are regularly inspected by the agency.
In contrast, toddler formulas are not regulated or categorized by the FDA and therefore may vary widely in composition and are not nutritionally complete for any age, he said.
One area of concern is that parents or caregivers misunderstand and give these products to infants younger than 12 months instead of infant formulas, he said.
Also, mass-market toddler formulas are inadequate for children with disease-specific requirements, such as malnutrition, gastrointestinal disorders, metabolic disorders, or food allergies.
Questionable composition, misleading marketing
Toddler formulas are not only unnecessary but could be detrimental to children’s health, Dr. Fuchs said. Some formulas have high sodium content relative to cow’s milk or may be high or low in protein. Other products have added sweeteners, which could contribute to an increased preference for sweetened foods as the children get older, he noted.
However, manufacturers of regulated infant products often market them alongside their infant formula, which can be confusing for parents and caregivers. The products often have similar names, images, slogans, and logos, and may suggest benefits such as immune system support, brain development, and digestive health, he added.
A 2020 survey published in Maternal and Child Nutrition found that 60% of approximately 1,000 caregivers of children aged 12-36 months agreed with the marketing claim that toddler formulas or powdered milks provide nutrition that is not available from other food and drinks, Dr. Fuchs said.
Balanced diet is best for healthy children
For infants younger than 12 months, the AAP recommends that the liquid portion of the diet should come from human milk or a standard infant formula that has been reviewed by the FDA based on the Infant Formula Act, Dr. Fuchs said.
Children aged 12 months or older should receive a varied diet with fortified foods. Formula can safely be used as part of a varied diet; however, it offers no nutritional advantage for most children over a well-balanced diet that includes human milk and/or cow milk, “and should not be promoted as such,” Dr. Fuchs noted.
“The category of these toddler drinks has grown and the landscape has changed quite a bit; we thought it was appropriate that we review this category,” Dr. Fuchs said in an interview.
Dr. Fuchs advised pediatricians in practice to follow the AAP’s guidance for breastfeeding infants if possible and progression to formula as needed for infants up to age 1 year, followed by transition to cow milk (or alternatives for those with cow milk allergies) and the addition of a healthy mixed diet.
Formula choices pose practice challenges
In an interview, Cathy Haut, DNP, CPNP-AC, CPNP-PC, a pediatric nurse practitioner in Rehoboth Beach, Del., pointed out that not only are parents often baffled by formula choices, but many are also hesitant to make a switch to regular milk as children get older because they worry that cow’s milk is inadequate for nutrition or is not as “clean” or “sterile” as formula.
In some cases, parents may have had difficulty in acquiring genuine infant formulas, which were relocated to locked cabinets in stores during recent shortages and began using toddler formulas as an alternative for infants younger than 1 year, she added.
“If breastfeeding is not possible, using approved infant formula is preferred, switching to whole cow milk at 1 year of age,” she said. “Nutritional assessment is an important part of well-child visits, with caregiver counseling regarding importance of intake of variety of fortified foods [that] offer vitamins, calcium, iron and zinc,” Ms. Haut added. Although toddler formulas are safe additions to the diets of most young children older than 1 year, supplementation of specific nutrients such as vitamin D if needed is a more effective option, she said.
“National health studies indicate that U.S. toddlers have nutritional gaps in their diet often related to picky eating,” an Abbott spokesperson said in an interview. “When [toddlers] don’t do well transitioning to table foods or won’t drink milk, our toddler drinks contain many of the complementary nutrients, such as vitamins and minerals, that they may be missing in their diet. Toddler drinks may be an option to help fill nutrient gaps for these children 12-36 months of age. Abbott does not recommend or indicate its toddler drinks for infants under 12 months of age,” according to the company.
Dr. Fuchs had no financial conflicts to disclose. Dr. Haut had no financial conflicts to disclose.
A version of this article first appeared on Medscape.com.
WASHINGTON – These products are not nutritionally complete and are not to be confused with formulas for infants younger than 12 months.
“Toddler drinks do not offer anything nutritionally exceptional,” said George J. Fuchs III, MD, a pediatric gastroenterologist at the University of Kentucky, Lexington, who presented a clinical report on toddler formulas from the American Academy of Pediatrics at the group’s annual meeting. The products are not regulated by the U.S. Food and Drug Administration and should not be given to infants younger than 12 months in place of infant formulas, but murky marketing can leave parents and caregivers confused as to whether these products are essential for good health, Dr. Fuchs said.
Despite the rise in marketing of formulas pitched as toddler milks, growth milks, or transition formulas, among other names, the AAP says these formulas are both unregulated and unnecessary for the vast majority of toddlers because they have adequate diets and do not require supplementation.
Clinicians should understand and explain the distinction between products formulated for infants younger than 12 months and those designed for children aged 12 months or older, Dr. Fuchs added.
Formulas for infants younger than 12 months represent a distinct product category for the FDA and are required to be nutritionally complete for this age, Dr. Fuchs said. Infant formulas sold in the United States must meet nutrition requirements as defined by the Infant Formula Act of 1980 (updated in 1986), and the facilities that manufacture them are regularly inspected by the agency.
In contrast, toddler formulas are not regulated or categorized by the FDA and therefore may vary widely in composition and are not nutritionally complete for any age, he said.
One area of concern is that parents or caregivers misunderstand and give these products to infants younger than 12 months instead of infant formulas, he said.
Also, mass-market toddler formulas are inadequate for children with disease-specific requirements, such as malnutrition, gastrointestinal disorders, metabolic disorders, or food allergies.
Questionable composition, misleading marketing
Toddler formulas are not only unnecessary but could be detrimental to children’s health, Dr. Fuchs said. Some formulas have high sodium content relative to cow’s milk or may be high or low in protein. Other products have added sweeteners, which could contribute to an increased preference for sweetened foods as the children get older, he noted.
However, manufacturers of regulated infant products often market them alongside their infant formula, which can be confusing for parents and caregivers. The products often have similar names, images, slogans, and logos, and may suggest benefits such as immune system support, brain development, and digestive health, he added.
A 2020 survey published in Maternal and Child Nutrition found that 60% of approximately 1,000 caregivers of children aged 12-36 months agreed with the marketing claim that toddler formulas or powdered milks provide nutrition that is not available from other food and drinks, Dr. Fuchs said.
Balanced diet is best for healthy children
For infants younger than 12 months, the AAP recommends that the liquid portion of the diet should come from human milk or a standard infant formula that has been reviewed by the FDA based on the Infant Formula Act, Dr. Fuchs said.
Children aged 12 months or older should receive a varied diet with fortified foods. Formula can safely be used as part of a varied diet; however, it offers no nutritional advantage for most children over a well-balanced diet that includes human milk and/or cow milk, “and should not be promoted as such,” Dr. Fuchs noted.
“The category of these toddler drinks has grown and the landscape has changed quite a bit; we thought it was appropriate that we review this category,” Dr. Fuchs said in an interview.
Dr. Fuchs advised pediatricians in practice to follow the AAP’s guidance for breastfeeding infants if possible and progression to formula as needed for infants up to age 1 year, followed by transition to cow milk (or alternatives for those with cow milk allergies) and the addition of a healthy mixed diet.
Formula choices pose practice challenges
In an interview, Cathy Haut, DNP, CPNP-AC, CPNP-PC, a pediatric nurse practitioner in Rehoboth Beach, Del., pointed out that not only are parents often baffled by formula choices, but many are also hesitant to make a switch to regular milk as children get older because they worry that cow’s milk is inadequate for nutrition or is not as “clean” or “sterile” as formula.
In some cases, parents may have had difficulty in acquiring genuine infant formulas, which were relocated to locked cabinets in stores during recent shortages and began using toddler formulas as an alternative for infants younger than 1 year, she added.
“If breastfeeding is not possible, using approved infant formula is preferred, switching to whole cow milk at 1 year of age,” she said. “Nutritional assessment is an important part of well-child visits, with caregiver counseling regarding importance of intake of variety of fortified foods [that] offer vitamins, calcium, iron and zinc,” Ms. Haut added. Although toddler formulas are safe additions to the diets of most young children older than 1 year, supplementation of specific nutrients such as vitamin D if needed is a more effective option, she said.
“National health studies indicate that U.S. toddlers have nutritional gaps in their diet often related to picky eating,” an Abbott spokesperson said in an interview. “When [toddlers] don’t do well transitioning to table foods or won’t drink milk, our toddler drinks contain many of the complementary nutrients, such as vitamins and minerals, that they may be missing in their diet. Toddler drinks may be an option to help fill nutrient gaps for these children 12-36 months of age. Abbott does not recommend or indicate its toddler drinks for infants under 12 months of age,” according to the company.
Dr. Fuchs had no financial conflicts to disclose. Dr. Haut had no financial conflicts to disclose.
A version of this article first appeared on Medscape.com.
WASHINGTON – These products are not nutritionally complete and are not to be confused with formulas for infants younger than 12 months.
“Toddler drinks do not offer anything nutritionally exceptional,” said George J. Fuchs III, MD, a pediatric gastroenterologist at the University of Kentucky, Lexington, who presented a clinical report on toddler formulas from the American Academy of Pediatrics at the group’s annual meeting. The products are not regulated by the U.S. Food and Drug Administration and should not be given to infants younger than 12 months in place of infant formulas, but murky marketing can leave parents and caregivers confused as to whether these products are essential for good health, Dr. Fuchs said.
Despite the rise in marketing of formulas pitched as toddler milks, growth milks, or transition formulas, among other names, the AAP says these formulas are both unregulated and unnecessary for the vast majority of toddlers because they have adequate diets and do not require supplementation.
Clinicians should understand and explain the distinction between products formulated for infants younger than 12 months and those designed for children aged 12 months or older, Dr. Fuchs added.
Formulas for infants younger than 12 months represent a distinct product category for the FDA and are required to be nutritionally complete for this age, Dr. Fuchs said. Infant formulas sold in the United States must meet nutrition requirements as defined by the Infant Formula Act of 1980 (updated in 1986), and the facilities that manufacture them are regularly inspected by the agency.
In contrast, toddler formulas are not regulated or categorized by the FDA and therefore may vary widely in composition and are not nutritionally complete for any age, he said.
One area of concern is that parents or caregivers misunderstand and give these products to infants younger than 12 months instead of infant formulas, he said.
Also, mass-market toddler formulas are inadequate for children with disease-specific requirements, such as malnutrition, gastrointestinal disorders, metabolic disorders, or food allergies.
Questionable composition, misleading marketing
Toddler formulas are not only unnecessary but could be detrimental to children’s health, Dr. Fuchs said. Some formulas have high sodium content relative to cow’s milk or may be high or low in protein. Other products have added sweeteners, which could contribute to an increased preference for sweetened foods as the children get older, he noted.
However, manufacturers of regulated infant products often market them alongside their infant formula, which can be confusing for parents and caregivers. The products often have similar names, images, slogans, and logos, and may suggest benefits such as immune system support, brain development, and digestive health, he added.
A 2020 survey published in Maternal and Child Nutrition found that 60% of approximately 1,000 caregivers of children aged 12-36 months agreed with the marketing claim that toddler formulas or powdered milks provide nutrition that is not available from other food and drinks, Dr. Fuchs said.
Balanced diet is best for healthy children
For infants younger than 12 months, the AAP recommends that the liquid portion of the diet should come from human milk or a standard infant formula that has been reviewed by the FDA based on the Infant Formula Act, Dr. Fuchs said.
Children aged 12 months or older should receive a varied diet with fortified foods. Formula can safely be used as part of a varied diet; however, it offers no nutritional advantage for most children over a well-balanced diet that includes human milk and/or cow milk, “and should not be promoted as such,” Dr. Fuchs noted.
“The category of these toddler drinks has grown and the landscape has changed quite a bit; we thought it was appropriate that we review this category,” Dr. Fuchs said in an interview.
Dr. Fuchs advised pediatricians in practice to follow the AAP’s guidance for breastfeeding infants if possible and progression to formula as needed for infants up to age 1 year, followed by transition to cow milk (or alternatives for those with cow milk allergies) and the addition of a healthy mixed diet.
Formula choices pose practice challenges
In an interview, Cathy Haut, DNP, CPNP-AC, CPNP-PC, a pediatric nurse practitioner in Rehoboth Beach, Del., pointed out that not only are parents often baffled by formula choices, but many are also hesitant to make a switch to regular milk as children get older because they worry that cow’s milk is inadequate for nutrition or is not as “clean” or “sterile” as formula.
In some cases, parents may have had difficulty in acquiring genuine infant formulas, which were relocated to locked cabinets in stores during recent shortages and began using toddler formulas as an alternative for infants younger than 1 year, she added.
“If breastfeeding is not possible, using approved infant formula is preferred, switching to whole cow milk at 1 year of age,” she said. “Nutritional assessment is an important part of well-child visits, with caregiver counseling regarding importance of intake of variety of fortified foods [that] offer vitamins, calcium, iron and zinc,” Ms. Haut added. Although toddler formulas are safe additions to the diets of most young children older than 1 year, supplementation of specific nutrients such as vitamin D if needed is a more effective option, she said.
“National health studies indicate that U.S. toddlers have nutritional gaps in their diet often related to picky eating,” an Abbott spokesperson said in an interview. “When [toddlers] don’t do well transitioning to table foods or won’t drink milk, our toddler drinks contain many of the complementary nutrients, such as vitamins and minerals, that they may be missing in their diet. Toddler drinks may be an option to help fill nutrient gaps for these children 12-36 months of age. Abbott does not recommend or indicate its toddler drinks for infants under 12 months of age,” according to the company.
Dr. Fuchs had no financial conflicts to disclose. Dr. Haut had no financial conflicts to disclose.
A version of this article first appeared on Medscape.com.
AT AAP 2023
Is ChatGPT smarter than a PCP?
GLASGOW –
ChatGPT also provided novel explanations – it frequently “hallucinates” – by describing inaccurate information as if they were facts, according to Shathar Mahmood, BA, a fifth-year medical student at the University of Cambridge, England, who presented the findings at the annual meeting of the Royal College of General Practitioners. The study was published in JMIR Medical Education earlier this year.
“Artificial intelligence has generated impressive results across medicine, and with the release of ChatGPT there is now discussion about these large language models taking over clinicians’ jobs,” Arun James Thirunavukarasu, MB BChir, of the University of Oxford, England, and Oxford University Hospitals NHS Foundation Trust, who is the lead author of the study, told this news organization.
Performance of AI on medical school examinations has prompted much of this discussion, often because performance does not reflect real-world clinical practice, he said. “We used the Applied Knowledge Test instead, and this allowed us to explore the potential and pitfalls of deploying large language models in primary care and to explore what further development of medical large language model applications is required.”
The researchers investigated the strengths and weaknesses of ChatGPT in primary care using the Membership of the Royal College of General Practitioners Applied Knowledge Test. The computer-based, multiple-choice assessment is part of the U.K.’s specialty training to become a general practitioner (GP). It tests knowledge behind general practice within the context of the United Kingdom’s National Health Service.
The researchers entered a series of 674 questions into ChatGPT on two occasions, or “runs.” “By putting the questions into two separate dialogues, we hoped to avoid the influence of one dialogue on the other,” Ms. Mahmood said. To validate that the answers were correct, the ChatGPT responses were compared with the answers provided by the GP self-test and past articles.
Docs 1, AI 0
Overall performance of the algorithm was good across both runs (59.94% and 60.39%); 83.23% of questions produced the same answer on both runs.
But 17% of the answers didn’t match, Ms. Mahmood reported, a statistically significant difference. “And the overall performance of ChatGPT was 10% lower than the average RCGP pass mark in the last few years, which informs one of our conclusions about it not being very precise at expert level recall and decision-making,” she said.
Also, a small percentage of questions (1.48% and 2.25% in each run) produced an uncertain answer or there was no answer.
Say what?
Novel explanations were generated upon running a question through ChatGPT that then provided an extended answer, Ms. Mahmood said. When the accuracy of the extended answers was checked against the correct answers, no correlation was found. “ChatGPT can hallucinate answers, and there’s no way a nonexpert reading this could know it is incorrect,” she said.
Regarding the application of ChatGPT and similar algorithms to clinical practice, Ms. Mahmood was clear. “As they stand, [AI systems] will not be able to replace the health care professional workforce, in primary care at least,” she said. “I think larger and more medically specific datasets are required to improve their outputs in this field.”
Sandip Pramanik, MBcHB, a GP in Watford, Hertfordshire, England, said the study “clearly showed ChatGPT’s struggle to deal with the complexity of the exam questions that is based on the primary care system. In essence, this in indicative of the human factors involved in decision-making in primary care.”
The applied knowledge test is designed to test the knowledge required to be a generalist in the primary care setting, and as such, there are lots of nuances reflecting this within the questions, Dr. Pramanik said.
“ChatGPT may look at these in a more black and white way, whereas the generalist needs to be reflective of the complexities involved and the different possibilities that can present rather than take a binary ‘yes’ or ‘no’ stance,” he said. “In fact, this highlights a lot about the nature of general practice in managing uncertainty, and this is reflected in the questions asked in the exam,” he remarked. He noted, “Being a generalist is about factoring in human emotion and human perception as well as knowledge.”
Ms. Mahmood, Dr. Thirunavukarasu, and Dr. Pramanik have disclosed no relevant financial relationships.
A version of this article first appeared on Medscape.com.
GLASGOW –
ChatGPT also provided novel explanations – it frequently “hallucinates” – by describing inaccurate information as if they were facts, according to Shathar Mahmood, BA, a fifth-year medical student at the University of Cambridge, England, who presented the findings at the annual meeting of the Royal College of General Practitioners. The study was published in JMIR Medical Education earlier this year.
“Artificial intelligence has generated impressive results across medicine, and with the release of ChatGPT there is now discussion about these large language models taking over clinicians’ jobs,” Arun James Thirunavukarasu, MB BChir, of the University of Oxford, England, and Oxford University Hospitals NHS Foundation Trust, who is the lead author of the study, told this news organization.
Performance of AI on medical school examinations has prompted much of this discussion, often because performance does not reflect real-world clinical practice, he said. “We used the Applied Knowledge Test instead, and this allowed us to explore the potential and pitfalls of deploying large language models in primary care and to explore what further development of medical large language model applications is required.”
The researchers investigated the strengths and weaknesses of ChatGPT in primary care using the Membership of the Royal College of General Practitioners Applied Knowledge Test. The computer-based, multiple-choice assessment is part of the U.K.’s specialty training to become a general practitioner (GP). It tests knowledge behind general practice within the context of the United Kingdom’s National Health Service.
The researchers entered a series of 674 questions into ChatGPT on two occasions, or “runs.” “By putting the questions into two separate dialogues, we hoped to avoid the influence of one dialogue on the other,” Ms. Mahmood said. To validate that the answers were correct, the ChatGPT responses were compared with the answers provided by the GP self-test and past articles.
Docs 1, AI 0
Overall performance of the algorithm was good across both runs (59.94% and 60.39%); 83.23% of questions produced the same answer on both runs.
But 17% of the answers didn’t match, Ms. Mahmood reported, a statistically significant difference. “And the overall performance of ChatGPT was 10% lower than the average RCGP pass mark in the last few years, which informs one of our conclusions about it not being very precise at expert level recall and decision-making,” she said.
Also, a small percentage of questions (1.48% and 2.25% in each run) produced an uncertain answer or there was no answer.
Say what?
Novel explanations were generated upon running a question through ChatGPT that then provided an extended answer, Ms. Mahmood said. When the accuracy of the extended answers was checked against the correct answers, no correlation was found. “ChatGPT can hallucinate answers, and there’s no way a nonexpert reading this could know it is incorrect,” she said.
Regarding the application of ChatGPT and similar algorithms to clinical practice, Ms. Mahmood was clear. “As they stand, [AI systems] will not be able to replace the health care professional workforce, in primary care at least,” she said. “I think larger and more medically specific datasets are required to improve their outputs in this field.”
Sandip Pramanik, MBcHB, a GP in Watford, Hertfordshire, England, said the study “clearly showed ChatGPT’s struggle to deal with the complexity of the exam questions that is based on the primary care system. In essence, this in indicative of the human factors involved in decision-making in primary care.”
The applied knowledge test is designed to test the knowledge required to be a generalist in the primary care setting, and as such, there are lots of nuances reflecting this within the questions, Dr. Pramanik said.
“ChatGPT may look at these in a more black and white way, whereas the generalist needs to be reflective of the complexities involved and the different possibilities that can present rather than take a binary ‘yes’ or ‘no’ stance,” he said. “In fact, this highlights a lot about the nature of general practice in managing uncertainty, and this is reflected in the questions asked in the exam,” he remarked. He noted, “Being a generalist is about factoring in human emotion and human perception as well as knowledge.”
Ms. Mahmood, Dr. Thirunavukarasu, and Dr. Pramanik have disclosed no relevant financial relationships.
A version of this article first appeared on Medscape.com.
GLASGOW –
ChatGPT also provided novel explanations – it frequently “hallucinates” – by describing inaccurate information as if they were facts, according to Shathar Mahmood, BA, a fifth-year medical student at the University of Cambridge, England, who presented the findings at the annual meeting of the Royal College of General Practitioners. The study was published in JMIR Medical Education earlier this year.
“Artificial intelligence has generated impressive results across medicine, and with the release of ChatGPT there is now discussion about these large language models taking over clinicians’ jobs,” Arun James Thirunavukarasu, MB BChir, of the University of Oxford, England, and Oxford University Hospitals NHS Foundation Trust, who is the lead author of the study, told this news organization.
Performance of AI on medical school examinations has prompted much of this discussion, often because performance does not reflect real-world clinical practice, he said. “We used the Applied Knowledge Test instead, and this allowed us to explore the potential and pitfalls of deploying large language models in primary care and to explore what further development of medical large language model applications is required.”
The researchers investigated the strengths and weaknesses of ChatGPT in primary care using the Membership of the Royal College of General Practitioners Applied Knowledge Test. The computer-based, multiple-choice assessment is part of the U.K.’s specialty training to become a general practitioner (GP). It tests knowledge behind general practice within the context of the United Kingdom’s National Health Service.
The researchers entered a series of 674 questions into ChatGPT on two occasions, or “runs.” “By putting the questions into two separate dialogues, we hoped to avoid the influence of one dialogue on the other,” Ms. Mahmood said. To validate that the answers were correct, the ChatGPT responses were compared with the answers provided by the GP self-test and past articles.
Docs 1, AI 0
Overall performance of the algorithm was good across both runs (59.94% and 60.39%); 83.23% of questions produced the same answer on both runs.
But 17% of the answers didn’t match, Ms. Mahmood reported, a statistically significant difference. “And the overall performance of ChatGPT was 10% lower than the average RCGP pass mark in the last few years, which informs one of our conclusions about it not being very precise at expert level recall and decision-making,” she said.
Also, a small percentage of questions (1.48% and 2.25% in each run) produced an uncertain answer or there was no answer.
Say what?
Novel explanations were generated upon running a question through ChatGPT that then provided an extended answer, Ms. Mahmood said. When the accuracy of the extended answers was checked against the correct answers, no correlation was found. “ChatGPT can hallucinate answers, and there’s no way a nonexpert reading this could know it is incorrect,” she said.
Regarding the application of ChatGPT and similar algorithms to clinical practice, Ms. Mahmood was clear. “As they stand, [AI systems] will not be able to replace the health care professional workforce, in primary care at least,” she said. “I think larger and more medically specific datasets are required to improve their outputs in this field.”
Sandip Pramanik, MBcHB, a GP in Watford, Hertfordshire, England, said the study “clearly showed ChatGPT’s struggle to deal with the complexity of the exam questions that is based on the primary care system. In essence, this in indicative of the human factors involved in decision-making in primary care.”
The applied knowledge test is designed to test the knowledge required to be a generalist in the primary care setting, and as such, there are lots of nuances reflecting this within the questions, Dr. Pramanik said.
“ChatGPT may look at these in a more black and white way, whereas the generalist needs to be reflective of the complexities involved and the different possibilities that can present rather than take a binary ‘yes’ or ‘no’ stance,” he said. “In fact, this highlights a lot about the nature of general practice in managing uncertainty, and this is reflected in the questions asked in the exam,” he remarked. He noted, “Being a generalist is about factoring in human emotion and human perception as well as knowledge.”
Ms. Mahmood, Dr. Thirunavukarasu, and Dr. Pramanik have disclosed no relevant financial relationships.
A version of this article first appeared on Medscape.com.
AT RCGP 2023
FDA proposes ban on hair straightener ingredients
The
The proposal specifies that formaldehyde would be banned, as well as other chemicals that release formaldehyde, such as methylene glycol. Using hair smoothing products containing formaldehyde and formaldehyde-releasing chemicals “is linked to short-term adverse health effects, such as sensitization reactions and breathing problems, and long-term adverse health effects, including an increased risk of certain cancers,” the proposal states.
One study published last year showed that repeated use of hair straightening products, also called relaxers, could more than double the risk of uterine cancer. Although that study didn’t find that the uterine cancer risk varied based on a person’s race, the researchers noted that women who are Black are among the most likely to use the products and tend to start using them at younger ages, compared with people of other races and ethnicities.
Hair straightening products have also been linked to elevated risks of hormone-sensitive cancers, such as breast cancer and ovarian cancer.
Rep. Ayanna Pressley (D-Mass.) and Rep. Shontel Brown (D-Ohio) applauded the proposed rule in a statement issued jointly on Oct. 6. “The FDA’s proposal to ban these harmful chemicals in hair straighteners and relaxers is a win for public health – especially the health of Black women who are disproportionately put at risk by these products as a result of systemic racism and anti–Black hair sentiment,” Rep. Pressley said The two congresswomen wrote a letter to the FDA earlier this year requesting the topic be investigated.
“Regardless of how we wear our hair, we should be allowed to show up in the world without putting our health at risk. I applaud the FDA for being responsive to our calls and advancing a rule that will help prevent manufacturers from making a profit at the expense of our health,” Rep. Pressley said in the statement. “The administration should finalize this rule without delay.”
A version of this article appeared on WebMD.com
The
The proposal specifies that formaldehyde would be banned, as well as other chemicals that release formaldehyde, such as methylene glycol. Using hair smoothing products containing formaldehyde and formaldehyde-releasing chemicals “is linked to short-term adverse health effects, such as sensitization reactions and breathing problems, and long-term adverse health effects, including an increased risk of certain cancers,” the proposal states.
One study published last year showed that repeated use of hair straightening products, also called relaxers, could more than double the risk of uterine cancer. Although that study didn’t find that the uterine cancer risk varied based on a person’s race, the researchers noted that women who are Black are among the most likely to use the products and tend to start using them at younger ages, compared with people of other races and ethnicities.
Hair straightening products have also been linked to elevated risks of hormone-sensitive cancers, such as breast cancer and ovarian cancer.
Rep. Ayanna Pressley (D-Mass.) and Rep. Shontel Brown (D-Ohio) applauded the proposed rule in a statement issued jointly on Oct. 6. “The FDA’s proposal to ban these harmful chemicals in hair straighteners and relaxers is a win for public health – especially the health of Black women who are disproportionately put at risk by these products as a result of systemic racism and anti–Black hair sentiment,” Rep. Pressley said The two congresswomen wrote a letter to the FDA earlier this year requesting the topic be investigated.
“Regardless of how we wear our hair, we should be allowed to show up in the world without putting our health at risk. I applaud the FDA for being responsive to our calls and advancing a rule that will help prevent manufacturers from making a profit at the expense of our health,” Rep. Pressley said in the statement. “The administration should finalize this rule without delay.”
A version of this article appeared on WebMD.com
The
The proposal specifies that formaldehyde would be banned, as well as other chemicals that release formaldehyde, such as methylene glycol. Using hair smoothing products containing formaldehyde and formaldehyde-releasing chemicals “is linked to short-term adverse health effects, such as sensitization reactions and breathing problems, and long-term adverse health effects, including an increased risk of certain cancers,” the proposal states.
One study published last year showed that repeated use of hair straightening products, also called relaxers, could more than double the risk of uterine cancer. Although that study didn’t find that the uterine cancer risk varied based on a person’s race, the researchers noted that women who are Black are among the most likely to use the products and tend to start using them at younger ages, compared with people of other races and ethnicities.
Hair straightening products have also been linked to elevated risks of hormone-sensitive cancers, such as breast cancer and ovarian cancer.
Rep. Ayanna Pressley (D-Mass.) and Rep. Shontel Brown (D-Ohio) applauded the proposed rule in a statement issued jointly on Oct. 6. “The FDA’s proposal to ban these harmful chemicals in hair straighteners and relaxers is a win for public health – especially the health of Black women who are disproportionately put at risk by these products as a result of systemic racism and anti–Black hair sentiment,” Rep. Pressley said The two congresswomen wrote a letter to the FDA earlier this year requesting the topic be investigated.
“Regardless of how we wear our hair, we should be allowed to show up in the world without putting our health at risk. I applaud the FDA for being responsive to our calls and advancing a rule that will help prevent manufacturers from making a profit at the expense of our health,” Rep. Pressley said in the statement. “The administration should finalize this rule without delay.”
A version of this article appeared on WebMD.com
Why legal pot makes this physician sick
Last year, my husband and I took a 16-day road trip from Kentucky through Massachusetts to Maine. On our first morning in Boston, we exited the Park Street Station en route to Boston Common, but instead of being greeted by the aroma of molasses, we were hit full-on with a pungent, repulsive odor. “That’s skunk weed,” my husband chuckled as we stepped right into the middle of the Boston Freedom Rally, a celebration of all things cannabis.
As we boarded a hop-on-hop-off bus, we learned that this was the one week of the year that the city skips testing tour bus drivers for tetrahydrocannabinol (THC), “because we all test positive,” the driver quipped. As our open-air bus circled the Common, a crowd of pot enthusiasts displayed signs in support of relaxed regulation for public consumption.
The 34-year-old Boston Freedom Rally is a sign that U.S. culture has transformed forever. Mary Jane is no friend of emergency physicians nor of staff on hospital wards and offices.
Toking boomers and millennials
Researchers at the University of California, San Diego, looked at cannabis-related emergency department visits from all acute-care hospitals in the state from 2005 to 2019 and found an 1,808% increase in patients aged 65 or older (that is not a typo) who were there for complications from cannabis use.
The lead author said in an interview that, “older patients taking marijuana or related products may have dizziness and falls, heart palpitations, panic attacks, confusion, anxiety or worsening of underlying lung diseases, such as asthma or [chronic obstructive pulmonary disease].”
A recent study from Canada suggests that commercialization has been associated with an increase in related hospitalizations, including cannabis-induced psychosis.
According to a National Study of Drug Use and Health, marijuana use in young adults reached an all-time high (pun intended) in 2021. Nearly 10% of eighth graders and 20% of 10th graders reported using marijuana this past year.
The full downside of any drug, legal or illegal, is largely unknown until it infiltrates the mainstream market, but these are the typical cases we see:
Let’s start with the demotivated high school honors student who dropped out of college to work at the local cinema. He stumbled and broke his clavicle outside a bar at 2 AM, but he wasn’t sure if he passed out, so a cardiology consult was requested to “rule out” arrhythmia associated with syncope. He related that his plan to become a railway conductor had been upended because he knew he would be drug tested and just couldn’t give up pot. After a normal cardiac exam, ECG, labs, a Holter, and an echocardiogram were also requested and normal at a significant cost.
Cannabinoid hyperemesis syndrome
One of my Midwest colleagues related her encounter with two middle-aged pot users with ventricular tachycardia (VT). These episodes coincided with potassium levels less than 3.0 mEq/L in the setting of repetitive vomiting. The QTc interval didn’t normalize despite a corrected potassium level in one patient. They were both informed that they should never smoke pot because vomiting would predictably drop their K+ levels again and prolong their QTc intervals. Then began “the circular argument,” as my friend described it. The patient claims, “I smoke pot to relieve my nausea,” to which she explains that “in many folks, pot use induces nausea.” Of course, the classic reply is, “Not me.” Predictably one of these stoners soon returned with more VT, more puking, and more hypokalemia. “Consider yourself ‘allergic’ to pot smoke,” my friend advised, but “was met with no meaningful hint of understanding or hope for transformative change,” she told me.
I’ve seen cannabinoid hyperemesis syndrome several times in the past few years. It occurs in daily to weekly pot users. Very rarely, it can cause cerebral edema, but it is also associated with seizures and dehydration that can lead to hypovolemic shock and kidney failure.
Heart and brain harm
Then there are the young patients who for various reasons have developed heart failure. Unfortunately, some are repetitively tox screen positive with varying trifectas of methamphetamine (meth), cocaine, and THC; opiates, meth, and THC; alcohol, meth, and THC; or heroin, meth, and THC. THC, the ever present and essential third leg of the stool of stupor. These unfortunate patients often need heart failure medications that they can’t afford or won’t take because illicit drug use is expensive and dulls their ability to prioritize their health. Some desperately need a heart transplant, but the necessary negative drug screen is a pipe dream.
And it’s not just the heart that is affected. There are data linking cannabis use to a higher risk for both ischemic and hemorrhagic stroke. A retrospective study published in Stroke, of more than 1,000 people diagnosed with an aneurysmal subarachnoid hemorrhage, found that more than half of the 46 who tested positive for THC at admission developed delayed cerebral ischemia (DCI), which increases the risk for disability or early death. This was after adjusting for several patient characteristics as well as recent exposure to other illicit substances; cocaine, meth, and tobacco use were not associated with DCI.
Natural my ...
I’m certain my anti-cannabis stance will strike a nerve with those who love their recreational THC and push for its legal sale; after all, “It’s perfectly natural.” But I counter with the fact that tornadoes, earthquakes, cyanide, and appendicitis are all natural but certainly not optimal. And what we are seeing in the vascular specialties is completely unnatural. We are treating a different mix of complications than before pot was readily accessible across several states.
Our most effective action is to educate our patients. We should encourage those who don’t currently smoke cannabis to never start and those who do to quit. People who require marijuana for improved quality of life for terminal care or true (not supposed) disorders that mainstream medicine fails should be approached with empathy and caution.
A good rule of thumb is to never breathe anything you can see. Never put anything in your body that comes off the street: Drug dealers who sell cannabis cut with fentanyl will be ecstatic to take someone’s money then merely keep scrolling when their obituary comes up.
Let’s try to reverse the rise of vascular complications, orthopedic injuries, and vomiting across America. We can start by encouraging our patients to avoid “skunk weed” and get back to the sweet smells of nature in our cities and parks.
Some details have been changed to protect the patients’ identities, but the essence of their diagnoses has been preserved.
Dr. Walton-Shirley is a retired clinical cardiologist from Nashville, Tenn. She disclosed no relevant conflicts of interest.
A version of this article first appeared on Medscape.com.
Last year, my husband and I took a 16-day road trip from Kentucky through Massachusetts to Maine. On our first morning in Boston, we exited the Park Street Station en route to Boston Common, but instead of being greeted by the aroma of molasses, we were hit full-on with a pungent, repulsive odor. “That’s skunk weed,” my husband chuckled as we stepped right into the middle of the Boston Freedom Rally, a celebration of all things cannabis.
As we boarded a hop-on-hop-off bus, we learned that this was the one week of the year that the city skips testing tour bus drivers for tetrahydrocannabinol (THC), “because we all test positive,” the driver quipped. As our open-air bus circled the Common, a crowd of pot enthusiasts displayed signs in support of relaxed regulation for public consumption.
The 34-year-old Boston Freedom Rally is a sign that U.S. culture has transformed forever. Mary Jane is no friend of emergency physicians nor of staff on hospital wards and offices.
Toking boomers and millennials
Researchers at the University of California, San Diego, looked at cannabis-related emergency department visits from all acute-care hospitals in the state from 2005 to 2019 and found an 1,808% increase in patients aged 65 or older (that is not a typo) who were there for complications from cannabis use.
The lead author said in an interview that, “older patients taking marijuana or related products may have dizziness and falls, heart palpitations, panic attacks, confusion, anxiety or worsening of underlying lung diseases, such as asthma or [chronic obstructive pulmonary disease].”
A recent study from Canada suggests that commercialization has been associated with an increase in related hospitalizations, including cannabis-induced psychosis.
According to a National Study of Drug Use and Health, marijuana use in young adults reached an all-time high (pun intended) in 2021. Nearly 10% of eighth graders and 20% of 10th graders reported using marijuana this past year.
The full downside of any drug, legal or illegal, is largely unknown until it infiltrates the mainstream market, but these are the typical cases we see:
Let’s start with the demotivated high school honors student who dropped out of college to work at the local cinema. He stumbled and broke his clavicle outside a bar at 2 AM, but he wasn’t sure if he passed out, so a cardiology consult was requested to “rule out” arrhythmia associated with syncope. He related that his plan to become a railway conductor had been upended because he knew he would be drug tested and just couldn’t give up pot. After a normal cardiac exam, ECG, labs, a Holter, and an echocardiogram were also requested and normal at a significant cost.
Cannabinoid hyperemesis syndrome
One of my Midwest colleagues related her encounter with two middle-aged pot users with ventricular tachycardia (VT). These episodes coincided with potassium levels less than 3.0 mEq/L in the setting of repetitive vomiting. The QTc interval didn’t normalize despite a corrected potassium level in one patient. They were both informed that they should never smoke pot because vomiting would predictably drop their K+ levels again and prolong their QTc intervals. Then began “the circular argument,” as my friend described it. The patient claims, “I smoke pot to relieve my nausea,” to which she explains that “in many folks, pot use induces nausea.” Of course, the classic reply is, “Not me.” Predictably one of these stoners soon returned with more VT, more puking, and more hypokalemia. “Consider yourself ‘allergic’ to pot smoke,” my friend advised, but “was met with no meaningful hint of understanding or hope for transformative change,” she told me.
I’ve seen cannabinoid hyperemesis syndrome several times in the past few years. It occurs in daily to weekly pot users. Very rarely, it can cause cerebral edema, but it is also associated with seizures and dehydration that can lead to hypovolemic shock and kidney failure.
Heart and brain harm
Then there are the young patients who for various reasons have developed heart failure. Unfortunately, some are repetitively tox screen positive with varying trifectas of methamphetamine (meth), cocaine, and THC; opiates, meth, and THC; alcohol, meth, and THC; or heroin, meth, and THC. THC, the ever present and essential third leg of the stool of stupor. These unfortunate patients often need heart failure medications that they can’t afford or won’t take because illicit drug use is expensive and dulls their ability to prioritize their health. Some desperately need a heart transplant, but the necessary negative drug screen is a pipe dream.
And it’s not just the heart that is affected. There are data linking cannabis use to a higher risk for both ischemic and hemorrhagic stroke. A retrospective study published in Stroke, of more than 1,000 people diagnosed with an aneurysmal subarachnoid hemorrhage, found that more than half of the 46 who tested positive for THC at admission developed delayed cerebral ischemia (DCI), which increases the risk for disability or early death. This was after adjusting for several patient characteristics as well as recent exposure to other illicit substances; cocaine, meth, and tobacco use were not associated with DCI.
Natural my ...
I’m certain my anti-cannabis stance will strike a nerve with those who love their recreational THC and push for its legal sale; after all, “It’s perfectly natural.” But I counter with the fact that tornadoes, earthquakes, cyanide, and appendicitis are all natural but certainly not optimal. And what we are seeing in the vascular specialties is completely unnatural. We are treating a different mix of complications than before pot was readily accessible across several states.
Our most effective action is to educate our patients. We should encourage those who don’t currently smoke cannabis to never start and those who do to quit. People who require marijuana for improved quality of life for terminal care or true (not supposed) disorders that mainstream medicine fails should be approached with empathy and caution.
A good rule of thumb is to never breathe anything you can see. Never put anything in your body that comes off the street: Drug dealers who sell cannabis cut with fentanyl will be ecstatic to take someone’s money then merely keep scrolling when their obituary comes up.
Let’s try to reverse the rise of vascular complications, orthopedic injuries, and vomiting across America. We can start by encouraging our patients to avoid “skunk weed” and get back to the sweet smells of nature in our cities and parks.
Some details have been changed to protect the patients’ identities, but the essence of their diagnoses has been preserved.
Dr. Walton-Shirley is a retired clinical cardiologist from Nashville, Tenn. She disclosed no relevant conflicts of interest.
A version of this article first appeared on Medscape.com.
Last year, my husband and I took a 16-day road trip from Kentucky through Massachusetts to Maine. On our first morning in Boston, we exited the Park Street Station en route to Boston Common, but instead of being greeted by the aroma of molasses, we were hit full-on with a pungent, repulsive odor. “That’s skunk weed,” my husband chuckled as we stepped right into the middle of the Boston Freedom Rally, a celebration of all things cannabis.
As we boarded a hop-on-hop-off bus, we learned that this was the one week of the year that the city skips testing tour bus drivers for tetrahydrocannabinol (THC), “because we all test positive,” the driver quipped. As our open-air bus circled the Common, a crowd of pot enthusiasts displayed signs in support of relaxed regulation for public consumption.
The 34-year-old Boston Freedom Rally is a sign that U.S. culture has transformed forever. Mary Jane is no friend of emergency physicians nor of staff on hospital wards and offices.
Toking boomers and millennials
Researchers at the University of California, San Diego, looked at cannabis-related emergency department visits from all acute-care hospitals in the state from 2005 to 2019 and found an 1,808% increase in patients aged 65 or older (that is not a typo) who were there for complications from cannabis use.
The lead author said in an interview that, “older patients taking marijuana or related products may have dizziness and falls, heart palpitations, panic attacks, confusion, anxiety or worsening of underlying lung diseases, such as asthma or [chronic obstructive pulmonary disease].”
A recent study from Canada suggests that commercialization has been associated with an increase in related hospitalizations, including cannabis-induced psychosis.
According to a National Study of Drug Use and Health, marijuana use in young adults reached an all-time high (pun intended) in 2021. Nearly 10% of eighth graders and 20% of 10th graders reported using marijuana this past year.
The full downside of any drug, legal or illegal, is largely unknown until it infiltrates the mainstream market, but these are the typical cases we see:
Let’s start with the demotivated high school honors student who dropped out of college to work at the local cinema. He stumbled and broke his clavicle outside a bar at 2 AM, but he wasn’t sure if he passed out, so a cardiology consult was requested to “rule out” arrhythmia associated with syncope. He related that his plan to become a railway conductor had been upended because he knew he would be drug tested and just couldn’t give up pot. After a normal cardiac exam, ECG, labs, a Holter, and an echocardiogram were also requested and normal at a significant cost.
Cannabinoid hyperemesis syndrome
One of my Midwest colleagues related her encounter with two middle-aged pot users with ventricular tachycardia (VT). These episodes coincided with potassium levels less than 3.0 mEq/L in the setting of repetitive vomiting. The QTc interval didn’t normalize despite a corrected potassium level in one patient. They were both informed that they should never smoke pot because vomiting would predictably drop their K+ levels again and prolong their QTc intervals. Then began “the circular argument,” as my friend described it. The patient claims, “I smoke pot to relieve my nausea,” to which she explains that “in many folks, pot use induces nausea.” Of course, the classic reply is, “Not me.” Predictably one of these stoners soon returned with more VT, more puking, and more hypokalemia. “Consider yourself ‘allergic’ to pot smoke,” my friend advised, but “was met with no meaningful hint of understanding or hope for transformative change,” she told me.
I’ve seen cannabinoid hyperemesis syndrome several times in the past few years. It occurs in daily to weekly pot users. Very rarely, it can cause cerebral edema, but it is also associated with seizures and dehydration that can lead to hypovolemic shock and kidney failure.
Heart and brain harm
Then there are the young patients who for various reasons have developed heart failure. Unfortunately, some are repetitively tox screen positive with varying trifectas of methamphetamine (meth), cocaine, and THC; opiates, meth, and THC; alcohol, meth, and THC; or heroin, meth, and THC. THC, the ever present and essential third leg of the stool of stupor. These unfortunate patients often need heart failure medications that they can’t afford or won’t take because illicit drug use is expensive and dulls their ability to prioritize their health. Some desperately need a heart transplant, but the necessary negative drug screen is a pipe dream.
And it’s not just the heart that is affected. There are data linking cannabis use to a higher risk for both ischemic and hemorrhagic stroke. A retrospective study published in Stroke, of more than 1,000 people diagnosed with an aneurysmal subarachnoid hemorrhage, found that more than half of the 46 who tested positive for THC at admission developed delayed cerebral ischemia (DCI), which increases the risk for disability or early death. This was after adjusting for several patient characteristics as well as recent exposure to other illicit substances; cocaine, meth, and tobacco use were not associated with DCI.
Natural my ...
I’m certain my anti-cannabis stance will strike a nerve with those who love their recreational THC and push for its legal sale; after all, “It’s perfectly natural.” But I counter with the fact that tornadoes, earthquakes, cyanide, and appendicitis are all natural but certainly not optimal. And what we are seeing in the vascular specialties is completely unnatural. We are treating a different mix of complications than before pot was readily accessible across several states.
Our most effective action is to educate our patients. We should encourage those who don’t currently smoke cannabis to never start and those who do to quit. People who require marijuana for improved quality of life for terminal care or true (not supposed) disorders that mainstream medicine fails should be approached with empathy and caution.
A good rule of thumb is to never breathe anything you can see. Never put anything in your body that comes off the street: Drug dealers who sell cannabis cut with fentanyl will be ecstatic to take someone’s money then merely keep scrolling when their obituary comes up.
Let’s try to reverse the rise of vascular complications, orthopedic injuries, and vomiting across America. We can start by encouraging our patients to avoid “skunk weed” and get back to the sweet smells of nature in our cities and parks.
Some details have been changed to protect the patients’ identities, but the essence of their diagnoses has been preserved.
Dr. Walton-Shirley is a retired clinical cardiologist from Nashville, Tenn. She disclosed no relevant conflicts of interest.
A version of this article first appeared on Medscape.com.
Artificial intelligence in the office: Part 2
In the year since generative artificial intelligence (AI) software first began to emerge for use, the staggering pace and breadth of development has condensed years of growth and change into months and weeks. Among the settings where these tools may find the greatest straight-line relevance is private medical practice.
. A multitude of generative AI products with potential medical applications are now available, with new ones appearing almost weekly. (As always, I have no financial interest in any product or service mentioned in this column.)

Last month, I discussed ChatGPT, the best-known AI algorithm, and some of its applications in clinical practice, such as generating website, video, and blog content. ChatGPT can also provide rapid and concise answers to general medical questions, like a search engine – but with more natural language processing and contextual understanding. Additionally, the algorithm can draft generic medical documents, including templates for after-visit summaries, postprocedure instructions, referrals, prior authorization appeal letters, and educational handouts.
Another useful feature of ChatGPT is its ability to provide accurate and conversational language translations, thus serving as an interpreter during clinic visits in situations where a human translator is not available. It also has potential uses in clinical research by finding resources, formulating hypotheses, drafting study protocols, and collecting large amounts of data in short periods of time. Other possibilities include survey administration, clinical trial recruitment, and automatic medication monitoring.
GPT-4, the latest version of ChatGPT, is reported to have greater problem-solving abilities and an even broader knowledge base. Among its claimed skills are the ability to find the latest literature in a given area, write a discharge summary for a patient following an uncomplicated surgery, and an image analysis feature to identify objects in photos. GPT-4 has been praised as having “the potential to help drive medical innovation, from aiding with patient discharge notes, summarizing recent clinical trials, providing information on ethical guidelines, and much more.”
Bard, an AI “chat bot” introduced by Google earlier this year, intends to leverage Google’s enormous database to compete with ChatGPT in providing answers to medical questions. Bard also hopes to play a pivotal role in expanding telemedicine and remote care via Google’s secure connections and access to patient records and medical history, and “facilitate seamless communication through appointment scheduling, messaging, and sharing medical images,” according to PackT, a website for IT professionals. The company claims that Bard’s integration of AI and machine learning capabilities will serve to elevate health care efficiency and patient outcomes, PackT says, and “the platform’s AI system quickly and accurately analyzes patient records, identifies patterns and trends, and aids medical professionals in developing effective treatment plans.”
Doximity has introduced an AI engine called DocsGPT, an encrypted, HIPAA-compliant writing assistant that, the company says, can draft any form of professional correspondence, including prior authorization letters, insurance appeals, patient support letters, and patient education materials. The service is available at no charge to all U.S. physicians and medical students through their Doximity accounts.
Microsoft has introduced several AI products. BioGPT is a language model specifically designed for health care. Compared with GPT models that are trained on more general text data, BioGPT is purported to have a deeper understanding of the language used in biomedical research and can generate more accurate and relevant outputs for biomedical tasks, such as drug discovery, disease classification, and clinical decision support. Fabric is another health care–specific data and analytics platform the company described in an announcement in May. It can combine data from sources such as electronic health records, images, lab systems, medical devices, and claims systems so hospitals and offices can standardize it and access it in the same place. Microsoft said the new tools will help eliminate the “time-consuming” process of searching through these sources one by one. Microsoft will also offer a new generative AI chatbot called the Azure Health Bot, which can pull information from a health organization’s own internal data as well as reputable external sources such as the Food and Drug Administration and the National Institutes of Health.
Several other AI products are available for clinicians. Tana served as an administrative aid and a clinical helper during the height of the COVID-19 pandemic, answering frequently asked questions, facilitating appointment management, and gathering preliminary medical information prior to teleconsultations. Dougall GPT is another AI chatbot tailored for health care professionals. It provides clinicians with AI-tuned answers to their queries, augmented by links to relevant, up-to-date, authoritative resources. It also assists in drafting patient instructions, consultation summaries, speeches, and professional correspondence. Wang has created Clinical Camel, an open-source health care–focused chatbot that assembles medical data with a combination of user-shared conversations and synthetic conversations derived from curated clinical articles. The Chinese company Baidu has rolled out Ernie as a potential rival to ChatGPT. You get the idea.
Of course, the inherent drawbacks of AI, such as producing false or biased information, perpetuating harmful stereotypes, and presenting information that has since been proven inaccurate or out-of-date, must always be kept in mind. All AI algorithms have been criticized for giving wrong answers, as their datasets are generally culled from information published in 2021 or earlier. Several of them have been shown to fabricate information – a phenomenon labeled “artificial hallucinations” in one article. “The scientific community must be vigilant in verifying the accuracy and reliability of the information provided by AI tools,” wrote the authors of that paper. “Researchers should use AI as an aid rather than a replacement for critical thinking and fact-checking.”
In the year since generative artificial intelligence (AI) software first began to emerge for use, the staggering pace and breadth of development has condensed years of growth and change into months and weeks. Among the settings where these tools may find the greatest straight-line relevance is private medical practice.
. A multitude of generative AI products with potential medical applications are now available, with new ones appearing almost weekly. (As always, I have no financial interest in any product or service mentioned in this column.)
Last month, I discussed ChatGPT, the best-known AI algorithm, and some of its applications in clinical practice, such as generating website, video, and blog content. ChatGPT can also provide rapid and concise answers to general medical questions, like a search engine – but with more natural language processing and contextual understanding. Additionally, the algorithm can draft generic medical documents, including templates for after-visit summaries, postprocedure instructions, referrals, prior authorization appeal letters, and educational handouts.
Another useful feature of ChatGPT is its ability to provide accurate and conversational language translations, thus serving as an interpreter during clinic visits in situations where a human translator is not available. It also has potential uses in clinical research by finding resources, formulating hypotheses, drafting study protocols, and collecting large amounts of data in short periods of time. Other possibilities include survey administration, clinical trial recruitment, and automatic medication monitoring.
GPT-4, the latest version of ChatGPT, is reported to have greater problem-solving abilities and an even broader knowledge base. Among its claimed skills are the ability to find the latest literature in a given area, write a discharge summary for a patient following an uncomplicated surgery, and an image analysis feature to identify objects in photos. GPT-4 has been praised as having “the potential to help drive medical innovation, from aiding with patient discharge notes, summarizing recent clinical trials, providing information on ethical guidelines, and much more.”
Bard, an AI “chat bot” introduced by Google earlier this year, intends to leverage Google’s enormous database to compete with ChatGPT in providing answers to medical questions. Bard also hopes to play a pivotal role in expanding telemedicine and remote care via Google’s secure connections and access to patient records and medical history, and “facilitate seamless communication through appointment scheduling, messaging, and sharing medical images,” according to PackT, a website for IT professionals. The company claims that Bard’s integration of AI and machine learning capabilities will serve to elevate health care efficiency and patient outcomes, PackT says, and “the platform’s AI system quickly and accurately analyzes patient records, identifies patterns and trends, and aids medical professionals in developing effective treatment plans.”
Doximity has introduced an AI engine called DocsGPT, an encrypted, HIPAA-compliant writing assistant that, the company says, can draft any form of professional correspondence, including prior authorization letters, insurance appeals, patient support letters, and patient education materials. The service is available at no charge to all U.S. physicians and medical students through their Doximity accounts.
Microsoft has introduced several AI products. BioGPT is a language model specifically designed for health care. Compared with GPT models that are trained on more general text data, BioGPT is purported to have a deeper understanding of the language used in biomedical research and can generate more accurate and relevant outputs for biomedical tasks, such as drug discovery, disease classification, and clinical decision support. Fabric is another health care–specific data and analytics platform the company described in an announcement in May. It can combine data from sources such as electronic health records, images, lab systems, medical devices, and claims systems so hospitals and offices can standardize it and access it in the same place. Microsoft said the new tools will help eliminate the “time-consuming” process of searching through these sources one by one. Microsoft will also offer a new generative AI chatbot called the Azure Health Bot, which can pull information from a health organization’s own internal data as well as reputable external sources such as the Food and Drug Administration and the National Institutes of Health.
Several other AI products are available for clinicians. Tana served as an administrative aid and a clinical helper during the height of the COVID-19 pandemic, answering frequently asked questions, facilitating appointment management, and gathering preliminary medical information prior to teleconsultations. Dougall GPT is another AI chatbot tailored for health care professionals. It provides clinicians with AI-tuned answers to their queries, augmented by links to relevant, up-to-date, authoritative resources. It also assists in drafting patient instructions, consultation summaries, speeches, and professional correspondence. Wang has created Clinical Camel, an open-source health care–focused chatbot that assembles medical data with a combination of user-shared conversations and synthetic conversations derived from curated clinical articles. The Chinese company Baidu has rolled out Ernie as a potential rival to ChatGPT. You get the idea.
Of course, the inherent drawbacks of AI, such as producing false or biased information, perpetuating harmful stereotypes, and presenting information that has since been proven inaccurate or out-of-date, must always be kept in mind. All AI algorithms have been criticized for giving wrong answers, as their datasets are generally culled from information published in 2021 or earlier. Several of them have been shown to fabricate information – a phenomenon labeled “artificial hallucinations” in one article. “The scientific community must be vigilant in verifying the accuracy and reliability of the information provided by AI tools,” wrote the authors of that paper. “Researchers should use AI as an aid rather than a replacement for critical thinking and fact-checking.”
In the year since generative artificial intelligence (AI) software first began to emerge for use, the staggering pace and breadth of development has condensed years of growth and change into months and weeks. Among the settings where these tools may find the greatest straight-line relevance is private medical practice.
. A multitude of generative AI products with potential medical applications are now available, with new ones appearing almost weekly. (As always, I have no financial interest in any product or service mentioned in this column.)
Last month, I discussed ChatGPT, the best-known AI algorithm, and some of its applications in clinical practice, such as generating website, video, and blog content. ChatGPT can also provide rapid and concise answers to general medical questions, like a search engine – but with more natural language processing and contextual understanding. Additionally, the algorithm can draft generic medical documents, including templates for after-visit summaries, postprocedure instructions, referrals, prior authorization appeal letters, and educational handouts.
Another useful feature of ChatGPT is its ability to provide accurate and conversational language translations, thus serving as an interpreter during clinic visits in situations where a human translator is not available. It also has potential uses in clinical research by finding resources, formulating hypotheses, drafting study protocols, and collecting large amounts of data in short periods of time. Other possibilities include survey administration, clinical trial recruitment, and automatic medication monitoring.
GPT-4, the latest version of ChatGPT, is reported to have greater problem-solving abilities and an even broader knowledge base. Among its claimed skills are the ability to find the latest literature in a given area, write a discharge summary for a patient following an uncomplicated surgery, and an image analysis feature to identify objects in photos. GPT-4 has been praised as having “the potential to help drive medical innovation, from aiding with patient discharge notes, summarizing recent clinical trials, providing information on ethical guidelines, and much more.”
Bard, an AI “chat bot” introduced by Google earlier this year, intends to leverage Google’s enormous database to compete with ChatGPT in providing answers to medical questions. Bard also hopes to play a pivotal role in expanding telemedicine and remote care via Google’s secure connections and access to patient records and medical history, and “facilitate seamless communication through appointment scheduling, messaging, and sharing medical images,” according to PackT, a website for IT professionals. The company claims that Bard’s integration of AI and machine learning capabilities will serve to elevate health care efficiency and patient outcomes, PackT says, and “the platform’s AI system quickly and accurately analyzes patient records, identifies patterns and trends, and aids medical professionals in developing effective treatment plans.”
Doximity has introduced an AI engine called DocsGPT, an encrypted, HIPAA-compliant writing assistant that, the company says, can draft any form of professional correspondence, including prior authorization letters, insurance appeals, patient support letters, and patient education materials. The service is available at no charge to all U.S. physicians and medical students through their Doximity accounts.
Microsoft has introduced several AI products. BioGPT is a language model specifically designed for health care. Compared with GPT models that are trained on more general text data, BioGPT is purported to have a deeper understanding of the language used in biomedical research and can generate more accurate and relevant outputs for biomedical tasks, such as drug discovery, disease classification, and clinical decision support. Fabric is another health care–specific data and analytics platform the company described in an announcement in May. It can combine data from sources such as electronic health records, images, lab systems, medical devices, and claims systems so hospitals and offices can standardize it and access it in the same place. Microsoft said the new tools will help eliminate the “time-consuming” process of searching through these sources one by one. Microsoft will also offer a new generative AI chatbot called the Azure Health Bot, which can pull information from a health organization’s own internal data as well as reputable external sources such as the Food and Drug Administration and the National Institutes of Health.
Several other AI products are available for clinicians. Tana served as an administrative aid and a clinical helper during the height of the COVID-19 pandemic, answering frequently asked questions, facilitating appointment management, and gathering preliminary medical information prior to teleconsultations. Dougall GPT is another AI chatbot tailored for health care professionals. It provides clinicians with AI-tuned answers to their queries, augmented by links to relevant, up-to-date, authoritative resources. It also assists in drafting patient instructions, consultation summaries, speeches, and professional correspondence. Wang has created Clinical Camel, an open-source health care–focused chatbot that assembles medical data with a combination of user-shared conversations and synthetic conversations derived from curated clinical articles. The Chinese company Baidu has rolled out Ernie as a potential rival to ChatGPT. You get the idea.
Of course, the inherent drawbacks of AI, such as producing false or biased information, perpetuating harmful stereotypes, and presenting information that has since been proven inaccurate or out-of-date, must always be kept in mind. All AI algorithms have been criticized for giving wrong answers, as their datasets are generally culled from information published in 2021 or earlier. Several of them have been shown to fabricate information – a phenomenon labeled “artificial hallucinations” in one article. “The scientific community must be vigilant in verifying the accuracy and reliability of the information provided by AI tools,” wrote the authors of that paper. “Researchers should use AI as an aid rather than a replacement for critical thinking and fact-checking.”

AI chatbot ‘hallucinates’ faulty medical intelligence
Artificial intelligence (AI) models are typically a year out of date and have this “charming problem of hallucinating made-up data and saying it with all the certainty of an attending on rounds,” Isaac Kohane, MD, PhD, Harvard Medical School, Boston, told a packed audience at plenary at an annual scientific meeting on infectious diseases.
Dr. Kohane, chair of the department of biomedical informatics, says the future intersection between AI and health care is “muddy.”
Echoing questions about the accuracy of new AI tools, researchers at the meeting presented the results of their new test of ChatGPT.
To test the accuracy of ChatGPT’s version 3.5, the researchers asked it if there are any boxed warnings on the U.S. Food and Drug Administration’s label for common antibiotics, and if so, what they are.
ChatGPT provided correct answers about FDA boxed warnings for only 12 of the 41 antibiotics queried – a matching rate of just 29%.
For the other 29 antibiotics, ChatGPT either “incorrectly reported that there was an FDA boxed warning when there was not, or inaccurately or incorrectly reported the boxed warning,” Rebecca Linfield, MD, infectious diseases fellow, Stanford (Calif.) University, said in an interview.
Uncritical AI use risky
Nine of the 41 antibiotics included in the query have boxed warnings. And ChatGPT correctly identified all nine, but only three were the matching adverse event (33%). For the 32 antibiotics without an FDA boxed warning, ChatGPT correctly reported that 28% (9 of 32) do not have a boxed warning.
For example, ChatGPT stated that the antibiotic fidaxomicin has a boxed warning for increased risk for Clostridioides difficile, “but it is the first-line antibiotic used to treat C. difficile,” Dr. Linfield pointed out.
ChatGPT also reported that cefepime increased the risk for death in those with pneumonia and fabricated a study supporting that assertion. “However, cefepime is a first-line drug for those with hospital-acquired pneumonia,” Dr. Linfield explained.
“I can imagine a worried family member finding this through ChatGPT, and needing to have extensive reassurances from the patient’s physicians about why this antibiotic was chosen,” she said.
ChatGPT also incorrectly stated that aztreonam has a boxed warning for increased mortality.
“The risk is that both physicians and the public uncritically use ChatGPT as an easily accessible, readable source of clinically validated information, when these large language models are meant to generate fluid text, and not necessarily accurate information,” Dr. Linfield told this news organization.
Dr. Linfield said that the next step is to compare the ChatGPT 3.5 used in this analysis with ChatGPT 4, as well as with Google’s Med-PaLM 2 after it is released to the public.
Advancing fast
At plenary, Dr. Kohane pointed out that AI is a quick learner and improvements in tools are coming fast.
As an example, just 3 years ago, the best AI tool could score about as well as the worst student taking the medical boards, he told the audience. “Three years later, the leading large language models are scoring better than 90% of all the candidates. What’s it going to be doing next year?” he asked.
“I don’t know,” Dr. Kohane said, “but it will be better than this year.” AI will “transform health care.”
A version of this article first appeared on Medscape.com.
Artificial intelligence (AI) models are typically a year out of date and have this “charming problem of hallucinating made-up data and saying it with all the certainty of an attending on rounds,” Isaac Kohane, MD, PhD, Harvard Medical School, Boston, told a packed audience at plenary at an annual scientific meeting on infectious diseases.
Dr. Kohane, chair of the department of biomedical informatics, says the future intersection between AI and health care is “muddy.”
Echoing questions about the accuracy of new AI tools, researchers at the meeting presented the results of their new test of ChatGPT.
To test the accuracy of ChatGPT’s version 3.5, the researchers asked it if there are any boxed warnings on the U.S. Food and Drug Administration’s label for common antibiotics, and if so, what they are.
ChatGPT provided correct answers about FDA boxed warnings for only 12 of the 41 antibiotics queried – a matching rate of just 29%.
For the other 29 antibiotics, ChatGPT either “incorrectly reported that there was an FDA boxed warning when there was not, or inaccurately or incorrectly reported the boxed warning,” Rebecca Linfield, MD, infectious diseases fellow, Stanford (Calif.) University, said in an interview.
Uncritical AI use risky
Nine of the 41 antibiotics included in the query have boxed warnings. And ChatGPT correctly identified all nine, but only three were the matching adverse event (33%). For the 32 antibiotics without an FDA boxed warning, ChatGPT correctly reported that 28% (9 of 32) do not have a boxed warning.
For example, ChatGPT stated that the antibiotic fidaxomicin has a boxed warning for increased risk for Clostridioides difficile, “but it is the first-line antibiotic used to treat C. difficile,” Dr. Linfield pointed out.
ChatGPT also reported that cefepime increased the risk for death in those with pneumonia and fabricated a study supporting that assertion. “However, cefepime is a first-line drug for those with hospital-acquired pneumonia,” Dr. Linfield explained.
“I can imagine a worried family member finding this through ChatGPT, and needing to have extensive reassurances from the patient’s physicians about why this antibiotic was chosen,” she said.
ChatGPT also incorrectly stated that aztreonam has a boxed warning for increased mortality.
“The risk is that both physicians and the public uncritically use ChatGPT as an easily accessible, readable source of clinically validated information, when these large language models are meant to generate fluid text, and not necessarily accurate information,” Dr. Linfield told this news organization.
Dr. Linfield said that the next step is to compare the ChatGPT 3.5 used in this analysis with ChatGPT 4, as well as with Google’s Med-PaLM 2 after it is released to the public.
Advancing fast
At plenary, Dr. Kohane pointed out that AI is a quick learner and improvements in tools are coming fast.
As an example, just 3 years ago, the best AI tool could score about as well as the worst student taking the medical boards, he told the audience. “Three years later, the leading large language models are scoring better than 90% of all the candidates. What’s it going to be doing next year?” he asked.
“I don’t know,” Dr. Kohane said, “but it will be better than this year.” AI will “transform health care.”
A version of this article first appeared on Medscape.com.
Artificial intelligence (AI) models are typically a year out of date and have this “charming problem of hallucinating made-up data and saying it with all the certainty of an attending on rounds,” Isaac Kohane, MD, PhD, Harvard Medical School, Boston, told a packed audience at plenary at an annual scientific meeting on infectious diseases.
Dr. Kohane, chair of the department of biomedical informatics, says the future intersection between AI and health care is “muddy.”
Echoing questions about the accuracy of new AI tools, researchers at the meeting presented the results of their new test of ChatGPT.
To test the accuracy of ChatGPT’s version 3.5, the researchers asked it if there are any boxed warnings on the U.S. Food and Drug Administration’s label for common antibiotics, and if so, what they are.
ChatGPT provided correct answers about FDA boxed warnings for only 12 of the 41 antibiotics queried – a matching rate of just 29%.
For the other 29 antibiotics, ChatGPT either “incorrectly reported that there was an FDA boxed warning when there was not, or inaccurately or incorrectly reported the boxed warning,” Rebecca Linfield, MD, infectious diseases fellow, Stanford (Calif.) University, said in an interview.
Uncritical AI use risky
Nine of the 41 antibiotics included in the query have boxed warnings. And ChatGPT correctly identified all nine, but only three were the matching adverse event (33%). For the 32 antibiotics without an FDA boxed warning, ChatGPT correctly reported that 28% (9 of 32) do not have a boxed warning.
For example, ChatGPT stated that the antibiotic fidaxomicin has a boxed warning for increased risk for Clostridioides difficile, “but it is the first-line antibiotic used to treat C. difficile,” Dr. Linfield pointed out.
ChatGPT also reported that cefepime increased the risk for death in those with pneumonia and fabricated a study supporting that assertion. “However, cefepime is a first-line drug for those with hospital-acquired pneumonia,” Dr. Linfield explained.
“I can imagine a worried family member finding this through ChatGPT, and needing to have extensive reassurances from the patient’s physicians about why this antibiotic was chosen,” she said.
ChatGPT also incorrectly stated that aztreonam has a boxed warning for increased mortality.
“The risk is that both physicians and the public uncritically use ChatGPT as an easily accessible, readable source of clinically validated information, when these large language models are meant to generate fluid text, and not necessarily accurate information,” Dr. Linfield told this news organization.
Dr. Linfield said that the next step is to compare the ChatGPT 3.5 used in this analysis with ChatGPT 4, as well as with Google’s Med-PaLM 2 after it is released to the public.
Advancing fast
At plenary, Dr. Kohane pointed out that AI is a quick learner and improvements in tools are coming fast.
As an example, just 3 years ago, the best AI tool could score about as well as the worst student taking the medical boards, he told the audience. “Three years later, the leading large language models are scoring better than 90% of all the candidates. What’s it going to be doing next year?” he asked.
“I don’t know,” Dr. Kohane said, “but it will be better than this year.” AI will “transform health care.”
A version of this article first appeared on Medscape.com.
FROM IDWEEK 2023
AI in medicine has a major Cassandra problem
This transcript has been edited for clarity.
Today I’m going to talk to you about a study at the cutting edge of modern medicine, one that uses an artificial intelligence (AI) model to guide care. But before I do, I need to take you back to the late Bronze Age, to a city located on the coast of what is now Turkey.
Troy’s towering walls made it seem unassailable, but that would not stop the Achaeans and their fleet of black ships from making landfall, and, after a siege, destroying the city. The destruction of Troy, as told in the Iliad and the Aeneid, was foretold by Cassandra, the daughter of King Priam and Priestess of Troy.
Cassandra had been given the gift of prophecy by the god Apollo in exchange for her favors. But after the gift was bestowed, she rejected the bright god and, in his rage, he added a curse to her blessing: that no one would ever believe her prophecies.
Thus it was that when her brother Paris set off to Sparta to abduct Helen, she warned him that his actions would lead to the downfall of their great city. He, of course, ignored her.
And you know the rest of the story.
Why am I telling you the story of Cassandra of Troy when we’re supposed to be talking about AI in medicine? Because AI has a major Cassandra problem.
The recent history of AI, and particularly the subset of AI known as machine learning in medicine, has been characterized by an accuracy arms race.
The electronic health record allows for the collection of volumes of data orders of magnitude greater than what we have ever been able to collect before. And all that data can be crunched by various algorithms to make predictions about, well, anything – whether a patient will be transferred to the intensive care unit, whether a GI bleed will need an intervention, whether someone will die in the next year.
Studies in this area tend to rely on retrospective datasets, and as time has gone on, better algorithms and more data have led to better and better predictions. In some simpler cases, machine-learning models have achieved near-perfect accuracy – Cassandra-level accuracy – as in the reading of chest x-rays for pneumonia, for example.
But as Cassandra teaches us, even perfect prediction is useless if no one believes you, if they don’t change their behavior. And this is the central problem of AI in medicine today. Many people are focusing on accuracy of the prediction but have forgotten that high accuracy is just table stakes for an AI model to be useful. It has to not only be accurate, but its use also has to change outcomes for patients. We need to be able to save Troy.
The best way to determine whether an AI model will help patients is to treat a model like we treat a new medication and evaluate it through a randomized trial. That’s what researchers, led by Shannon Walker of Vanderbilt University, Nashville, Tenn., did in a paper appearing in JAMA Network Open.
The model in question was one that predicted venous thromboembolism – blood clots – in hospitalized children. The model took in a variety of data points from the health record: a history of blood clot, history of cancer, presence of a central line, a variety of lab values. And the predictive model was very good – maybe not Cassandra good, but it achieved an AUC of 0.90, which means it had very high accuracy.
But again, accuracy is just table stakes.
The authors deployed the model in the live health record and recorded the results. For half of the kids, that was all that happened; no one actually saw the predictions. For those randomized to the intervention, the hematology team would be notified when the risk for clot was calculated to be greater than 2.5%. The hematology team would then contact the primary team to discuss prophylactic anticoagulation.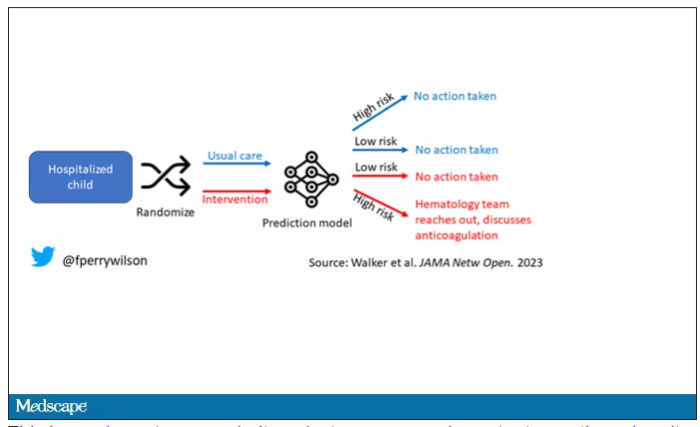
This is an elegant approach.
Let’s start with those table stakes – accuracy. The predictions were, by and large, pretty accurate in this trial. Of the 135 kids who developed blood clots, 121 had been flagged by the model in advance. That’s about 90%. The model flagged about 10% of kids who didn’t get a blood clot as well, but that’s not entirely surprising since the threshold for flagging was a 2.5% risk.
Given that the model preidentified almost every kid who would go on to develop a blood clot, it would make sense that kids randomized to the intervention would do better; after all, Cassandra was calling out her warnings.
But those kids didn’t do better. The rate of blood clot was no different between the group that used the accurate prediction model and the group that did not.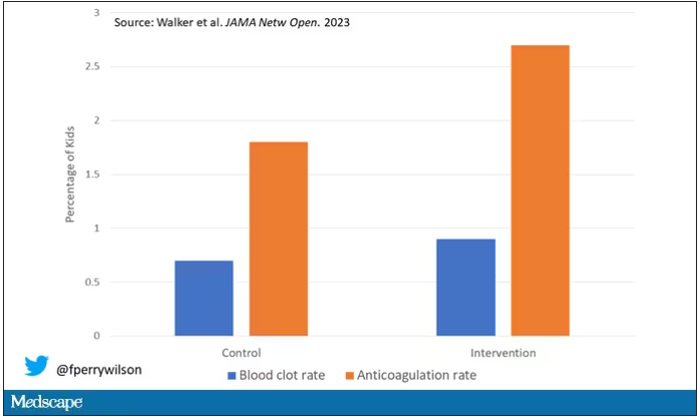
Why? Why does the use of an accurate model not necessarily improve outcomes?
First of all, a warning must lead to some change in management. Indeed, the kids in the intervention group were more likely to receive anticoagulation, but barely so. There were lots of reasons for this: physician preference, imminent discharge, active bleeding, and so on.
But let’s take a look at the 77 kids in the intervention arm who developed blood clots, because I think this is an instructive analysis.
Six of them did not meet the 2.5% threshold criteria, a case where the model missed its mark. Again, accuracy is table stakes.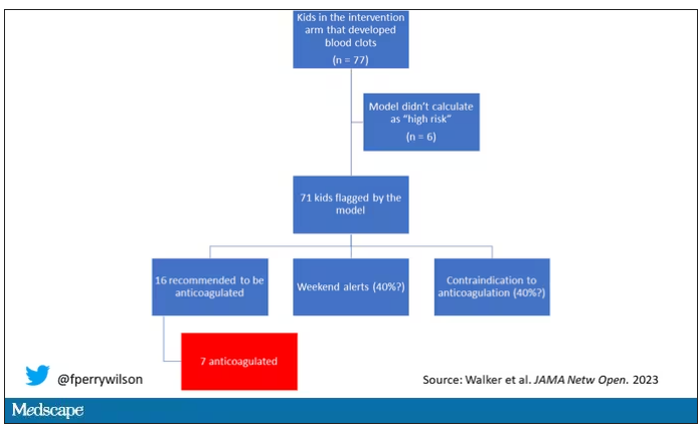
Of the remaining 71, only 16 got a recommendation from the hematologist to start anticoagulation. Why not more? Well, the model identified some of the high-risk kids on the weekend, and it seems that the study team did not contact treatment teams during that time. That may account for about 40% of these cases. The remainder had some contraindication to anticoagulation.
Most tellingly, of the 16 who did get a recommendation to start anticoagulation, the recommendation was followed in only seven patients.
This is the gap between accurate prediction and the ability to change outcomes for patients. A prediction is useless if it is wrong, for sure. But it’s also useless if you don’t tell anyone about it. It’s useless if you tell someone but they can’t do anything about it. And it’s useless if they could do something about it but choose not to.
That’s the gulf that these models need to cross at this point. So, the next time some slick company tells you how accurate their AI model is, ask them if accuracy is really the most important thing. If they say, “Well, yes, of course,” then tell them about Cassandra.
Dr. F. Perry Wilson is associate professor of medicine and public health and director of the Clinical and Translational Research Accelerator at Yale University, New Haven, Conn. He has disclosed no relevant financial relationships.
A version of this article appeared on Medscape.com.
This transcript has been edited for clarity.
Today I’m going to talk to you about a study at the cutting edge of modern medicine, one that uses an artificial intelligence (AI) model to guide care. But before I do, I need to take you back to the late Bronze Age, to a city located on the coast of what is now Turkey.
Troy’s towering walls made it seem unassailable, but that would not stop the Achaeans and their fleet of black ships from making landfall, and, after a siege, destroying the city. The destruction of Troy, as told in the Iliad and the Aeneid, was foretold by Cassandra, the daughter of King Priam and Priestess of Troy.
Cassandra had been given the gift of prophecy by the god Apollo in exchange for her favors. But after the gift was bestowed, she rejected the bright god and, in his rage, he added a curse to her blessing: that no one would ever believe her prophecies.
Thus it was that when her brother Paris set off to Sparta to abduct Helen, she warned him that his actions would lead to the downfall of their great city. He, of course, ignored her.
And you know the rest of the story.
Why am I telling you the story of Cassandra of Troy when we’re supposed to be talking about AI in medicine? Because AI has a major Cassandra problem.
The recent history of AI, and particularly the subset of AI known as machine learning in medicine, has been characterized by an accuracy arms race.
The electronic health record allows for the collection of volumes of data orders of magnitude greater than what we have ever been able to collect before. And all that data can be crunched by various algorithms to make predictions about, well, anything – whether a patient will be transferred to the intensive care unit, whether a GI bleed will need an intervention, whether someone will die in the next year.
Studies in this area tend to rely on retrospective datasets, and as time has gone on, better algorithms and more data have led to better and better predictions. In some simpler cases, machine-learning models have achieved near-perfect accuracy – Cassandra-level accuracy – as in the reading of chest x-rays for pneumonia, for example.
But as Cassandra teaches us, even perfect prediction is useless if no one believes you, if they don’t change their behavior. And this is the central problem of AI in medicine today. Many people are focusing on accuracy of the prediction but have forgotten that high accuracy is just table stakes for an AI model to be useful. It has to not only be accurate, but its use also has to change outcomes for patients. We need to be able to save Troy.
The best way to determine whether an AI model will help patients is to treat a model like we treat a new medication and evaluate it through a randomized trial. That’s what researchers, led by Shannon Walker of Vanderbilt University, Nashville, Tenn., did in a paper appearing in JAMA Network Open.
The model in question was one that predicted venous thromboembolism – blood clots – in hospitalized children. The model took in a variety of data points from the health record: a history of blood clot, history of cancer, presence of a central line, a variety of lab values. And the predictive model was very good – maybe not Cassandra good, but it achieved an AUC of 0.90, which means it had very high accuracy.
But again, accuracy is just table stakes.
The authors deployed the model in the live health record and recorded the results. For half of the kids, that was all that happened; no one actually saw the predictions. For those randomized to the intervention, the hematology team would be notified when the risk for clot was calculated to be greater than 2.5%. The hematology team would then contact the primary team to discuss prophylactic anticoagulation.
This is an elegant approach.
Let’s start with those table stakes – accuracy. The predictions were, by and large, pretty accurate in this trial. Of the 135 kids who developed blood clots, 121 had been flagged by the model in advance. That’s about 90%. The model flagged about 10% of kids who didn’t get a blood clot as well, but that’s not entirely surprising since the threshold for flagging was a 2.5% risk.
Given that the model preidentified almost every kid who would go on to develop a blood clot, it would make sense that kids randomized to the intervention would do better; after all, Cassandra was calling out her warnings.
But those kids didn’t do better. The rate of blood clot was no different between the group that used the accurate prediction model and the group that did not.
Why? Why does the use of an accurate model not necessarily improve outcomes?
First of all, a warning must lead to some change in management. Indeed, the kids in the intervention group were more likely to receive anticoagulation, but barely so. There were lots of reasons for this: physician preference, imminent discharge, active bleeding, and so on.
But let’s take a look at the 77 kids in the intervention arm who developed blood clots, because I think this is an instructive analysis.
Six of them did not meet the 2.5% threshold criteria, a case where the model missed its mark. Again, accuracy is table stakes.
Of the remaining 71, only 16 got a recommendation from the hematologist to start anticoagulation. Why not more? Well, the model identified some of the high-risk kids on the weekend, and it seems that the study team did not contact treatment teams during that time. That may account for about 40% of these cases. The remainder had some contraindication to anticoagulation.
Most tellingly, of the 16 who did get a recommendation to start anticoagulation, the recommendation was followed in only seven patients.
This is the gap between accurate prediction and the ability to change outcomes for patients. A prediction is useless if it is wrong, for sure. But it’s also useless if you don’t tell anyone about it. It’s useless if you tell someone but they can’t do anything about it. And it’s useless if they could do something about it but choose not to.
That’s the gulf that these models need to cross at this point. So, the next time some slick company tells you how accurate their AI model is, ask them if accuracy is really the most important thing. If they say, “Well, yes, of course,” then tell them about Cassandra.
Dr. F. Perry Wilson is associate professor of medicine and public health and director of the Clinical and Translational Research Accelerator at Yale University, New Haven, Conn. He has disclosed no relevant financial relationships.
A version of this article appeared on Medscape.com.
This transcript has been edited for clarity.
Today I’m going to talk to you about a study at the cutting edge of modern medicine, one that uses an artificial intelligence (AI) model to guide care. But before I do, I need to take you back to the late Bronze Age, to a city located on the coast of what is now Turkey.
Troy’s towering walls made it seem unassailable, but that would not stop the Achaeans and their fleet of black ships from making landfall, and, after a siege, destroying the city. The destruction of Troy, as told in the Iliad and the Aeneid, was foretold by Cassandra, the daughter of King Priam and Priestess of Troy.
Cassandra had been given the gift of prophecy by the god Apollo in exchange for her favors. But after the gift was bestowed, she rejected the bright god and, in his rage, he added a curse to her blessing: that no one would ever believe her prophecies.
Thus it was that when her brother Paris set off to Sparta to abduct Helen, she warned him that his actions would lead to the downfall of their great city. He, of course, ignored her.
And you know the rest of the story.
Why am I telling you the story of Cassandra of Troy when we’re supposed to be talking about AI in medicine? Because AI has a major Cassandra problem.
The recent history of AI, and particularly the subset of AI known as machine learning in medicine, has been characterized by an accuracy arms race.
The electronic health record allows for the collection of volumes of data orders of magnitude greater than what we have ever been able to collect before. And all that data can be crunched by various algorithms to make predictions about, well, anything – whether a patient will be transferred to the intensive care unit, whether a GI bleed will need an intervention, whether someone will die in the next year.
Studies in this area tend to rely on retrospective datasets, and as time has gone on, better algorithms and more data have led to better and better predictions. In some simpler cases, machine-learning models have achieved near-perfect accuracy – Cassandra-level accuracy – as in the reading of chest x-rays for pneumonia, for example.
But as Cassandra teaches us, even perfect prediction is useless if no one believes you, if they don’t change their behavior. And this is the central problem of AI in medicine today. Many people are focusing on accuracy of the prediction but have forgotten that high accuracy is just table stakes for an AI model to be useful. It has to not only be accurate, but its use also has to change outcomes for patients. We need to be able to save Troy.
The best way to determine whether an AI model will help patients is to treat a model like we treat a new medication and evaluate it through a randomized trial. That’s what researchers, led by Shannon Walker of Vanderbilt University, Nashville, Tenn., did in a paper appearing in JAMA Network Open.
The model in question was one that predicted venous thromboembolism – blood clots – in hospitalized children. The model took in a variety of data points from the health record: a history of blood clot, history of cancer, presence of a central line, a variety of lab values. And the predictive model was very good – maybe not Cassandra good, but it achieved an AUC of 0.90, which means it had very high accuracy.
But again, accuracy is just table stakes.
The authors deployed the model in the live health record and recorded the results. For half of the kids, that was all that happened; no one actually saw the predictions. For those randomized to the intervention, the hematology team would be notified when the risk for clot was calculated to be greater than 2.5%. The hematology team would then contact the primary team to discuss prophylactic anticoagulation.
This is an elegant approach.
Let’s start with those table stakes – accuracy. The predictions were, by and large, pretty accurate in this trial. Of the 135 kids who developed blood clots, 121 had been flagged by the model in advance. That’s about 90%. The model flagged about 10% of kids who didn’t get a blood clot as well, but that’s not entirely surprising since the threshold for flagging was a 2.5% risk.
Given that the model preidentified almost every kid who would go on to develop a blood clot, it would make sense that kids randomized to the intervention would do better; after all, Cassandra was calling out her warnings.
But those kids didn’t do better. The rate of blood clot was no different between the group that used the accurate prediction model and the group that did not.
Why? Why does the use of an accurate model not necessarily improve outcomes?
First of all, a warning must lead to some change in management. Indeed, the kids in the intervention group were more likely to receive anticoagulation, but barely so. There were lots of reasons for this: physician preference, imminent discharge, active bleeding, and so on.
But let’s take a look at the 77 kids in the intervention arm who developed blood clots, because I think this is an instructive analysis.
Six of them did not meet the 2.5% threshold criteria, a case where the model missed its mark. Again, accuracy is table stakes.
Of the remaining 71, only 16 got a recommendation from the hematologist to start anticoagulation. Why not more? Well, the model identified some of the high-risk kids on the weekend, and it seems that the study team did not contact treatment teams during that time. That may account for about 40% of these cases. The remainder had some contraindication to anticoagulation.
Most tellingly, of the 16 who did get a recommendation to start anticoagulation, the recommendation was followed in only seven patients.
This is the gap between accurate prediction and the ability to change outcomes for patients. A prediction is useless if it is wrong, for sure. But it’s also useless if you don’t tell anyone about it. It’s useless if you tell someone but they can’t do anything about it. And it’s useless if they could do something about it but choose not to.
That’s the gulf that these models need to cross at this point. So, the next time some slick company tells you how accurate their AI model is, ask them if accuracy is really the most important thing. If they say, “Well, yes, of course,” then tell them about Cassandra.
Dr. F. Perry Wilson is associate professor of medicine and public health and director of the Clinical and Translational Research Accelerator at Yale University, New Haven, Conn. He has disclosed no relevant financial relationships.
A version of this article appeared on Medscape.com.